-
[스압/데이터주의] 웹 최적화 방식 모음 - 5. 빌드프로그래밍/Web 2021. 3. 5. 12:32
- [스압/데이터주의] 웹 최적화 방식 모음 - 0. 전반적 원칙과 원리
- [스압/데이터주의] 웹 최적화 방식 모음 - 1. 다운로드
- [스압/데이터주의] 웹 최적화 방식 모음 - 2. 파싱 및 렌더링 트리
- [스압/데이터주의] 웹 최적화 방식 모음 - 3. Layout 및 렌더링
- [스압/데이터주의] 웹 최적화 방식 모음 - 3.3 UX 트릭
- [스압/데이터주의] 웹 최적화 방식 모음 - 4. 로드 후
- [스압/데이터주의] 웹 최적화 방식 모음 - 5. 빌드(현재)
5. 빌드
빌드 성능 최적화를 앞서, 우리가 사용하고 있는 툴들의 종류가 무엇이 있는지 생각해보자.
- 로컬에서 자바스크립트 코드 자체를 실행하기 위한 Node.js
- 패키지 설치와 의존성 관리를 위한 NPM
- 모노레포 관리를 위한 Lerna
- 자바스크립트를 정적으로 만들기 위한 Typescript
- 트랜스파일링이나 컴파일을 위한 Babel
- 코드 퀄리티를 위한 ESLint
- 코드 스타일을 위한 Prettier
- 모듈 번들링을 위한 Webpack
- 모듈 테스트를 위한 Jest
- E2E 테스트를 위한 Cypress
- 컴포넌트 개발과 문서화를 위한 Storybook
- CI/CD를 위한 Github Action
등등등..
그야말로 툴들의 전성시대라 말해도 과언이 아니다.
이 글에서는 툴들의 필요성과 역사, 최신 툴들의 이점에 대해 탐색해보도록 한다.
특히 규모가 클수록 빌드 타임을 줄여 생산성 측면에서 많은 이득을 얻을 수 있다.
cargo로 패키지, 워크스페이스, 빌드. 테스트 다해먹고 rustfmt와 rust-clippy만 써도되는 러스트 생태계가 부럽다..
5.1 패키지 설치와 의존성
개요
- An abbreviated history of JavaScript package managers
- JavaScript package managers compared: npm, Yarn, or pnpm?
- node_modules로부터 우리를 구원해 줄 Yarn Berry
- 자바스크립트 의존성 관리자(npm, yarn, pnpm)에서 보다 더 의존성 관리 잘하는 방법
초반에 Npm이 만들어진 이유는 글로벌이 아닌 로컬 패키지를 사용, 패키지 버전관리, 중첩된 패키지 관리등을 위해서였다.
전역(글로벌) 패키지를 사용할 경우 일반적으로 한가지 버전만 설치가 가능하며, 이에 비롯되는 문제들이 많다.
예를 들어 여러 패키지가 한 공통 패키지를 참조할 때 공통패키지에서 브레이킹 체인지가 발생한다면 어떻게 할 것인가?
아치 리눅스의 경우 항상 최신의 버전을 유지하도록 한다.
그럼 업데이트가 안되는 패키지는 깨지고, 사용이 불가능해진다.
또한 최신 패키지에 버그가 있거나 동작 불가, 악의적 동작이 삽입될 경우 문제가 생길 수 있다. [Colors.js / Faker.js 개발자가 무한루프 코드를 삽입하고, Repo의 코드를 모두 지움, colors.js와 faker.js 사태가 준 교훈]
때문에 core, extra, community, aur등으로 품질요구와 신뢰성에 따라 레포지토리를 나누어놓았지만 완벽한 해결책은 아니다.
이를 해결하는 가장 간단한 방법은 각 버전의 패키지를 모두 설치하는 것이다.
순수함수형 패키지 매니저인 nix가 작동하는 방식으로 /nix/store/b6gvzjyb2pg0kjfwrjmg1vfhh54ad73z-firefox-33.1/처럼 패키지 고유 식별자를 부여하여 여러가지 버전과 변형을 각각 설치하도록 격리하며 재현성을 가지도록 만들수 있다.
단점은 아주 작은 패치가 있어도 각각의 빌드를 모두 설치해야 하므로 디스크 공간의 낭비가 심하다.

Setting Up Automated Semantic Versioning For Your NodeJS Project, What's the difference between tilde(~) and caret(^) in package.json?
Npm은 몇가지 제한으로 꽤 현명하게 동작한다.
- 로컬 패키지
프로젝트 별로 필요한 버전의 패키지를 달리 설치할 수 있으며, ./node_modules에 위치하므로 제거도 간편하다. - 중첩된 종속성구조
서로 다른 버전의 하위 종속성을 가지고 있을시 중첩적으로 존재하여 여러가지 버전을 가짐 - SemVer와 업데이트
SemVer(Semantic Versioning)을 사용함으로서 브레이킹 체인지, 기능 추가, 버그수정를 나눌 수 있게 되었고, 업데이트할 패키지 버전범위를 제어할 수 있게되었다.
특히 틸트(~)와 캐럿(^)을 이용한 방식은 아이디어가 좋다. [npm package.json에서 틸드(~) 대신 캐럿(^) 사용하기]
중첩된 종속성 구조의 경우, 윈도우의 파일 경로 길이 제한등 때문에 호이스팅을 통해 종속성 트리를 평평하게 만들었다.
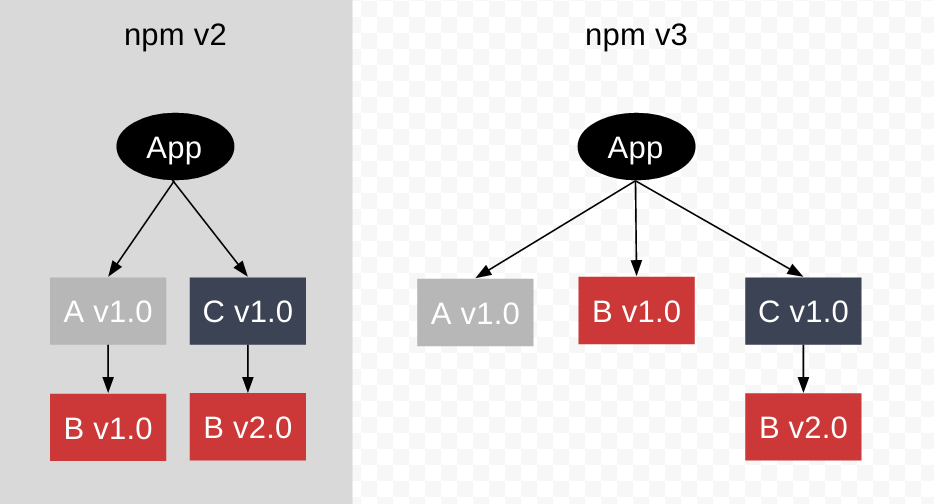
종속성 트리를 평면화하면 똑같은 버전의 패키지는 여러번 설치할 필요가 없었으므로 디스크공간과 설치 시간 절약에 도움이 되었다.
yarn(v1)은 성능과 정확한 버전이 명시된 의존성 파일로 주목을 받았으며, Npm v5에도 비슷한 기능이 적용되었다.
- 다운로드한 패키지를 캐시에 저장후 복사
- yarn.lock이란 락파일 제공
그러나 node_modules와 관련된 문제는 많았다.
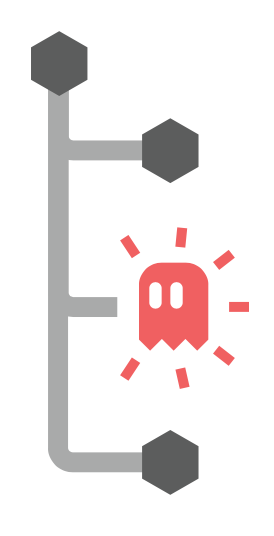
유령종속성 특히 호이스팅과 관련된 문제가 많았는데
- 직접 설치하지 않은 패키지에 접근이 가능
- 종속성 트리 병합 알고리즘이 복잡
- 일부 패키지는 여전히 flatten 되지 않고 중첩적으로 존재
Pnpm은 심볼릭 링크와 하드 링크를 이용해 동작한다. [Why should we use pnpm?]

- 링크를 사용하므로, 캐시로부터 복사하는 yarn(v1)보다 빠르며 디스크 공간이 절약
- 각 패키지는 고유한 종속성을 가지지만, 평평하게 유지된 패키지로 링크하여 경로 길이 해결
- node_modules에 유령 종속성이 없도록 깔끔하게 유지
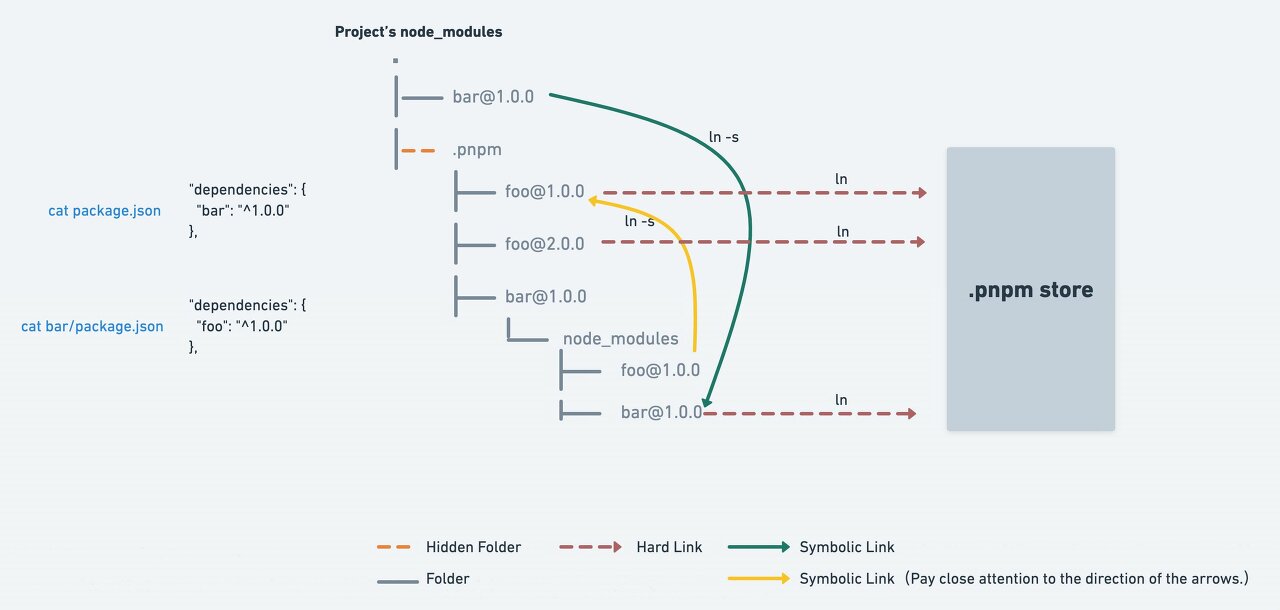
그러나 링크를 사용하면 호환성 관련 문제가 있을수도 있다. [1, 2]
- 운영체제와 파일시스템에 따라 다름
- watching의 동작
- 재귀 관련 오류
- 다른 툴들과의 호환성
yarn (v2, berry)는 node_modules의 호이스팅 문제를 해결하고, 의존성 탐색과 용량문제를 해결하기 위해

pnp(Plug'n'Play)와 ZipFS(Zip Filesystem)을 도입했다.

.pnp.cjs 파일에 의존성 관련 모든 정보를 기술하여 node_modules 탐색을 하지 않고 직접 접근할 수 있다.
- 의존성 검색을 따로하지 않기에 빠름
- node_moudules에서 찾지못하면 상위 디렉토리의 node_modules에서 검색하여 의존성을 찾는 일이 없기 때문에 동일한 재현성을 보장
역시 단점이 존재하며 대부분의 문제는 호환성.
- yarn node라는 명령어를 사용해야 하며, 아래에서 나올 nx나 turborepo 같은 경우 동작하지 않는 등의 문제
- 각 에디터에는 SDK가 필요하다.
- eslint의 사용이나 쉘 스크립트로 된 bin등의 호환성 문제
ZipFS는 설치 용량을 획기적으로 줄여주며(400MB -> 120MB) 구성파일이 적어 변경 감지와 의존성 제거 작업이 빠르다.
때문에 모든 설치 파일을 git에 포함하는 zero install 전략을 사용할 수 있게 되었다.
해결방안
개인적으로 yarn이 마음에 든다.
ZipFS로 Zero-Install, v3.1에서 Pnpm 같은 설치모드 지원과 Conditional Package, 추후 적을 Workspace 등등의 기능들을 잘 묶어서 전달한다.
아직 pnp를 그대로 사용하기에는 호환성 문제가 많아서, zero-install + pnpm 모드로 사용해보는게 어떨까 싶다.
라는 글이 비교적 마음에 들게 써졌다.
5.2 모노레포
개요
거대한 앱이 있다고 생각해보자.
모놀리딕하게 모두 하나의 프로젝트로 구성된다면 설계, 배포 등을 커다란 단위로 처리해야 해서 비효율적이다.
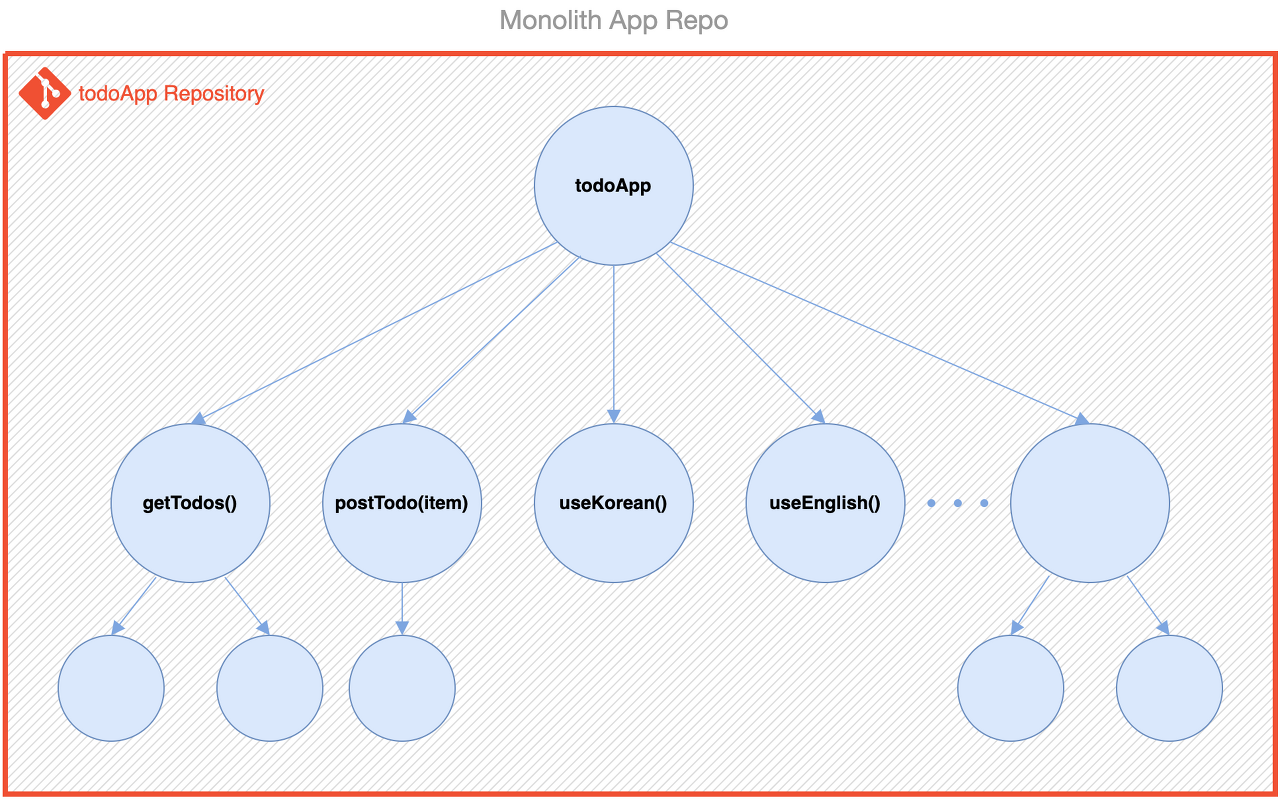
따라서 거대한 프로그램은 모듈화를 하게된다.
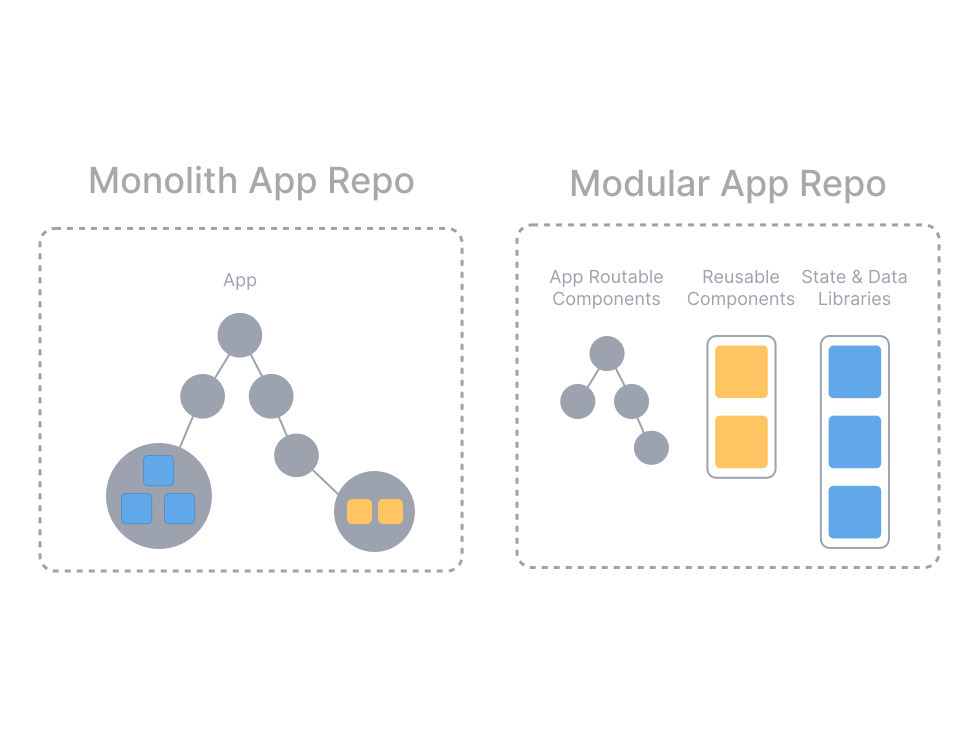
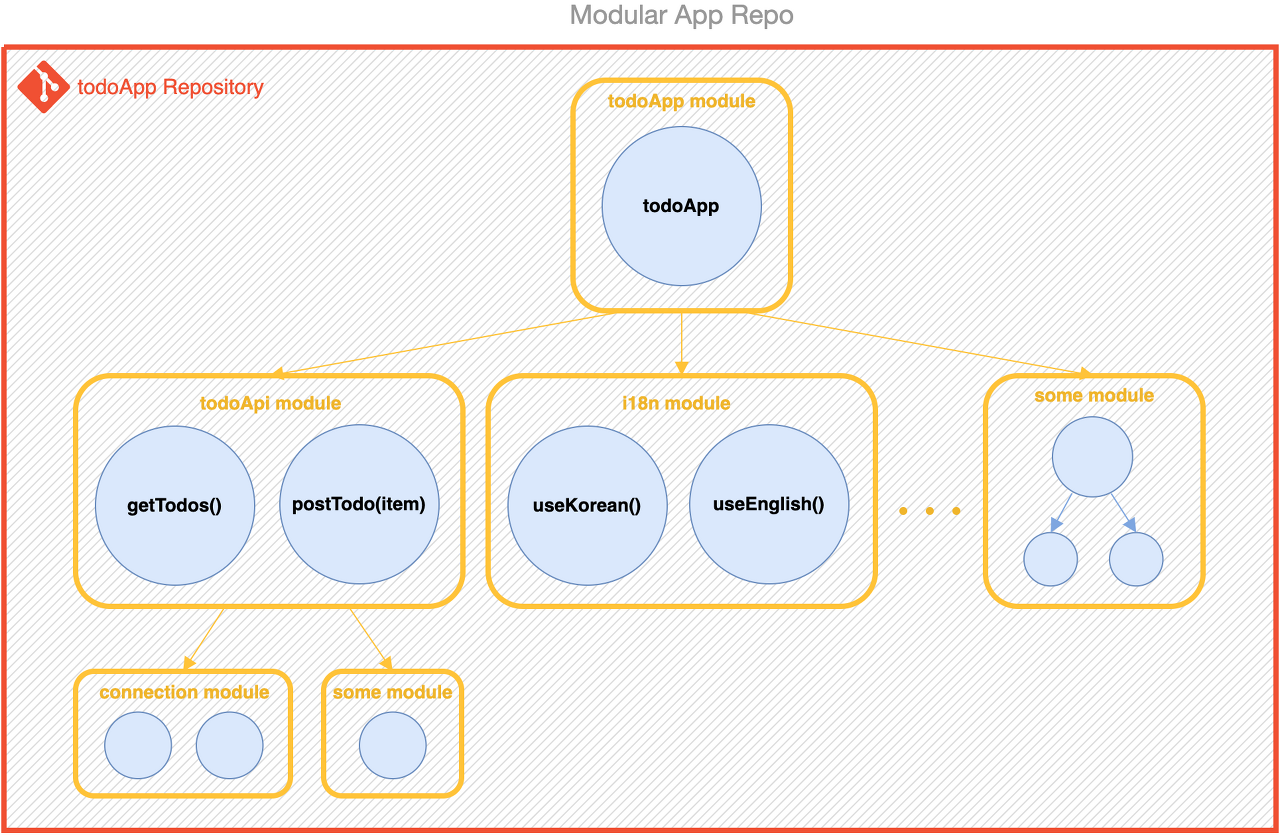
자, 그럼 모듈의 위치를 어디에 두어야할지 생각해봐야한다.
각 모듈 당 레포를 하나씩 만들게되면 멀티레포(또는 폴리레포) 구조가 된다.
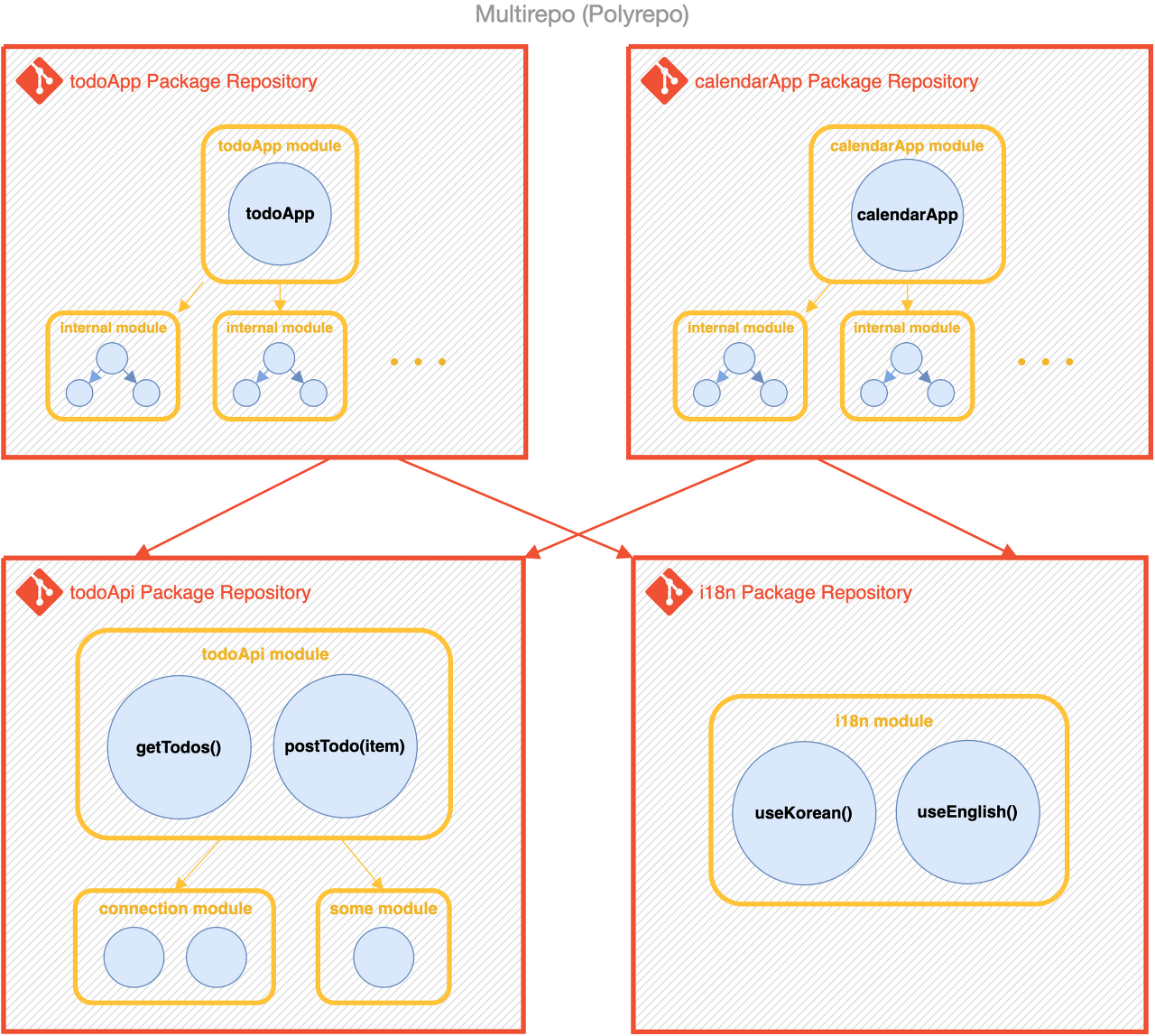
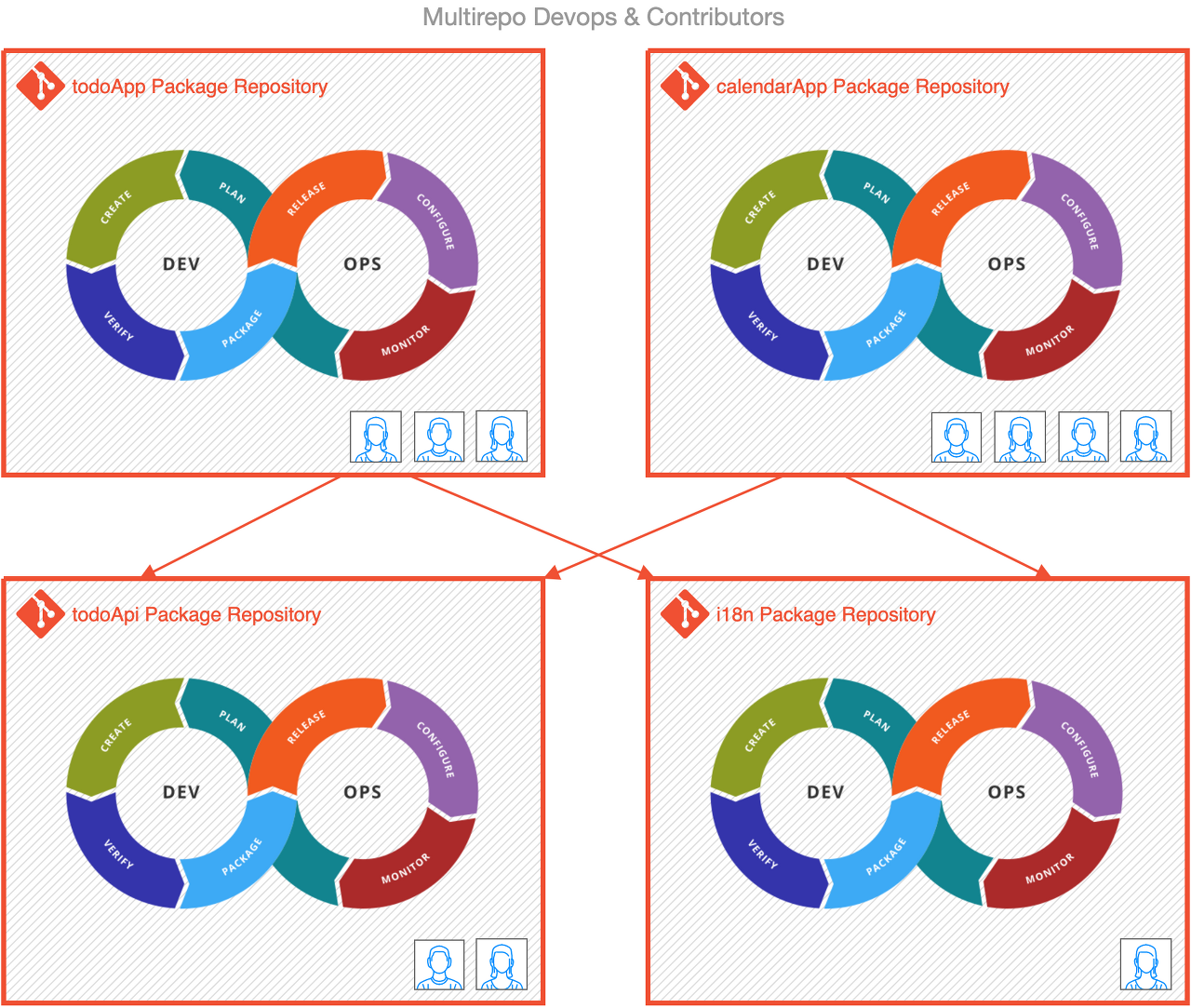
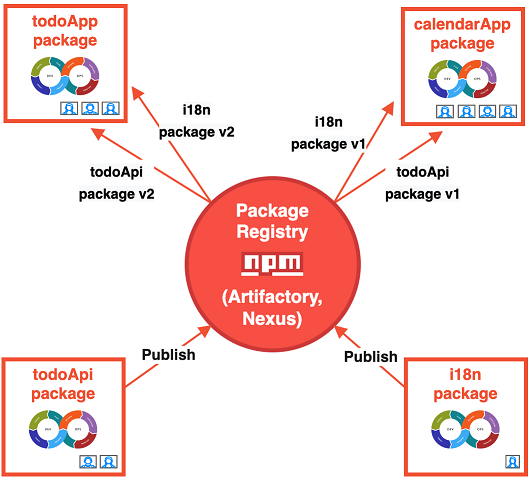
레포를 여러개 만들게되면 독립성은 생기지만, 각각 테스트와 배포등을 모두 설정해줘야 하고 다른 패키지의 변경사항이 생기면 매번 업데이트 해줘야한다.
따라서 모노레포를 이용해 각 모듈을 한꺼번에 관리하는 개념이 나오기도 했다.
응집도를 높일 필요가 있는 프로젝트일 경우 사용하는게 좋다.
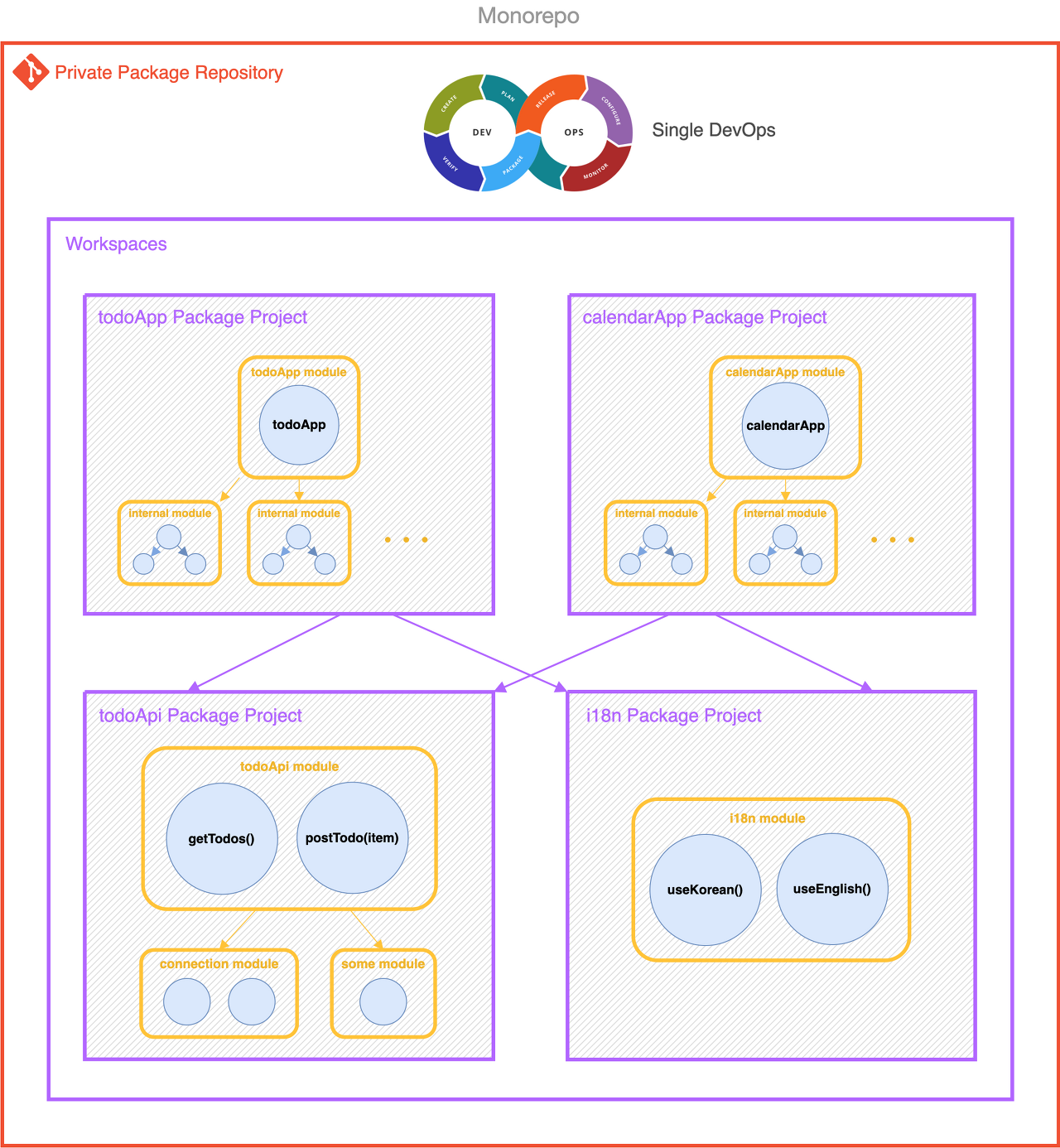
요약해서
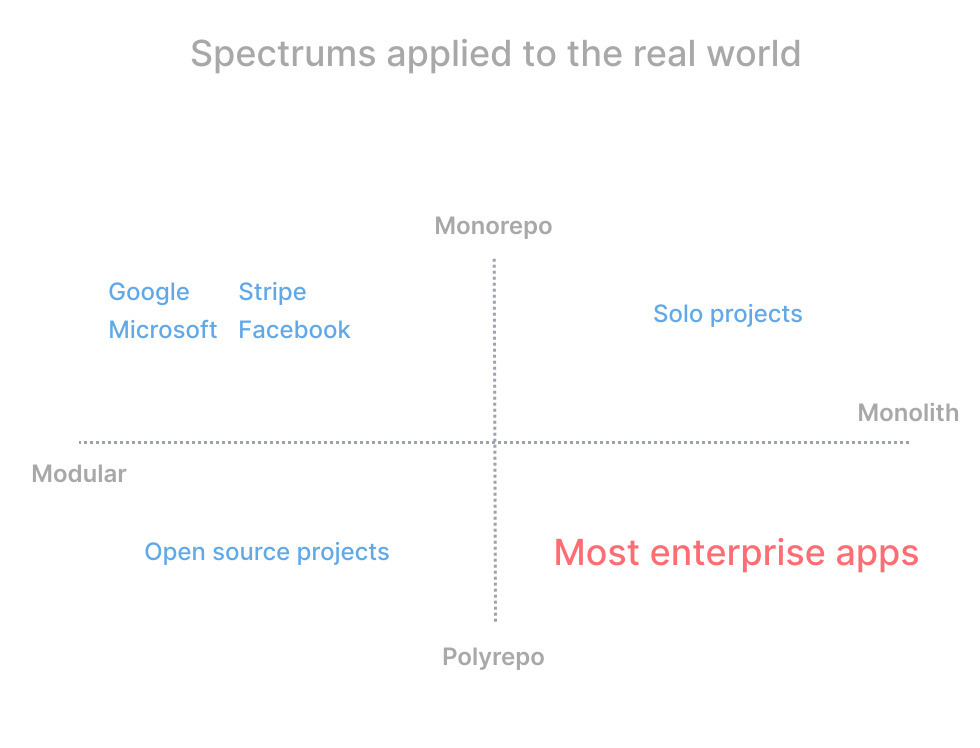
- 모듈화 <-> 모놀리딕
- 모노레포 <-> 멀티레포(또는 polyrepo)
의 개념으로 생각합시다.
해결방안
Lerna는 Nrwl(Nx 팀)이 인수한 상태이며 기능과 성능은 Nx, Turborepo가 좋은 편이다.
- How we reduced our nodejs monorepo build time by 70%
- Benchmarks of JavaScript Package Managers
- Nx vs Turborepo
- Why TurboRepo Will Be The First Big Trend of 2022
Nx는 기능이 많고 통합이 잘되어 있지만 상대적으로 설정이 까다로운 편이다.
약간 더 설정이 간단한 Vercel의 Turborepo과 비교하여 필요한 것을 도입하자.
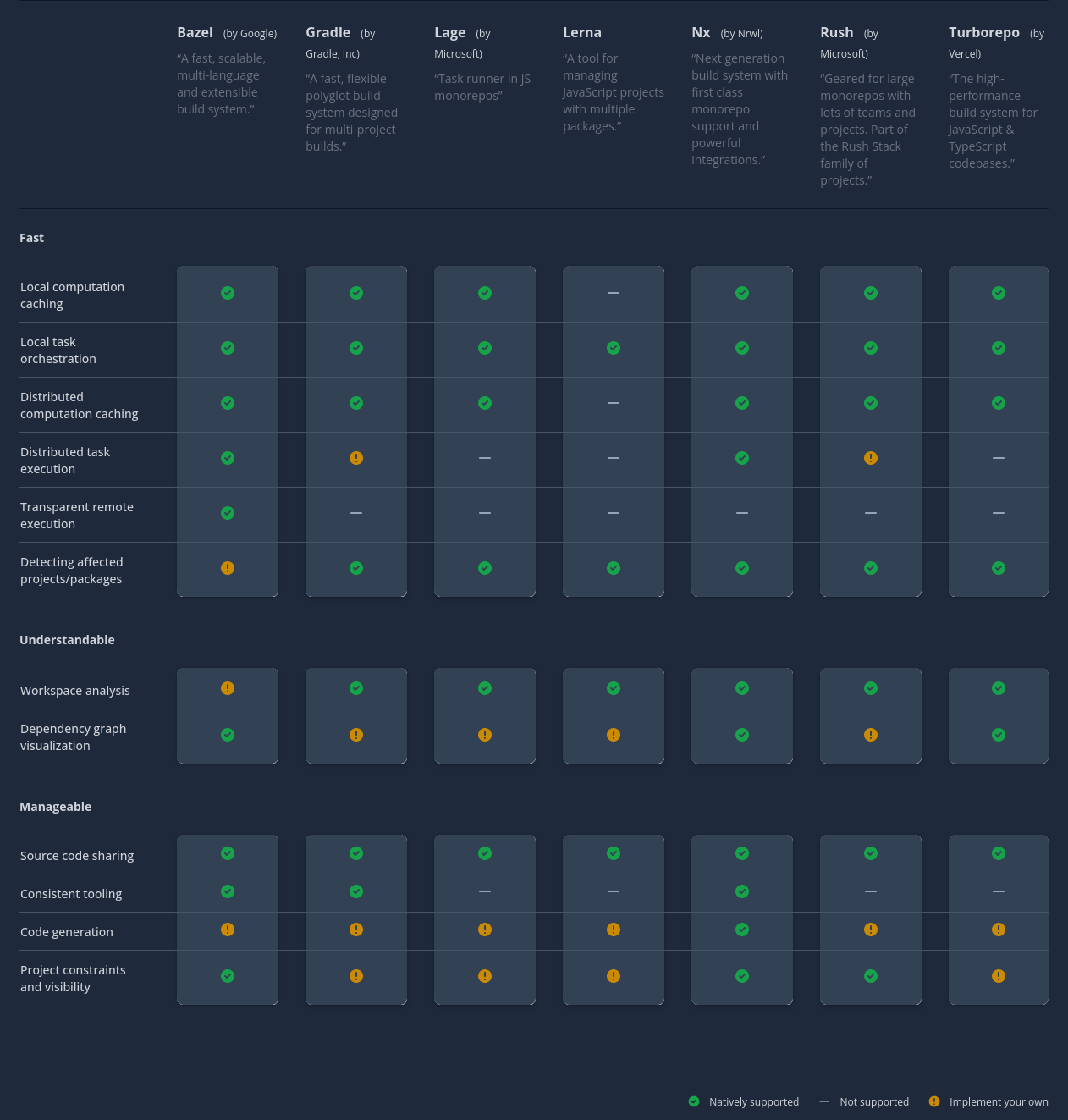
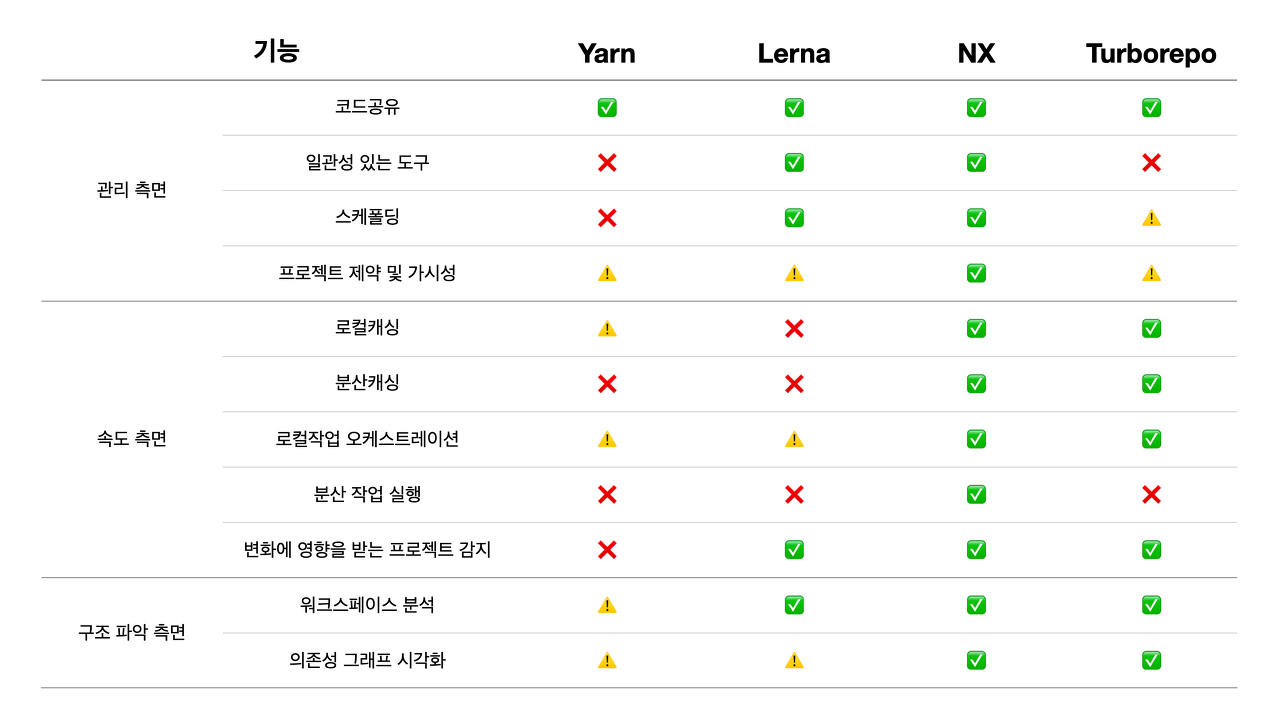
앞서 말했지만 아직 모노레포 툴들이 yarn pnp를 제대로 지원하지 않고 있다.
5.3 트랜스파일링과 컴파일
개요

자바스크립트는 크로스플랫폼에서 동작하는 가장 간단한 언어 중 하나라 타겟으로하는 언어들이 많다.
역시 컴파일러가 필요하다.
가 대표적인 예라 볼 수 있다.
그러나 구형 브라우저를 타겟으로 최신 ESNext 문법을 사용하거나 JSX같은 언어적 확장을 사용하기 위해서도 트랜스파일링(또는 컴파일)과정이 필요하다.
그래서 보통 사용되는 것이 바벨(Babel).
해결방안
그렇지만 컴파일 시 느리다는 말들이 정말 많다.
첫번째 방안은, 타입스크립트나 flow를 사용한다면 컴파일시 타입정보들을 모두 제거하고 한번에 처리하는 것이다.
타입체크는 tsc를 이용해 따로 진행하도록 하자.
- Is babel still relevant for TypeScript projects ?
- 바벨과 타입스크립트의 아름다운 결혼
- Using Babel with TypeScript
- TypeScript-Babel-Starter
그리고 babel보다 빠르게 컴파일되는게 있으니, 바로 swc다.
러스트로 만들어졌고, 멀티코어를 활용하며 타입스크립트의 경우 babel처럼 타입정보를 제거하며 동작한다.
아직 플러그인이 적지만, 고려해볼만 하다.
타입체커의 경우 stc라는 이름인데 아직 준비중이라는 듯.
5.4 번들링과 태스크 러너
개요
Webpack같은 모듈 번들러가 왜 필요할까?
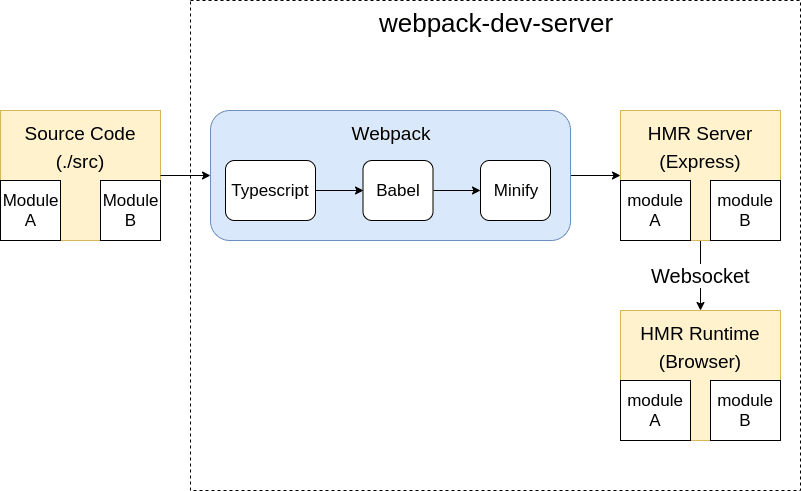
이외에도 css, image같은 각종 리소스 관리, HMR(Hot Module Replacement) 개발서버 등도 지원하기도 한다.
우선 모듈은 무엇이고 번들링과 태스크 러너란 무엇인가.
모듈은 웹 애플리케이션을 구성하는 모든 자원을 의미한다.
단순히 Javascript만을 뜻하는게 아니라 HTML, CSS, Javascript, 이미지, 폰트등 모든 파일들 각각은 모두 모듈이다.
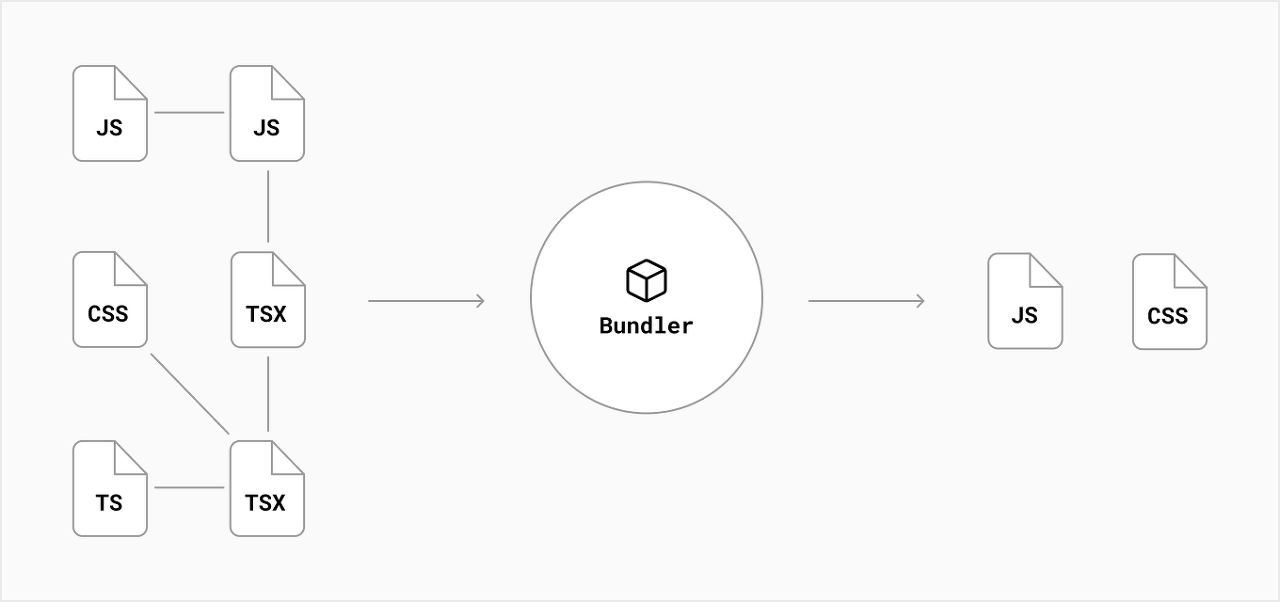
그러나 매번 각각의 모듈을 호출하는 것은 비효율적이다.
특히 HTTP/1에서 호출 제한이 있었으며, HTTP/2에서도 이미지 스프라이트 이점이 있던 점을 떠올려보자.
따라서 우리는 단순히 컴파일을 넘어 번들링까지 필요하다.
번들러는 각각의 모듈들을 조합해서 병합된 하나의 결과물을 만드는 도구를 의미한다.
이때 태스크 러너와 많이 비교되기도 한다.
왜냐. 대표적인 태스크 러너는 Make인데 우리는 빌드를 할 때 사용한다는 점을 알고 있다.
웹 생태계에서는 Grunt, Gulp가 대표적인 태스크러너이며 역시 빌드용으로 많이 사용되었다.
이제 슬슬 혼동이 오기 시작한다.
Webpack에서 webpack --mode=production로 프로덕션용 빌드를 하고, webpack --mode=development로 개발용 빌드를 하지 않던가?
태스크 러너는 모든 작업을 우리가 순차적으로 지정해줘야 하지만, 번들러는 엔트리와 플러그인을 지정해주면 종속성을 파악해 한번에 실행된다는 점에서 차이가 있다.
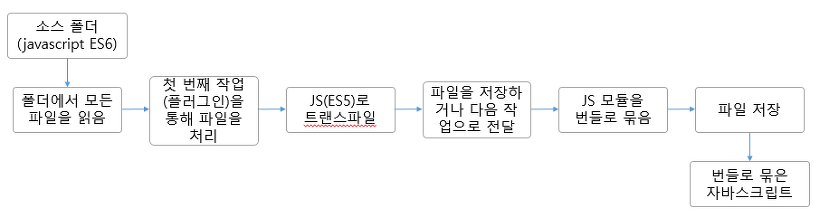
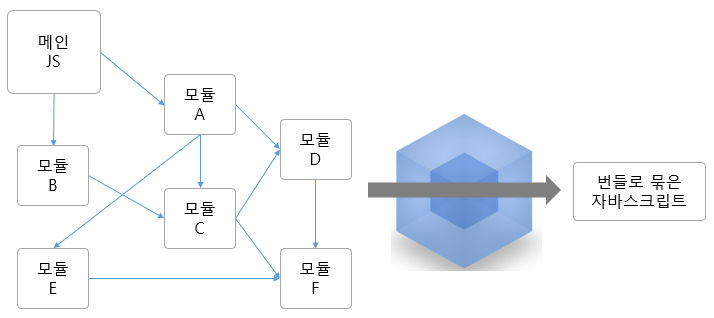
웹팩(Webpack) 이란, 웹팩 간단 정리 및 리액트(React) 기본 개발환경 세팅., Webpack or Browserify & Gulp: Which Is Better?
게다가 종속성 분석이 가능해짐으로서 단순히 파일을 merge하는 것보다 빠르고 Tree Shaking, Code Splitting, Dynamic Import(Lazy loading)등을 처리하며 심지어 Dev server와 연동하여 HMR(Hot Module Replacement)까지 제공한다.

성능차이 
Using Webpack for API development!
이쯤되면 "아~ 번들러가 태스크러너의 상위의 존재?구나"라는 생각이 들 수도 있다.
그러나 Webpack의 Integrations 문서에도 나오듯 잘하는 일이 다른 것 뿐이며 태스크러너는 packages.json의 scripts에 가깝다.
앞서 태스크러너의 예로 나온 makefile이 install과 clean은 수행해도 lint나 test 명령이 쓰이기도 하나 싶지만 실제로 오라클 가이드에서도 소개되며 린트, 테스팅등을 하는 용도로 쓰이는 한다.
- Makefiles: Part 3 — Test, Lint, Deploy!
- Speed up your Python development workflow with pre-commit and Makefile [뱅크샐러드의 예시]
물론 린트와 테스팅 도구들이 번들러와 통합하여 쓰이는 경우들이 잦아져 쓸 필요가 줄어들고 있다.
그치만 복잡한 publishing등의 작업들이 필요하다면 태스크러너를 사용하는게 유용할 수도 있다.
단, 모노레포에서 태스크 러너는 위에 나온 모노레포 관리 도구들에 의해 상당히 대체 가능하다고 생각한다.
아직도 혼동이 오나요?
번들러는 Gulp 기준 src()~dest()를 효율적으로 실행해주는 프로그램입니다.
웹팩에서 src()는 Entry, dest()는 Output이죠.
로더, 플러그인, 모드는 뭐냐고요?
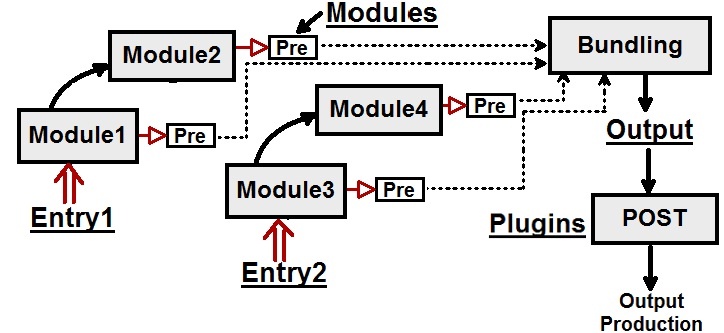

Where can I learn webpack?, Webpack loaders vs plugins; what's the difference?
로더는 로드할 각각의 파일 수준에서 작동합니다.
플러그인은 번들링 수준에서 작동합니다.
How to set up WebPack based TypeScript Electron React Build Process (with VSTS CI!)
모드는 설정을 하기위한 매개변수이라 단순히 생각합시다.
여기서!! 번들러가 자바스크립트의 모듈을 분석한다고 했었죠.
그런데 자바스크립트의 모듈 시스템은 통일성이 없고 매우 다양하다.
본디 브라우저에서 script 태그로 로드를 하는 형식이었지만, 전역 컨텍스트에서 로드하여 이름이 겹쳐 재정의되는등의 문제가 있었다.
<html> <script src="/src/foo.js"></script> <script src="/src/bar.js"></script> <script src="/src/baz.js"></script> <script src="/src/qux.js"></script> <script src="/src/quux.js"></script> </html>그래서 나온것들이 자바스크립트의 모듈들이다.
Common.JS는 서버 사이드에서 사용하기 위해 나타났으며 Node.JS의 기본 모듈 시스템이기도 하다.
한계로는 동적이라서 트리쉐이킹에 취약했으며 비동기적으로 사용이 어려웠다. [CommonJS가 번들을 더 크게 만드는 방법]
밑에 나올 Rollup은 CommonJS가 아닌 ESM을 사용하여 빌드하므로, 트리쉐이킹에 강점이 있다.
// == Default 모듈 ================================ // Default 모듈 정의, foo.js const foo = () => console.log(0); module.exports = foo; // Default 모듈 사용 const foo = require("./foo"); foo(); // == 모듈 ======================================== // 모듈 정의, bar.js const baz = () => console.log(1); module.exports = { baz }; // 모듈 사용 const barModule = require("./bar"); barModule.baz(); const { baz } = require("./bar"); baz();AMD(Asynchronous Module Definition)은 비동기적으로 모듈을 로드하기 위한 시스템이다.
브라우저에서 모듈을 로드할때 스크립트 태그로 로드하면 로딩이 완료될 때까지 브라우저가 프리징 되었기 때문에 비동기적으로 로드하려는 노력이었다.
AMD 로더 중 가장 유명한게 require.js.
// 모듈 정의, foo.js define({ foo: () => console.log(0) }); // 모듈 정의, qux.js define(['foo', 'bar', // 의존 모듈들을 배열로 나열 ], function (foo, bar) { // 의존 모듈들은 순서대로 매개변수에 담김 return { // 외부에 노출할 함수들만 반환 foo, barModule: bar }; }); // 모듈 사용 require(['qux.js', // 사용할 모듈 배열로 나열 ], function (quxModule) { // 사용할 모듈들이 순서대로 매개변수에 담김 quxModule.foo(); quxModule.barModule.baz(); });UMD(Universal Module Definition)은 CommonJS와 AMD를 모두 지원하기 위해 나온 디자인 패턴이다.
Webpack이나 Rollup같은 번들러에서 ESM을 지원하지 않는 브라우저라면 fallback 용으로 사용하기도 한다.
(function (root, factory) { if (typeof define === 'function' && define.amd) { // AMD 방식 define(['exports', 'foo'], factory); } else if (typeof exports === 'object') { // CommonJS 방식 module.exports = factory(require('foo')); } else { // Browser globals root.foo = factory(root.foo); } }(this, function (foo) { //use foo in some fashion. // 모듈 정의 const foo = () => console.log(0); return foo; }));그리고 마침내 ESM이 나왔다!!
드디어 언어자체에서 모듈시스템을 지원한다.
동기/비동기를 모두 지원하고, 순환참조 문제가 없으며 정적분석까지도 가능하다.
// == Default 모듈 ================================ // Default 모듈 정의, foo.js const foo = () => console.log(0); export default foo; // Default 모듈 사용 import foo from "foo"; foo(); // == 모듈 ======================================== // 모듈 정의, bar.js export const baz = () => console.log(1); // 모듈 사용 import { baz } from "bar"; baz();이외 사양으로 Javascript Code Module이라고 파이어폭스 내부에서 사용하는 모듈 시스템이 있다.
권한이 있는 다른 범위의 자바스크립트에서 코드를 공유하기 위해 만들어졌다.
// == JSM 모듈 =================================== // Default 모듈 정의, foo.jsm var EXPORTED_SYMBOLS = ["foo"]; const foo = () => console.log(0); // Default 모듈 사용 Components.utils.import("resource://app/foo.jsm"); foo(); // == CommonJS =================================== // 모듈 사용 const { require } = Cu.import("resource://gre/modules/commonjs/toolkit/require.js", {}); const { baz } = require("./bar"); baz();해결방안
Browserify를 누르고 올라온 Webpack이 한동안 Defacto Standandard였지만 춘추전국시대로 난립중이다.


- JavaScript Bundlers: An in-depth comparative 👍👎 Is Webpack still the best bundler in 2021? 📦
- Bundle(3) - Module Bundler
- 번들러 비교
- 차세대 빌드 도구 비교
기존에 주로 쓰이던 것은 Webpack, Rollup, Parcel이며, 빠른 빌드로 유명한 esbuild도 주목할만 하다.
Webpack은 이 글을 쓰는 시점 기준, 널리 쓰이다보니 안정적이며 로더와 플러그인들이 많다.
Rollup은 ESM을 기준으로 빌드하여 트리쉐이킹에 강점이 있다. 단, dev sever등의 기능들이 부족.
Parcel은 제로 config를 지향하여 세팅이 쉽다. 대신 커스텀 설정이 어려울 수 있다.
Esbuild는 Go 언어로 짜여졌으며, 병렬처리를 사용하여 빠른 빌드를 자랑한다.
그리고 차세대 도구로 부상하는 Snowpack, Vite, wmr.
이들은 번들링 자체보다는 개발서버의 역할과 빠른 개발 빌드로 주목받는다.
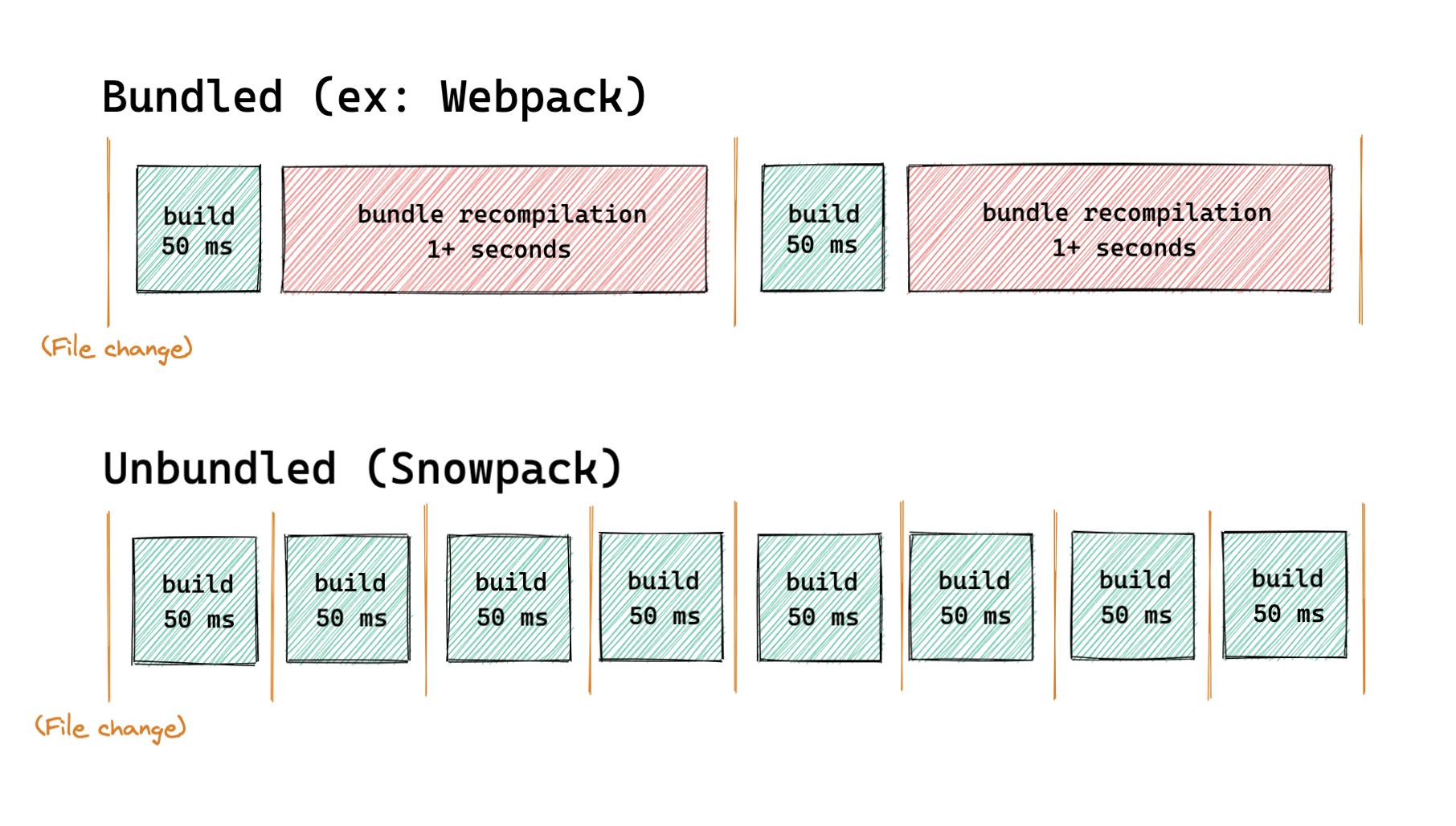
브라우저에서도 ESM을 지원함에 따라 매번 번들링을 수행할 필요가 없어졌다.
CommonJS는 브라우저에서 지원하지 않아 번들링이 필요했었죠?
게다가 Snowpack은 NPM의 CommonJS 패키지들을 개별 JS 파일로 변환 후, 브라우저에서 ESM Import를 사용하여 가져오게 한다. (사전 번들링)
Vite의 접근도 비슷하다.
소스코드는 Native ESM을 사용하고, NPM 패키지들은 Esbuild로 사전 번들링을 수행한다.
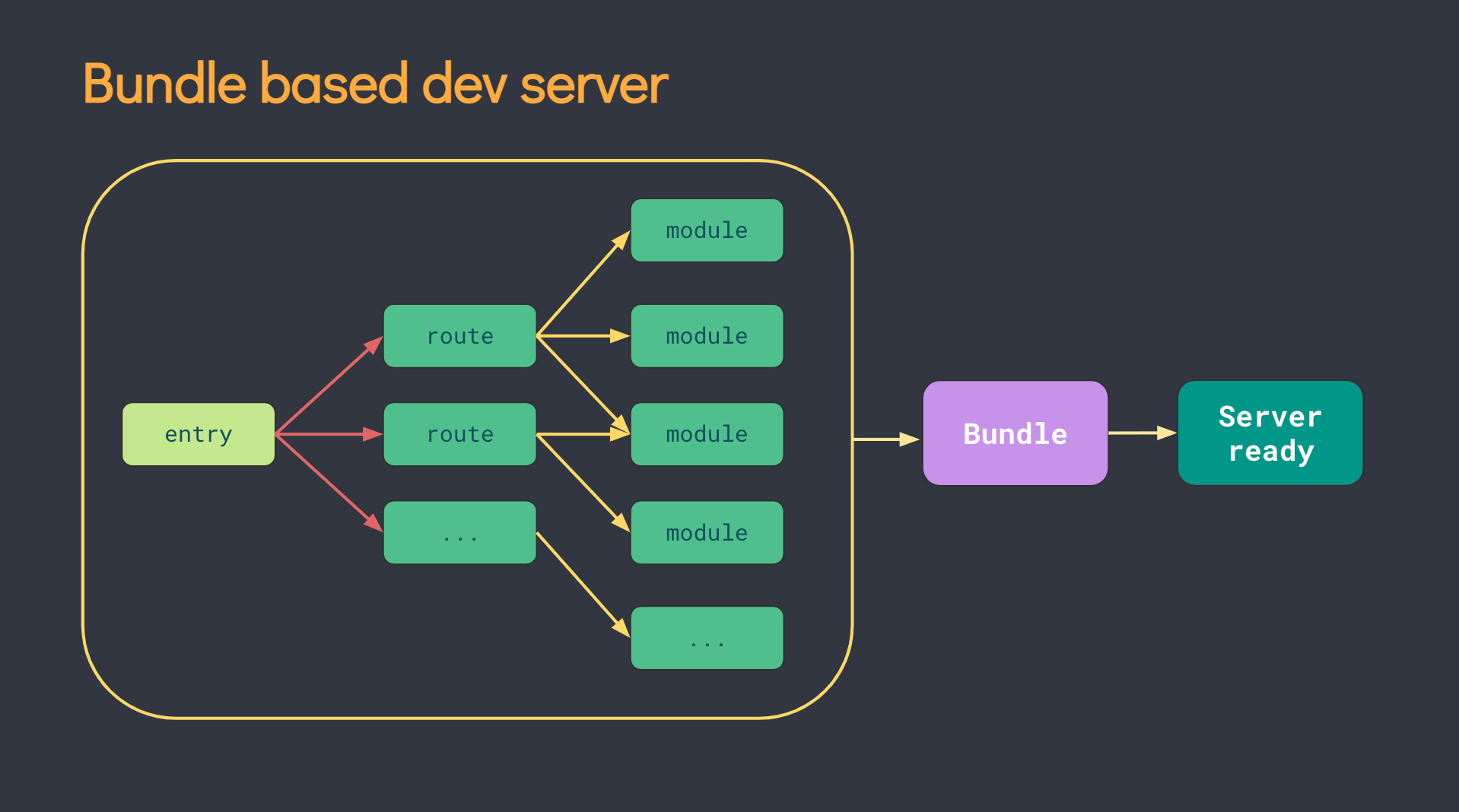
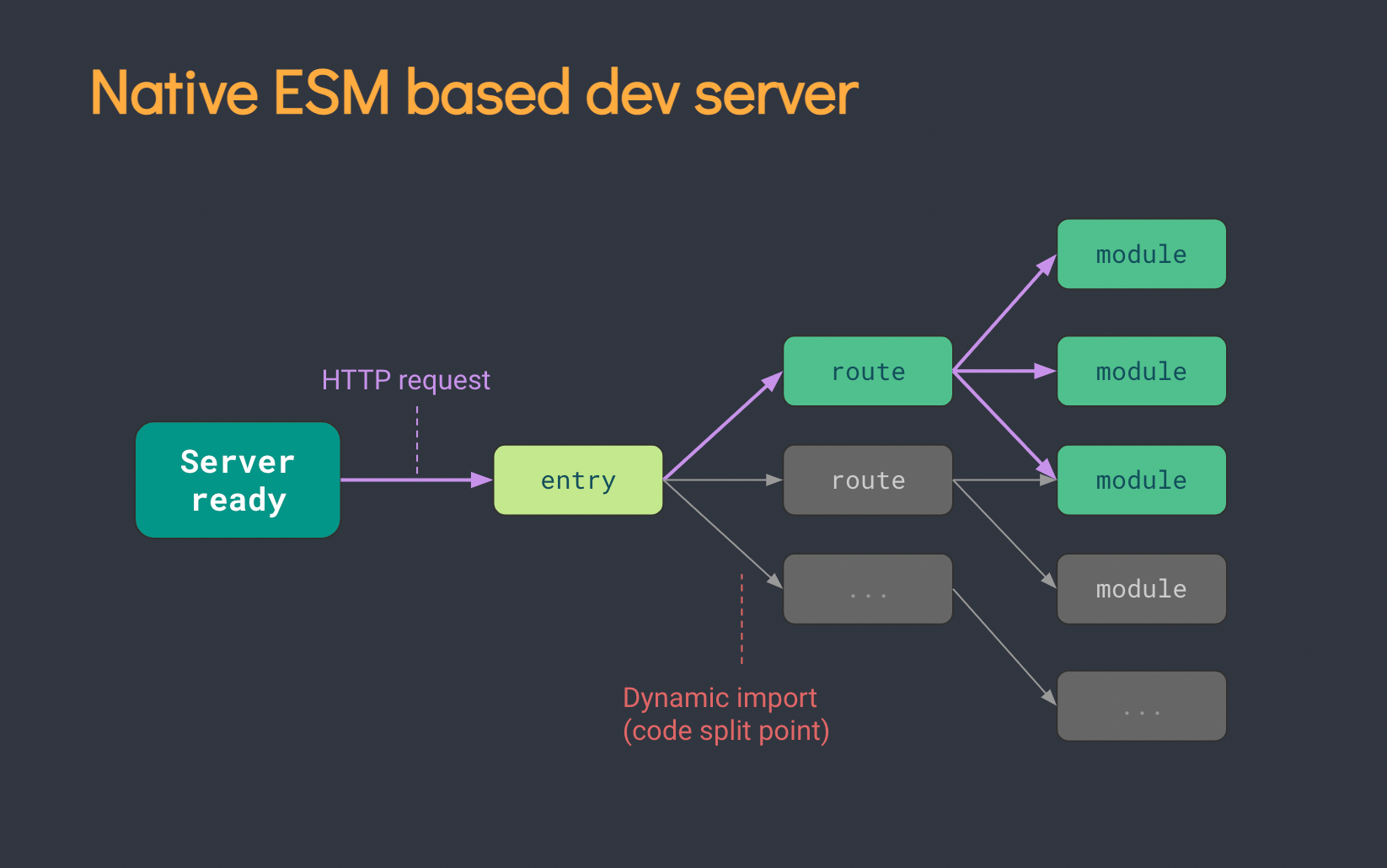
Snowpack이 개발용에만 신경썼던 한편, Vite는 프로덕션 빌드에는 Rollup을 사용해 최적화했고 전반적인 통합을 높혔다.
독단적인 결정일 수 있지만 나는 꽤나 합리적인 기본값이라 생각하며, 그 결과 Multi-Page App이나 라이브러리 모드등의 다양한 기능들을 제공한다.
단, Vite는 Snowpack과 wmr의 Streaming Import를 아직 지원하지 않는다.
Streaming Import는 Native ESM을 최대한 활용하기 위해 Skypack같이 ESM 패키지를 제공하는 CDN에서 직접 로드하여 성능을 높힐 수 있다.(사전 번들링 불필요)
wmr은 preact에 중점을 둔 작은 번들러로, 프로덕션 빌드 최적화나 Streaming Import를 지원한다.
또한 HTM을 사용해 소스맵에 의존하지 않고도 디버그 정보를 잘 표현해준다.
암튼 최근 경향은 Vite가 대세로
를 읽어보자.
아, 그리고 직접 모노레포를 yarn & vite & typescript로 구축하며 생겼던 몇가지 문제.
- vite.config.js는 괜찮지만, vite.config.ts는 트랜스파일링에서 문제가 생김: builder 패턴으로 해결
- yarn PnP 모드를 사용시 tsconfig의 extends가 작동하지 않음: pnpm모드 사용
Vite와 통합되어 Storybook과 Jest를 대체하는 프로젝트들도 나오게 되었다.
역시 성능에 초점을 맞추고 있다.
- Storybook - Ladle [Introducing Ladle]
- Jest - Vitest [From Jest to Vitest - Migration and Benchmark]
그냥 생으로 rollup + esbuild 세팅에 관심있다면 rollup-typescript라는 gist를 참고해봅시다.
에어비엔비에서는 React Native에서 사용하는 Metro를 사용해 속도를 올렸다.
특이한점은 다계층 캐시가 있다는 것.
태스크 러너의 경우 앞서 말했듯 Grunt와 Gulp가 유명하구(taskr이라고 코루틴을 사용한 플젝도 있다는 모양)
윗 글들만 읽어보면 충분할거라 생각한다.
단순히 npm scripts를 효율적으로 실행시키고 싶은거라면 wireit이란 프로젝트도 참고해보자.
지금, 멀티레포 관리 툴과 wireit을 보면 태스크 러너 바퀴의 재발명이라는 생각이 든다.
Git 명령어에 따른 태스크를 실행시키는 husky는 현재도 많이 쓰인다.
5.5 린트와 포매팅
개요
보통은 eslint, prettier를 각각 구현방식, 코드 포맷 검증용으로 사용한다

Using Prettier and ESLint to automate formatting and fixing JavaScript
.
린터는 코드의 안티패턴과 에러를 찾아서 검출하려는 목적이며,
포매터는 2 space, 4 space처럼 코드의 스타일을 통일하려는 목적이다.
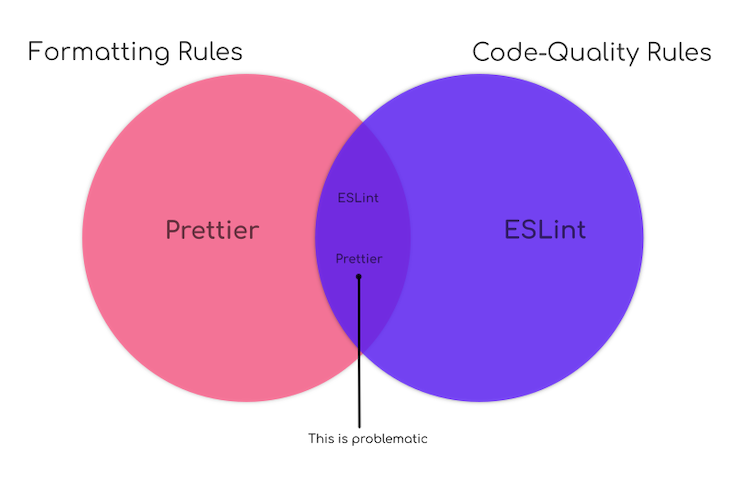
여러 케이스가 합쳐지면 까다로우니 다음 글들을 확인 부탁드린다.
- Typescript 프로젝트에 ESLint, Prettier 적용하기
- TypeScript ESLint + Prettier 함께 사용하기(w/ VSCode)
- ESLint, Prettier Setting, 헤매지 말고 정확히 알고 설정하자.
- How to integrate Prettier with ESLint and stylelint
- Why and How to Lint like a PRO
개인적으로 잘가, 클린 코드란 글의 의견처럼 빡빡하게 린트와 포매팅하는 것을 좋아하지는 않는다.
보기좋은 코드를 만들기 위해 스페이스를 많이 활용하는 편인데 많은 포매팅 규칙들이 멀티 스페이스를 삭제시켜버린다.
때문에 React의 코드만 봐도 강제적인 포맷팅에서 회피하기 위해 주석으로 공간을 만들어주는걸 볼 수 있다.
약간만 유연하게 한다면 내가 작성했던 SplitCubicalBezier처럼 나름 깔끔하게 나온다.
해결방안
Eslint와 Prettier 대체제는 음..
나중에 Rome로 어떻게든 될 수 있지 않을까..
그렇지만 지금은 툴 자체가 성숙하지 않았기 때문에 다른 대안을 찾아보자.
- Modern, faster alternatives to ESLint
- Introducing esprint: a fast, open source eslint CLI
- Customizing ESLint
quick-lint-js도 빠르지만 아직 타입스크립트를 지원하지 않는다.
아직 eslint + esprint나 eslint_d 조합이 최선이라 생각한다.
포매팅의 경우
위의 eslint_d와 같은 계열인 prettierd 또는 dprint를 사용해볼 수 있다.
+.
lint-staged, pretty-quick은 staging된 파일에만 적용하여 빠르게 체크가 가능하다.
CSS의 경우 stylelint_d를 확인해보는 것도 좋다.
5.6 테스트
개요

Why I think Jest is better than Mocha & Chai
이 파트도 Toast UI가 잘 정리해줬다.
너무 깔끔해서 여기서 설명을 안해도 될 듯 싶다.
아 그리고, Enzyme를 사용하고 있다면 React Testing Library를 사용하도록 하자. [Enzyme is dead. Now what?, React Testing Library 사용법]
테스트에 관심있다면 Property based testing도 시도해보는건 어떨까?
하스켈의 QuickCheck로 유명하며, 자바스크립트쪽에는 fast-check를 쓰면 된다.
테스트 입력값을 테스팅 도구가 자동 생성해서 확인할 수 있다.
만들기는 까다롭겠지만 엣지케이스 버그를 찾기가 더 좋다.
해결방안
현재로선, Jest가 가장 많이 쓰이고 있는 것 같다.
다만, Jest가 병렬로 실행됨에도 느리다는 말이 좀 있다..
가장 큰 병목 중 하나는 import를 매번 다시 하기 때문인듯하다.
- Bending Jest to Our Will: Caching Modules Across Tests
- Speed up TypeScript with Jest
- Performance Regression Report
- JavaScript test performance: getting the best out of Jest
또 다른 성능 향상 방법으로 샤딩을 사용하면 깃허브 액션에서 매트릭스를 이용해 테스트를 나눌 수 있다.
앞서 언급한 vitest는 vite의 resolver를 사용하고 esm first등의 이점이 있어 성능면에서 나은 점도 있다.
게다가 러스트처럼!!! 소스내부에서 유닛테스트가 가능하다는게 가장 큰 장점.
벤치마크의 경우 논의 중에 있다.(이제 지원됨)단, 아직 캐싱과 샤딩(이슈)을 지원하지 않아서 아쉽다.(이제 지원됨)또한 Jest의 커스텀 러너를 허용하게 되면 일렉트론 환경에서도 테스트가 가능하고, 린트/타입체크 모두 테스트 러너를 통해 효율적으로 실행할 수 있다.
이건 아직은 지원안하는 중.
5.7 CI/CD
개요
예전에 Emacs-NG에 CI 성능관련 PR을 만들었을때 몇가지 인사이트를 얻을 수 있었다. [깃허브 워크플로우 최적화]
autoconf로 빌드하는데다가 C, Rust, Elisp 컴파일등 상당히 복잡한 구조를 가졌기에 여러가지를 고려하기 좋은 프로젝트였다.
핫빌드 기준 무려 278%의 성능향상을 했었다.
- 우분투: 26m 5s => 11m 53s
- 맥OS: 39m 7s => 14m 8s
의외로 CI/CD 시간 단축 작업은 쉽지 않은데, 다운로드/업로드와 빌드, 빌드 후 동작등 모든 것을 고려해야 한다.
해결방안
- CI/CD 건너뛰기/분리
가장 좋은 것은 CI/CD 자체를 실행하지 않는 것이다.
README만 바뀌었는데 매번 빌드와 테스트까지 모두 할 필요는 없지 않은가.
만약 문서 퍼블리싱을 해야한다면, 퍼블리싱만 수행하면 된다.
깃허브의 경우 다양한 필터링을 할 수 있다.
이 뿐만이 아니다.
병합 후처럼 굳이 실행할 필요가 없는 중복된 경우에도 건너뛸수 있고, 테스트 코드만 고쳤을 경우에는 이전 빌드 결과를 사용해볼 수도 있다.

서로 의존하지 않는 CI/CD를 분리할 수 있다.
예를들어 코드 포매팅 확인, 문서 배포 등은 빌드와 함께할 필요가 없다.
Jest나 Vitest등은 샤딩(shard) 옵션을 제공하므로 병렬 job으로 나누어 실행할 수도 있다.
- 다운로드 및 CI/CD 환경
CI/CD를 실행하려면 의존하는 패키지가 설치되어 있어야하고, 레포의 코드 또한 다운로드 받아야 한다.
일단 의존하는 패키지들이 설치되어 있어야 한다.
일반적인 경우, 깃허브 액션 캐시로 node_modules나 .yarn등만 캐시하면 충분하다.
그러나 가끔은 의존하는 네이티브 패키지를 컴파일 해야하는 경우처럼 시간이 많이드는 작업이 있을 수도 있다.
이럴때는 미리 도커로 의존성 빌드 후, 배포하는 것이 좋다.
도커빌드 시간 줄이는 방법
- Caching Docker builds in GitHub Actions: Which approach is the fastest? 🤔 A research.
- buildx, buildkit 사용 [Docker buildx, Build images with BuildKit, Docker Buildkit 으로 빌드 시간 단축하기]
- 도커 빌드 캐싱
도커빌드시 Nix를 이용해 캐싱하기 (이때 tmpfs를 사용할 수도?)
- Optimising Docker Layers for Better Caching with Nix
- A faster dockerTools.buildImage prototype
- Nixery: Improved Layering
- nix2container
빠르게 다운로드 받기
- 도커 이미지 크기 줄이기 [Docker - image 크기 줄이기, Go 프로젝트 Docker 이미지 크기 99.2% 줄이기 (부제: 이미지 크기 12921% 떡상 시키기)]
- 깃허브 레지스트리: 깃허브 액션에서 깃허브 레지스트리가 더 빠르다는 듯
다음은 레포지토리관련 최적화이다.
일단 레포지토리 자체의 크기를 줄이는 것을 생각해볼 수 있다.
Git LFS, Git submodule 활용하기, Introducing Scalar: Git at scale for everyone
- 파일과 커밋기록 영구제거: 보통은 패스워드처럼 민감한 파일을 제거하는데 사용하지만 커다란 파일을 삭제하거나 레포지토리를 나눌때도 활용할 수 있다. [깃 레포 분리하기/합치기, Removing sensitive data from a repository, Remove a Large File from Commit History in Git, How (and why!) to keep your Git commit history clean]
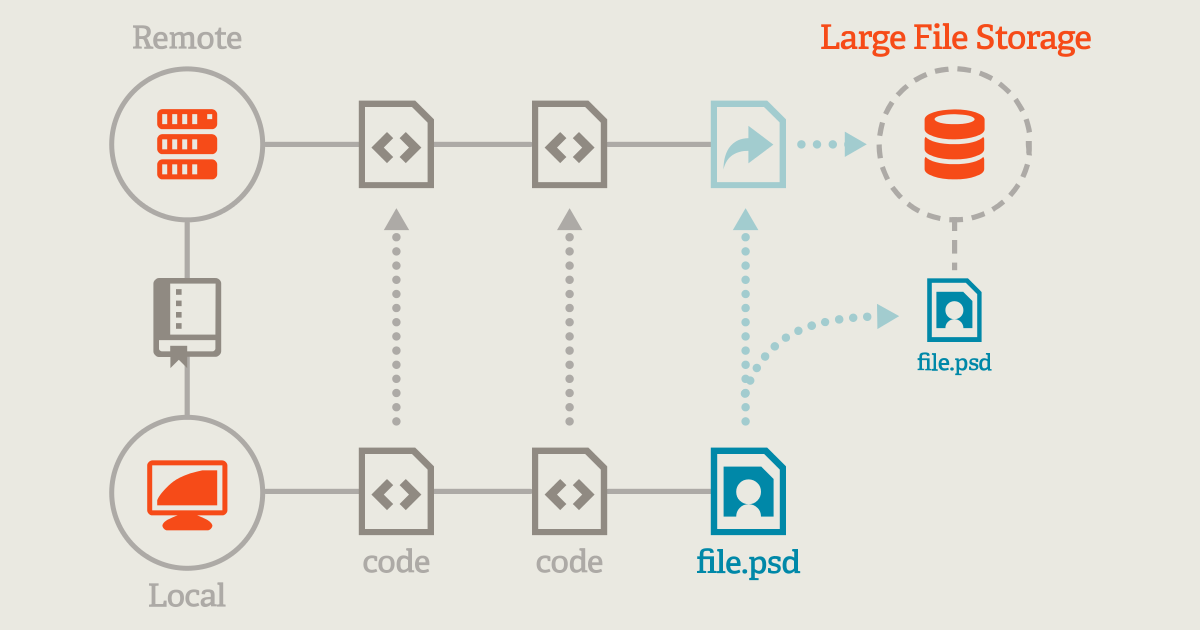
- Git LFS 사용: 커다란 파일은 텍스트 해시로 만들고 따로 다운로드하여 가볍게 만들 수 있다
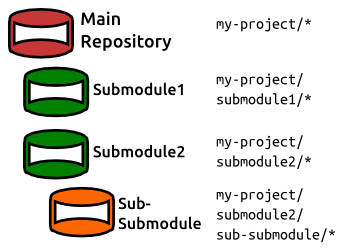
- 서브모듈 사용: 역시 원본 레포를 가볍게 만들며, git clone --jobs로 여러 서브모듈을 한번에 다운로드 받을 수 있다
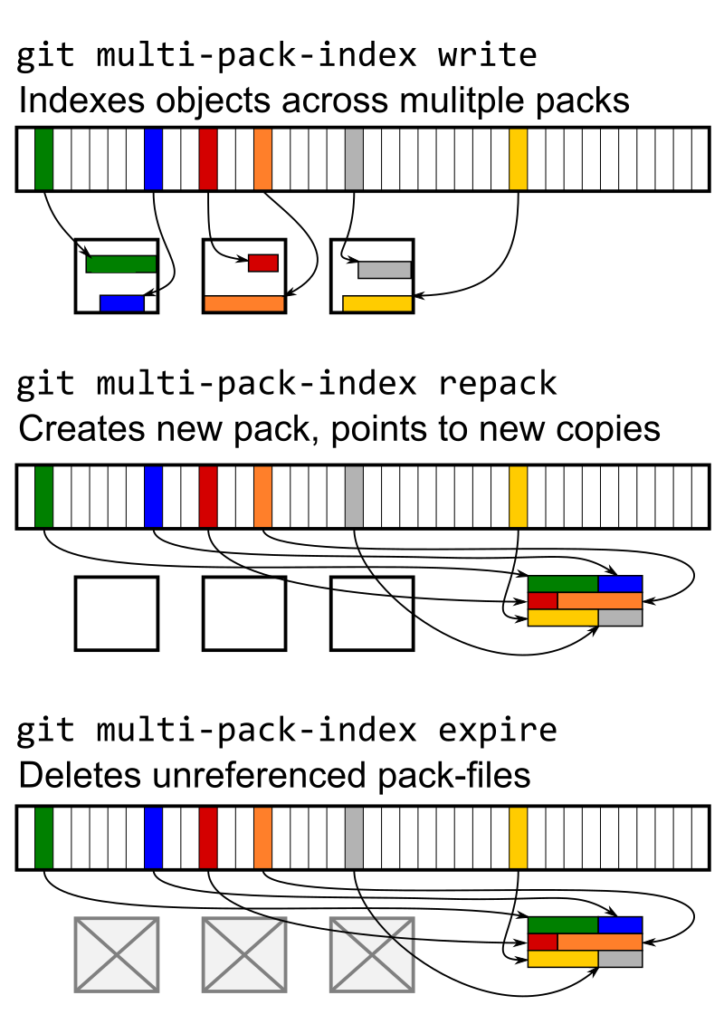
- 레포지토리 GC: 복잡한 레포지토리의 경우 object/pack등을 관리해볼수도 있다 [레포지토리를 가볍게, Git 저장소의 성능을 유지하는 방법, Scaling monorepo maintenance]
git remote prune orign git reflog expire --expire=now --all git gc --aggressive --prune=now git repack -abdk --window=1000 --depth=500 git repack -fF --write-midx --write-bitmap-index -d --geometric=2다운로드시 타겟을 줄이는 방안도 있다.
Git 2.18에서 도입되어 2.26에 기본값으로 채택된 Git prtocol2가 큰 도움이 되었다.
예를 들어 CI/CD에서 테스트 하는데 모든 정보를 다운로드 받을 필요는 없지 않겠는가?
오래된/거대한 프로젝트는 수많은 커밋, 디렉토리, 브랜치들이 있을수도 있다.
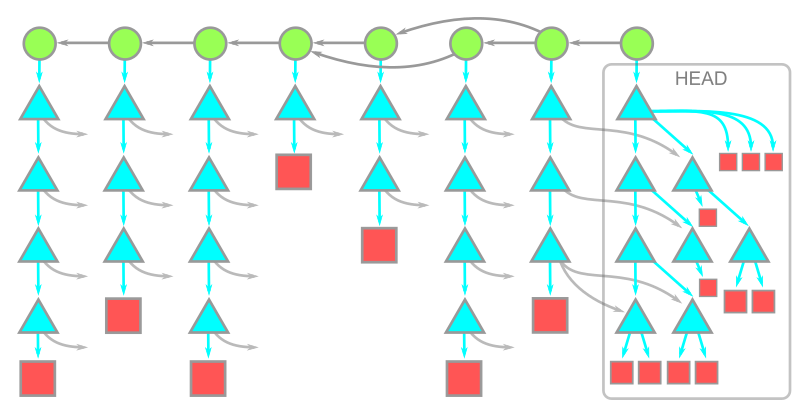
모든 커밋 - 원: 커밋, 삼각형: 디렉토리, 사각형: 파일(blob) 부분 복제(Partical clone)은 --filter 옵션을 통해 기존 파일(--filter=blob:none), 더 나아가 디렉토리(--filter=tree:0)를 제외하고 다운로드 받을 수 있게 지원한다.
[Get up to speed with partial clone and shallow clone, How to Use Git Shallow Clone to Improve Performance, Gitlab partial clone]
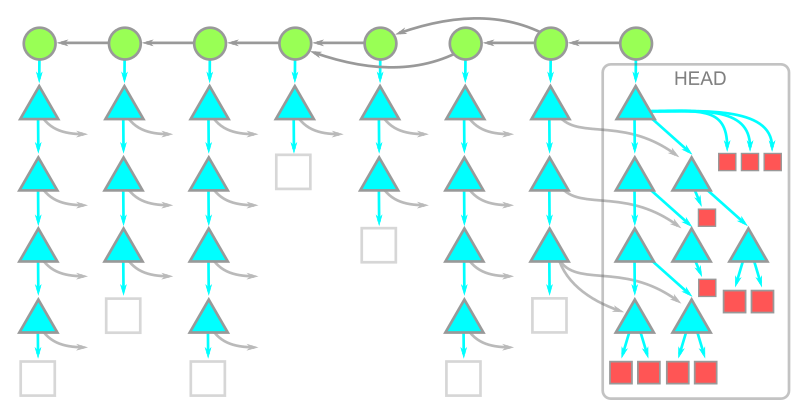
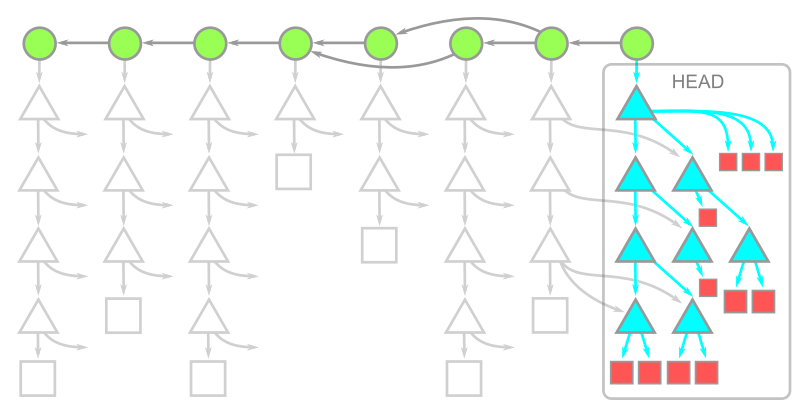
기존 파일을 빼고, 기존 디렉토리를 빼고 clone시 --depth=1로 1개의 커밋으로 제한시키고, --single-branch --branch=<branch>로 브랜치를 제한할 수 있다.
기존 커밋기록까지 빼고 다운로드가 되고 나면 체크아웃 되는 과정도 있다.
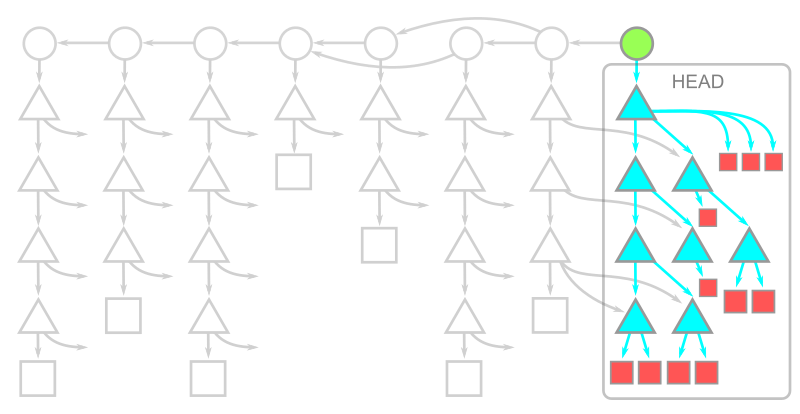
이때 Git 2.25에서 도입된 sparse-checkout을 사용하면 원하는 부분만 체크아웃할 수 있어 시간과 디스크 용량을 절약할 수 있다. [Bring your monorepo down to size with sparse-checkout]
모노레포를 사용할 때도 유용하게 사용할 수 있다.
정리해보자면
- clone --filter : 옛 커밋에서 복제할 내용을 필터링 가능 (particial clone)
- clone --depth: 가져올 커밋 히스토리양을 제한
- clone --single-branch: 한 브랜치만 클론 할 수 있음
- sparse-checkout: 특정 디렉토리나 파일만 사용
[업데이트] 최신 Git 2.38에는 scalar라는 기능이 들어가서 sparse를 기본으로 lazy하게 쓸 수 있다.
- 빠른 빌드 및 테스트
기본적으로 빠른 도구들을 사용하자.
여기서 말할 것은 웹이 아니라 네이티브 프로그램을 위한 팁에 가깝다.
바로 프로덕션 모드와 디버그 모드의 트레이드 오프이다.
일반적으로 프로덕션 모드에는 최적화가 들어가므로 더 느리다.
그러나 빌드후 오래 걸리거나 계산집약적 통합 테스트등의 작업을 수행할 경우에는 프로덕션 모드로 최적화하는 것을 고려해볼 수 있다.
- 기타
소스파일 빌드관련 캐시처럼 매번 캐시업로드가 필요한 경우가 있을 수도 있다.
그러나 매번 캐시 업로드는 좋은 전략이 아니다.
10메가, 20메가 수준이라면 괜찮겠지만 기가 단위처럼 커다란 경우라면 캐시가 깨져 빌드가 조금 느리더라도 일주일에 한번씩처럼 주기적으로 갱신하는게 좋을 수 있다.
게다가 다운로드/업로드 회선이 비대칭인 경우가 많아서 느리다.
또한 캐시의 크기를 줄이려면 디버그 정보를 줄이고, 증분빌드를 비활성화해야 할 수도 있다.
