-
동시성, 병렬, 비동기, 논블럭킹과 컨셉들컴퓨터 2022. 6. 3. 11:44
위 용어들은 모두 빠르게 실행하거나, 빠르게 느끼도록 만들때 주로 사용하는 용어들이다.
많은 사람들이 이미 적어놨으나 저도 한번 동참해보겠습니다.
차이가 있다면 되도록 이미지를 많이 사용하여 직관적으로 이해하기 쉽게 만들어보는게 목표.
좋은 이미지를 찾는데는 항상 많은 시간이 소요된다.
또한 풍부한 레퍼런스와 넓은 범위를 다루려 노력했다.
1. 용어
동시성 / 병렬
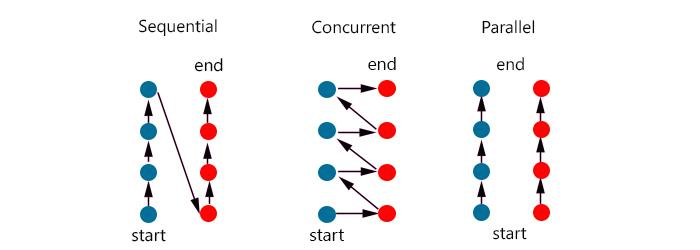


- 동시성: 동시에 작업이 실행된 것처럼 보이면 되며(논리적)
- 병렬: 실제로 동시에 작업이 실행되어야 한다(물리적)
따라서 싱글코어에서 시분할로 나누어 일을 처리하더라도 동시성을 지원한다고 말 할 수 있다.
반대로 싱글코어에서 SIMD를 이용하면 병렬로 작업을 실행할 수 있다. [SIMD (Single Instruction Multiple Data)에 대한 집중탐구!]
비동기 / 논블로킹
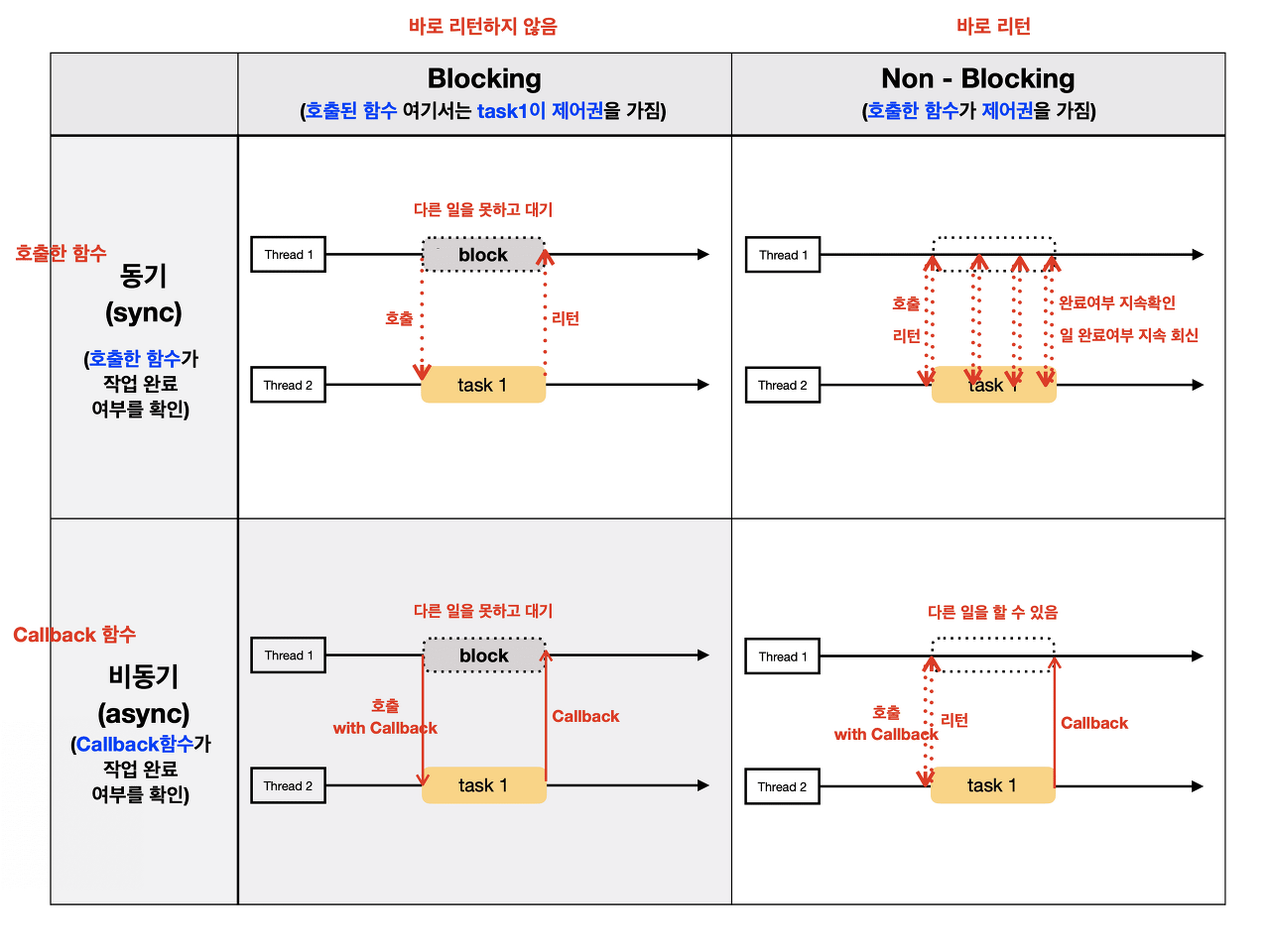
어떤 함수가 작업완료와 제어권을 결정하느냐의 차이라 생각하면 쉽다.
- 동기와 비동기는 작업완료를 누가 확인하는가
- 블로킹과 논블로킹은 제어권한이 있는가
위 그림으로 애매한가요?
그럼 이렇게 생각해봅시다.
먼저 동기와 비동기 회로.
동기회로는 타이밍을 위해 클럭을 이용하고, 비동기는 이벤트나 다른 입력에 의해 트리거되는 방식이다.
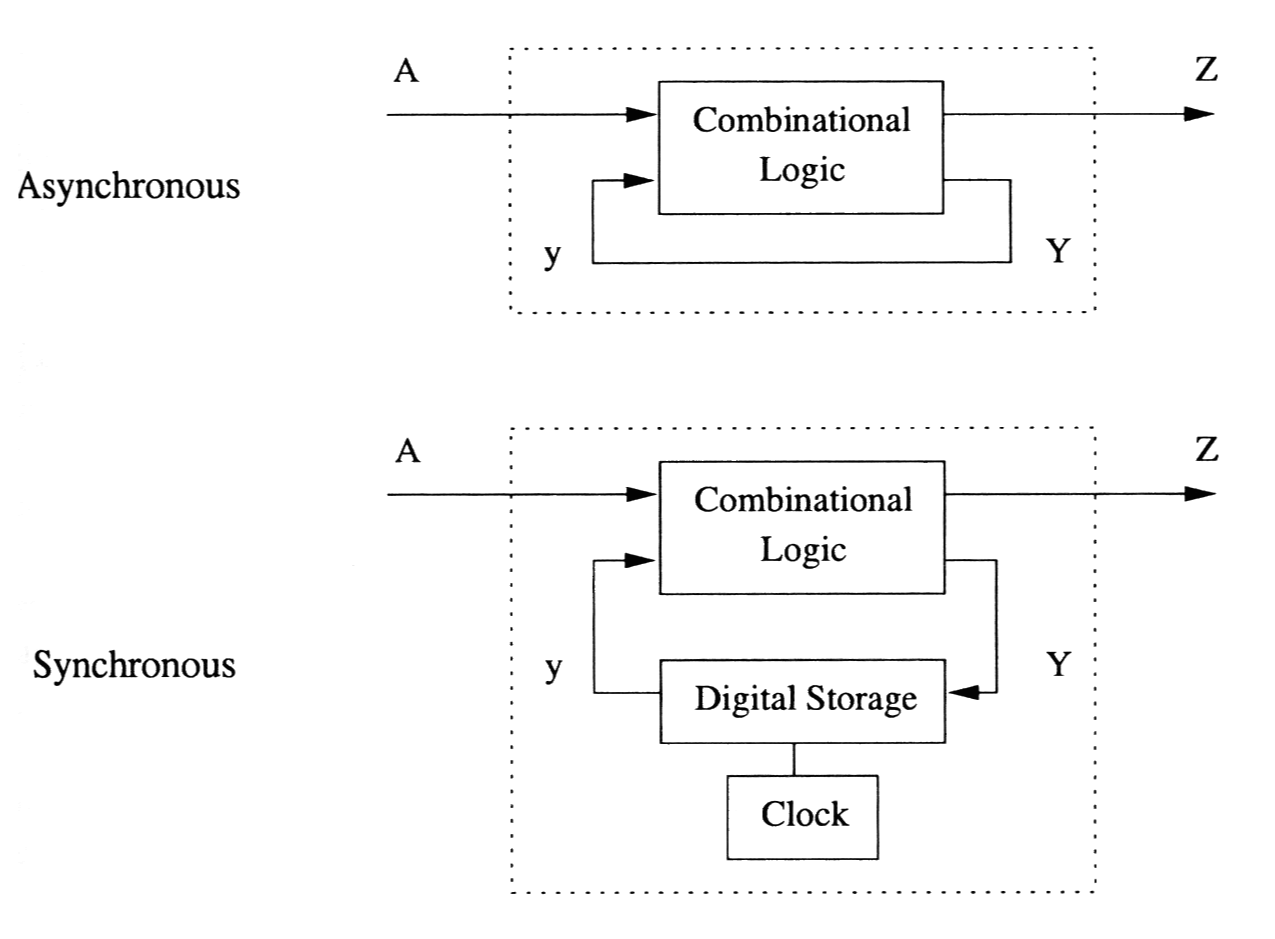
Synchronous and Asynchronous Circuits
소프트웨어 API에서 비동기는 콜백등에 의해 트리거되는 형태라 생각하자. [Synchronous and asynchronous requests]
언뜻 비동기가 동기보다 좋아보이지만 각자 유리한 방향이 다르다.
- 동기: 파이프라인을 활용시 효율적
- 비동기: 독립적이거나 지연이 클 때 효율적
(약간의 오버헤드가 있으며 순서를 보장하지 않음)
블럭킹/논블럭킹은 작업이 완료될 때까지 기다려야 하는가의 여부로 생각하면 적절하다. [Overview of Blocking vs Non-Blocking]
선점형 / 비선점형

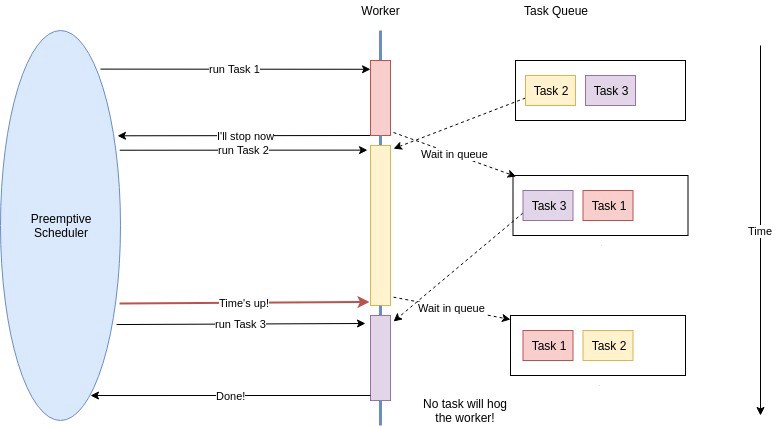
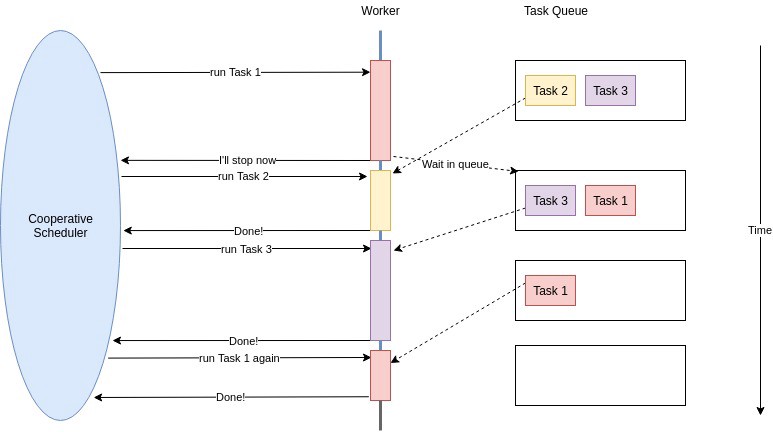
선점형과 비선점형 - 선점형: 스케쥴러가 중간에 다른 작업으로 전환할 수 있음
- 비선점형: 작업이 스위칭 해줘야 다른 작업으로 전환할 수 있음
선점형은 Non-Blocking, 비선점형은 Bloking의 일종이라 볼 수 있다.
2. 운영체제와 프로세서
운영체제
프로세스는 실행중인 프로그램의 인스턴스로 고유한 주소공간을 가지며 서로 격리되어있다.
다른 프로세스에는 직접 엑세스할 수 없으므로 데이터를 주고 받으려면 IPC등을 이용해야 한다.
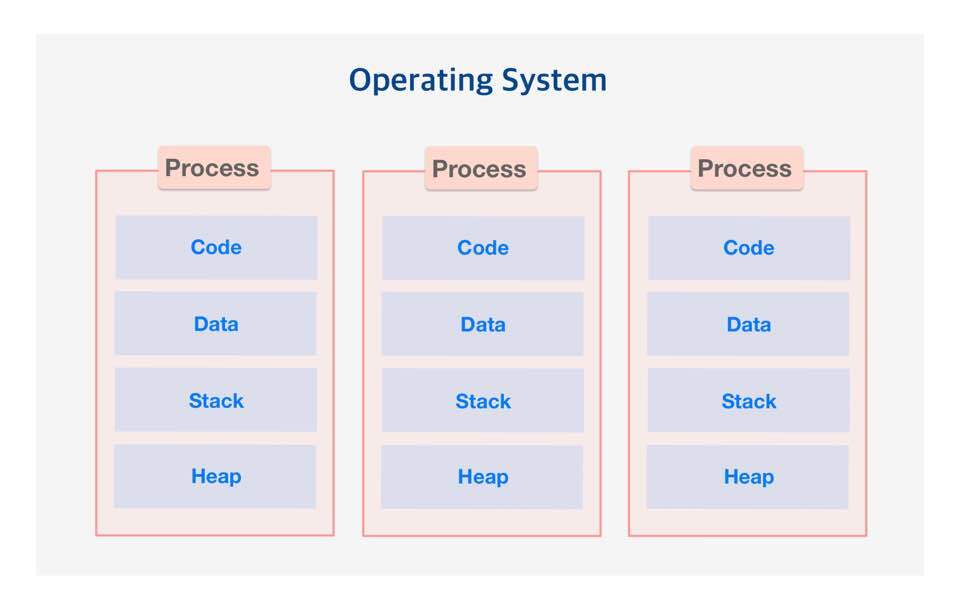
위에서 보이는 코드, 데이터, 스택, 힙은 메모리 레이아웃이라 배우는 그것이라 생각해도 좋다.
OS나 언어등의 환경마다 조금씩 다를 수 있지만.

스레드는 프로세스 내에서 실행되는 여러 흐름의 단위다.
데이터와 코드를 공유하고 별도의 카운터, 레지스터, 스택을 가진다.
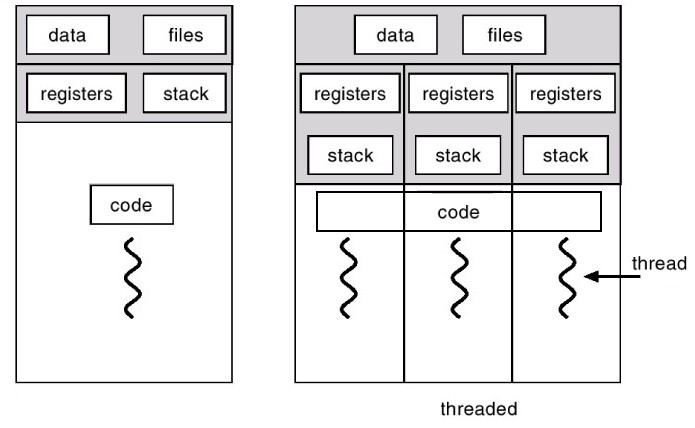
프로세스와 달리 Heap, Data 영역을 공유하여 IPC가 필요없고
컨텍스트 스위치 비용도 적다.

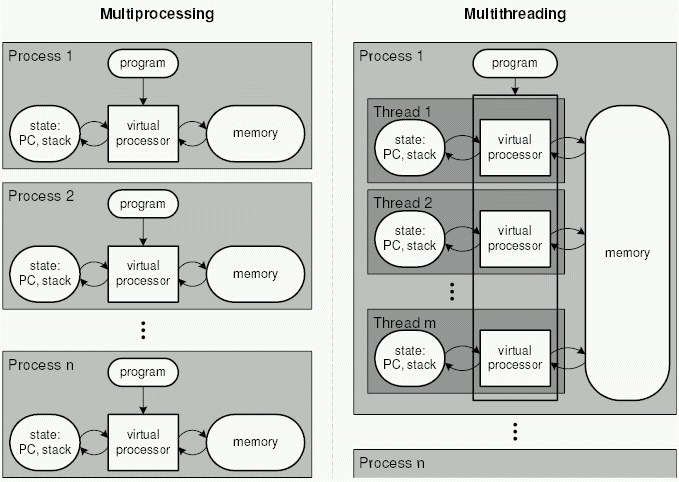
윈도우쪽 프로세스, 스레드 이야기는 Processes, Threads, and Jobs in the Windows Operating System에 잘 정리되어 있다.
프로세서
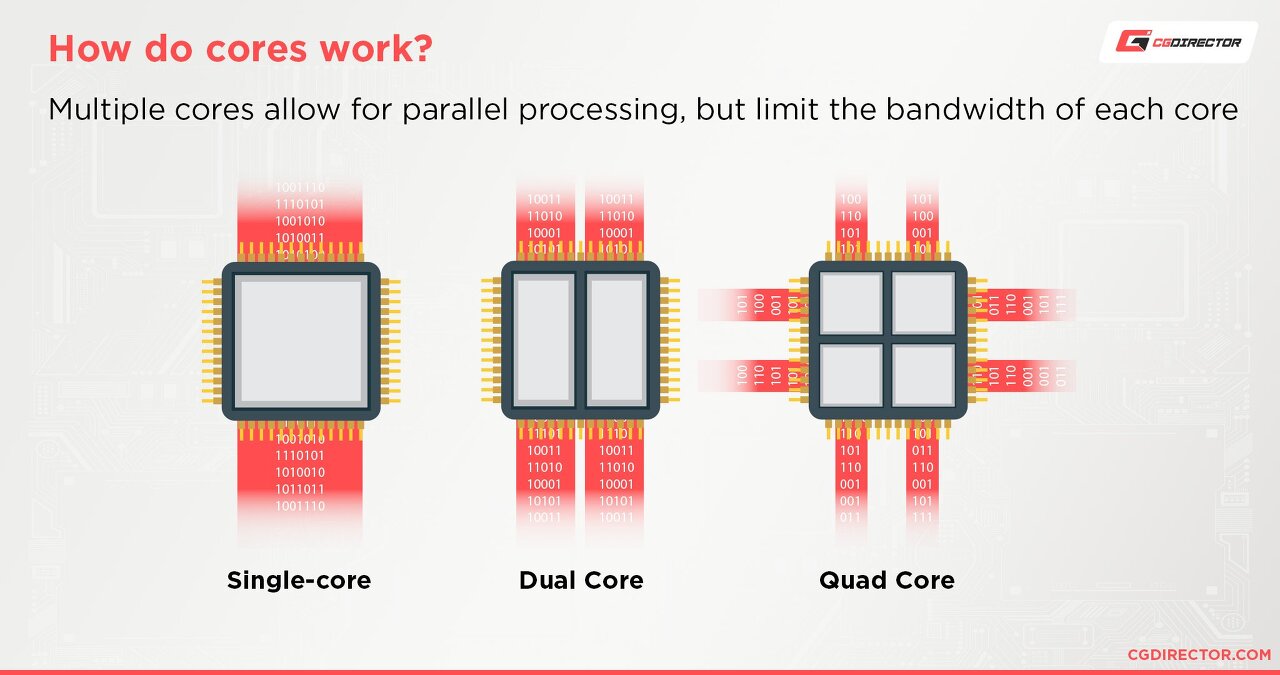
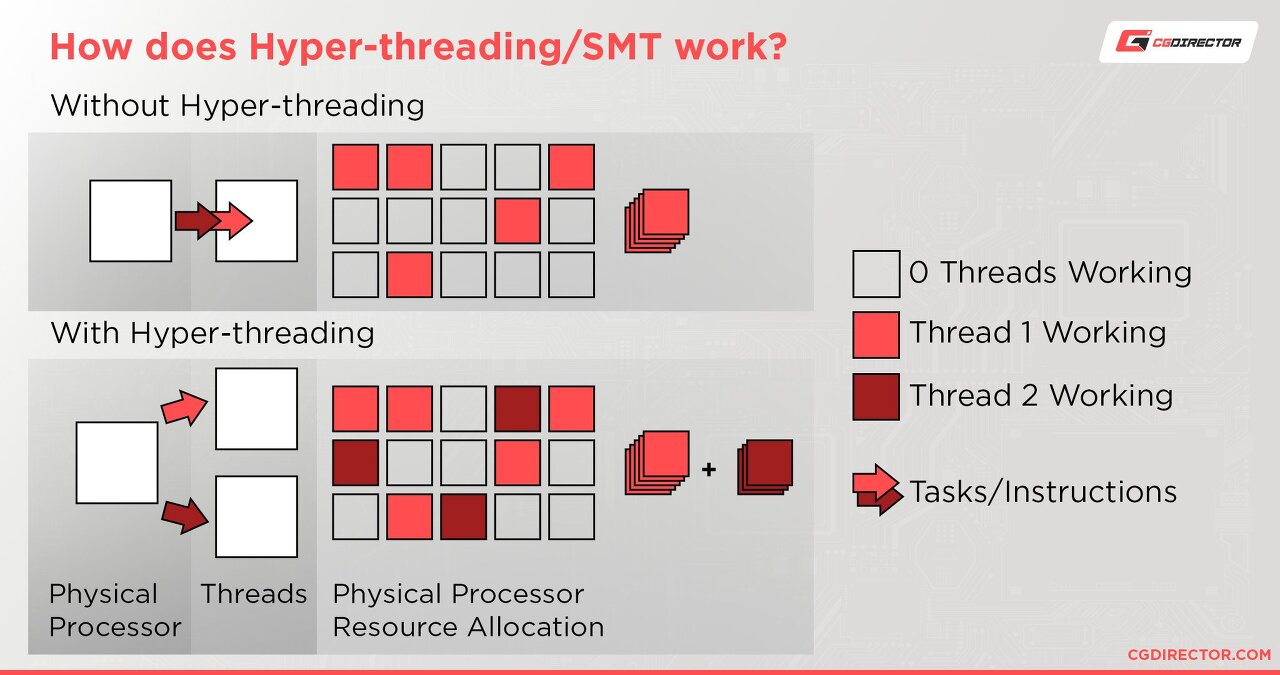
- 물리: CPU에 들어간 실제 코어
- 논리: 작업부하를 공유하며 동시에 스케쥴링
일명 하이퍼 스레딩이라는 기술을 이용해 컨텍스트 스위칭과 유휴시간을 줄일수 있다
정리해보자면 다음과 같다
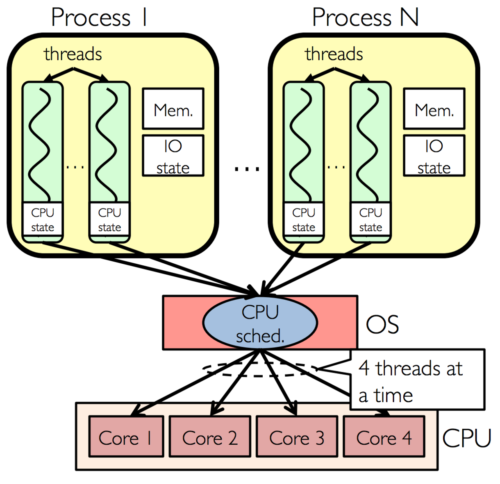
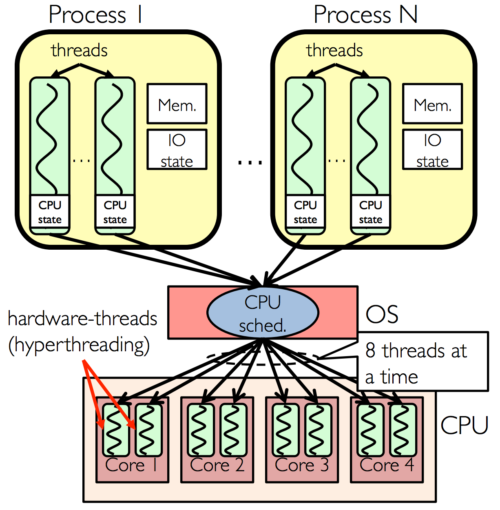
Multi Core vs. Hyper-threading
보통 최대한 성능을 뽑기위해 쓰레드 풀에서 논리 코어 갯수대로 생성하는 것으로 알려져있다.
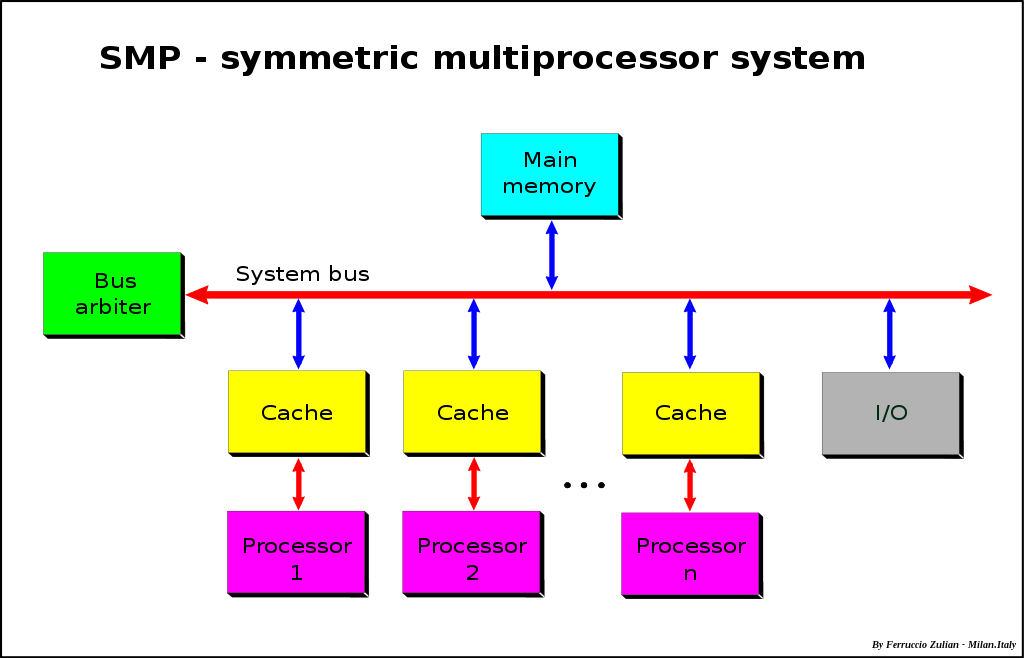
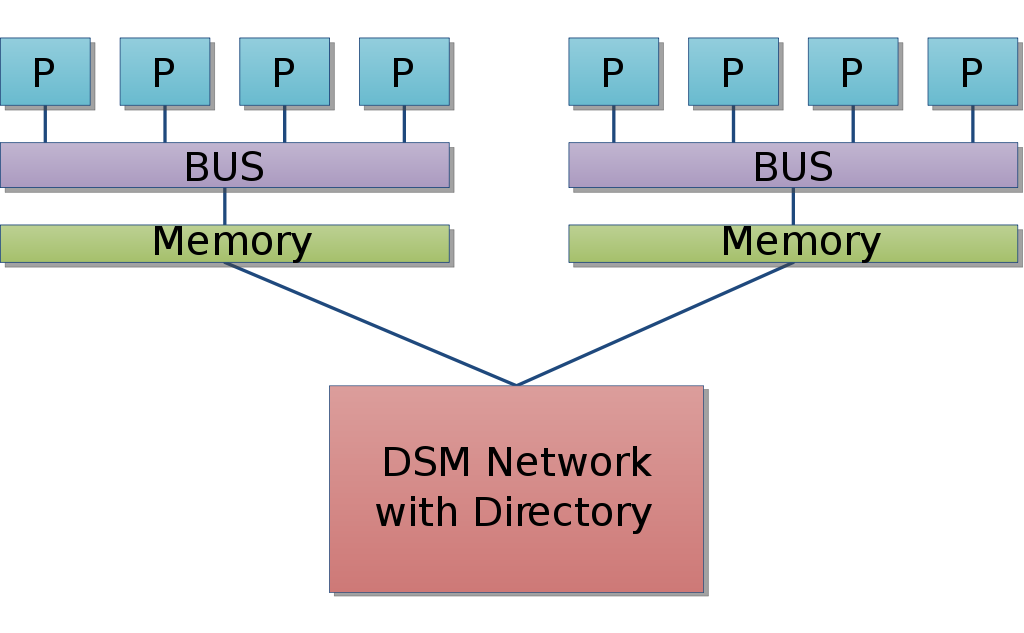
SMP와 NUMA 여러 프로세서가 공유된 메모리를 사용하는 SMP(Symmetric Multi Processing, 대칭형 다중 처리)와 로컬메모리와 외부 메모리를 분리해 사용하는 NUMA(Non-uniform Memory Access, 불균일 기억장치 접근)에 대해서도 알아보길 바란다.
커널과 사용자 공간
- Architecting Containers Part 1: Why Understanding User Space vs. Kernel Space Matters
- Linux Kernel Explained
- What is eBPF?
운영체제는 일반적으로 메모리와 하드웨어를 보호하기 위해 사용자 공간(User space)과 커널 공간(Kernel space)을 나눈다.
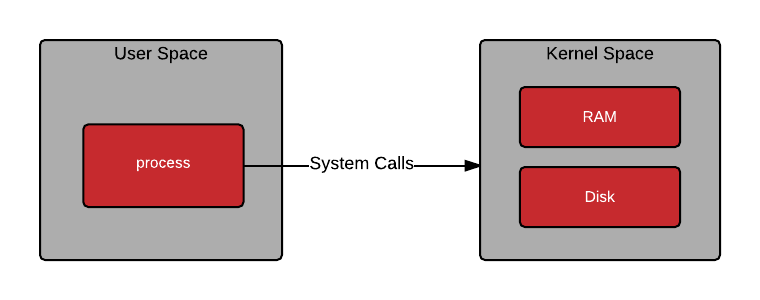

유저 공간과 커널 공간 모든 사용자 프로세스는 사용자 공간에서 실행되며, 시스템 콜을 통해 커널에 요청을 할 수 있다.
커널에서는 모든 시스템 기능(VFS, IPC, 스케쥴링, 드라이버 등)을 커널 공간에서 실행하는 모놀리식, 최소한만 실행하는 마이크로, 중간 방식인 하이브리드로 나뉠수 있다.
모놀리식은 한번의 시스템콜로 여러 시스템 컴포넌트를 호출 할 수 있으므로 성능이 낫고, 마이크로는 서비스가 오류나도 커널 전체가 패닉이 생기지 않으므로 안정성이 좋은 편이다.
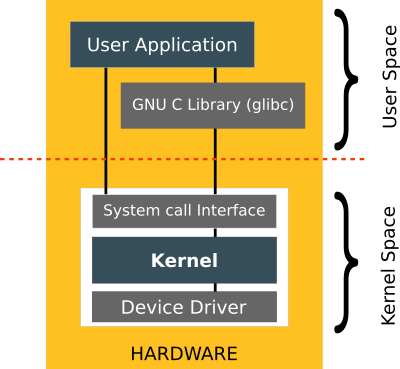

시스템콜과 커널의 유형 리눅스(모놀리식), 푸크시아(마이크로), 윈도우 NT(하이브리드)가 대표적인 예.
커널 공간은 분리가 되어 있으므로 시스템콜은 컨텍스트 스위칭 비용이 크다. (복사가 필요함)
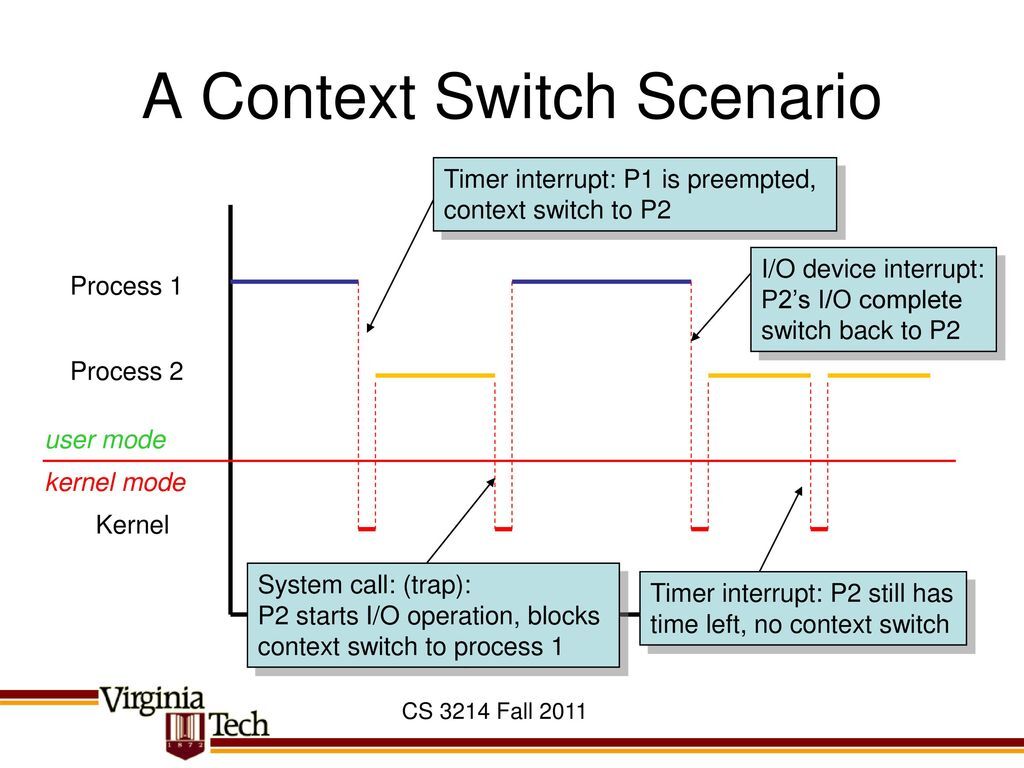
Context switch-Everything you need to Know
또한 커널은 커널 모듈을 사용하더라도 재빌드가 필요하거나, 문제가 있을 시 패닉이 생기는 한계가 있었다.
최근에는 eBPF를 통해 안전하면서도 커널공간에서 프로그램을 실행하는 방법이 생겼다!!
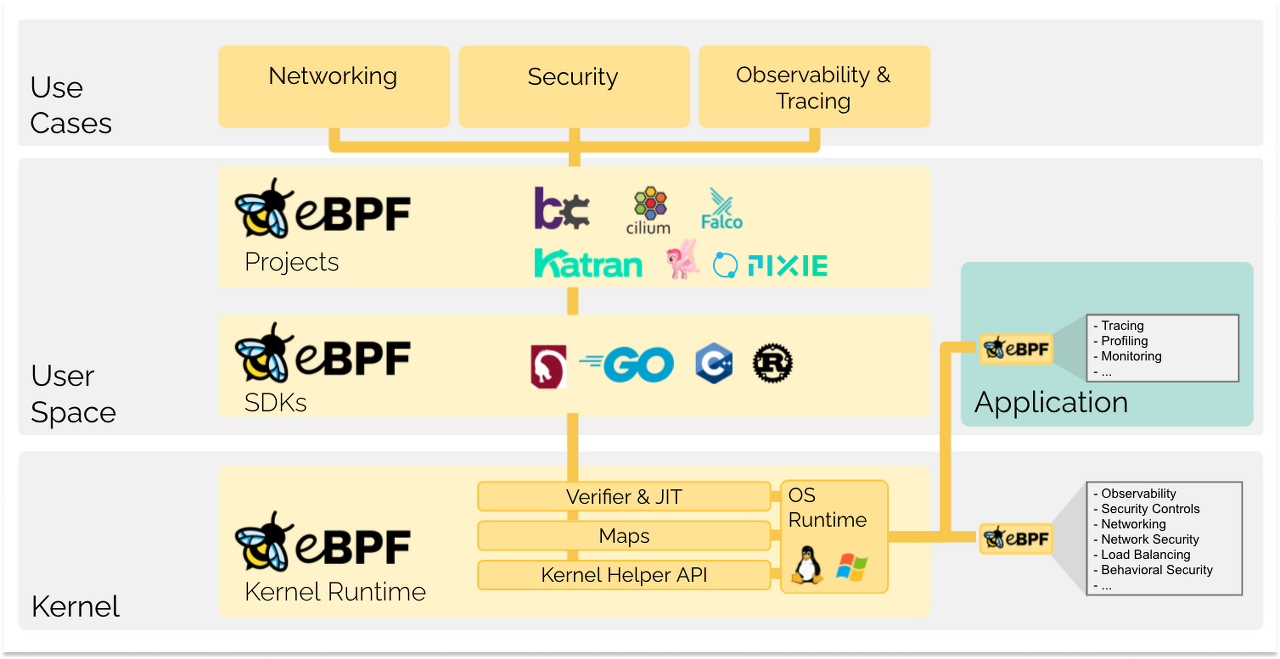

eBPF를 사용한 예로 XDP(eXpress Data Path)가 있으며, 반대로 유저스페이스를 최대한 활용하려는 시도인 DPDK(Data Plane Development Kit)도 주목할만 하다. [XDP(eXpress Data Path), K8s 에서의 eBPF/XDP 기반 고성능 & 고가용성 NAT 시스템, What is DPDK?, DPDK+eBPF]
3. 코루틴과 파이버
파이버
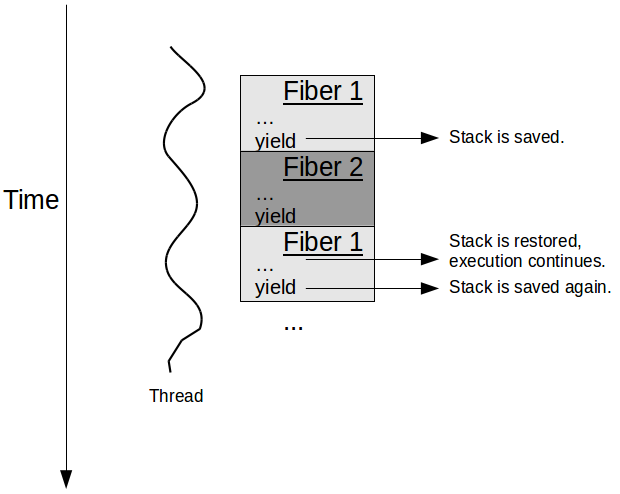
쓰레드가 경량 프로세스라면, 파이버는 경량 쓰레드다.
파이버는 쓰레드와 달리 자발적으로 실행을 중지해야 양보할 수 있으며 커널이 아닌 사용자 공간에서 이루어진다. (비선점형, 협력적 멀티 태스킹)
예외적인 케이스로 DragonFly BSD의 LWKT(Light Weight Kernel Threads)가 커널 공간의 선점형 시스템이긴하나.. 일반적인 경우는 아니다.
따라서 같은 쓰레드의 파이버끼리의 전환은 컨텍스트 스위칭 비용은 매우 적다.
코루틴
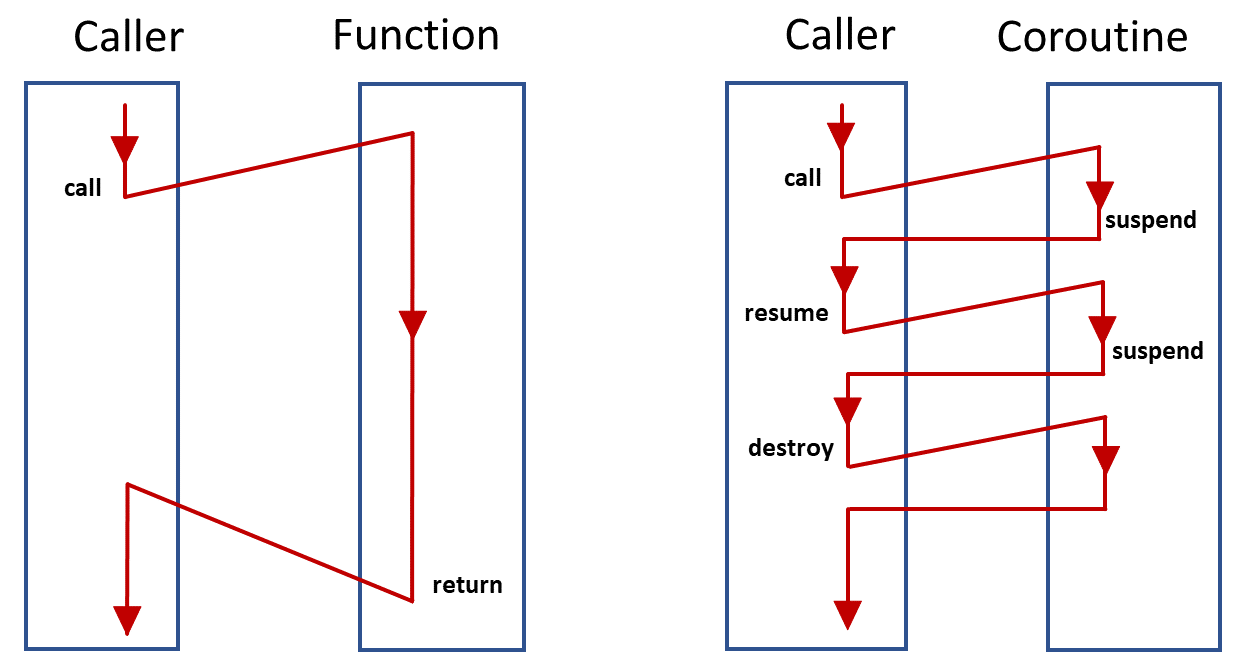
코루틴은 일시중단(suspend)했다가 재개(resume)할 수 있는 제어요소다.
파이버와 코루틴은 쓰레드/함수 관계와 비슷하며, 유저수준에서 가장 큰 차이는 코루틴은 서브 루틴처럼 Caller-Callee 사이에서 전환되지만, 파이버는 스케쥴러에 의해 순서가 정해질 수 있다.
코루틴에서 주목할만한 것은 Stackful, Stackless 코루틴이다.
프로토 쓰레드(Protothread)라 불리는 것도 스택리스 코루틴의 일종이라 할 수 있다.

Stackful 코루틴 Stackless 코루틴은 피호출자(Callee) 중지(suspend)가 되면 호출자(Caller)로 돌아오지만,
Stackful 코루틴은 sub function에서도 호출자로 돌아올 수 있다.
대신 Stack 정보를 저장해야 하므로 메모리를 더 소모한다.
4. 제네레이터, Async/Await, 컨티뉴에이션
제네레이터
코루틴 링크에 설명되어 있듯 제네레이터는 코루틴의 한 종류이다.
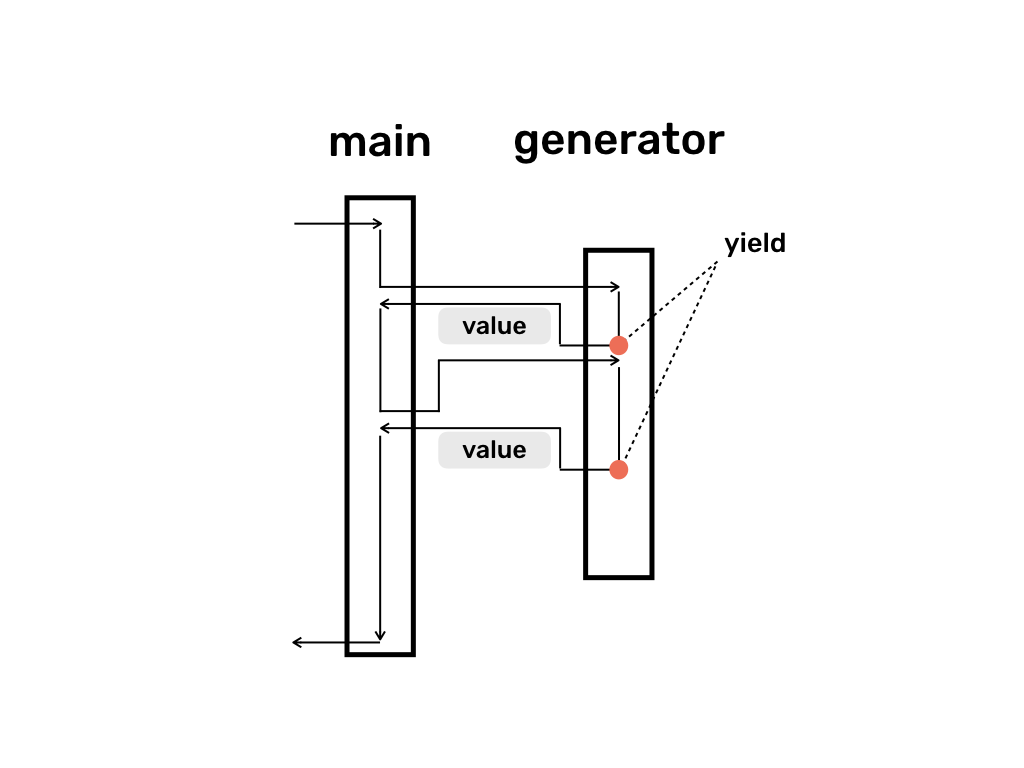
제네레이터 Generator 코루틴은 suspend(즉 yield)할 때 제어권을 따로 지정하지 않으며, 자동으로 Caller에게 넘어간다. 이러한 코루틴을 Semi-coroutine 혹은 Asymmetric 코루틴이라고 한다.
반대의 개념, Symmetric 코루틴도 있다. Caller/Callee의 관계가 성립하지 않으며 A 코루틴이 B 코루틴으로 제어권을 넘겨서 B가 resume되면(A는 제어권을 넘기면서 suspend), B는 그 제어권을 꼭 A에게 넘길 필요가 없다. 또다른 코루틴 C에게 제어권을 전달하면서 suspend할 수 있다. 따라서 Symmetric 코루틴은 suspend할 때 제어권을 넘겨받을 코루틴을 지정하여야 한다.
Async / Await
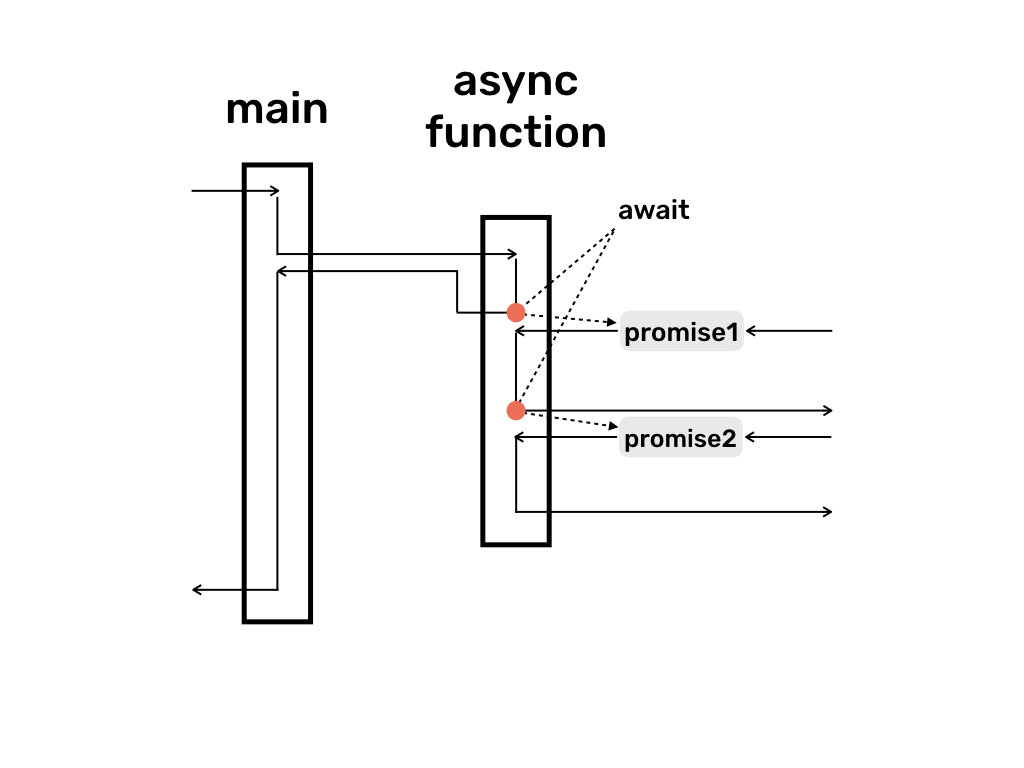
일반적인 Async/Await, 결과를 반환하는 Async/Awiait Async/Await는 언어나 런타임에 따라 동작이 상이할 수 있으나 자바스크립트의 경우 await가 생기면 비동기 함수의 실행을 일시적으로 중단하고, 메인 프로세스를 진행한다.
이러한 동작 때문에 프론트엔드의 단골 문제 중 하나.
다른 쓰레드(일반적으로 I/O)가 프로미스의 동작을 실행하고 완료되면, 중단(await)지점으로 재개되어 실행한다.
프로미스는 아래에서 추가적으로 다룰 예정이다.
만약 반환 값이 있다면 어떻게 처리되어야 하는가?

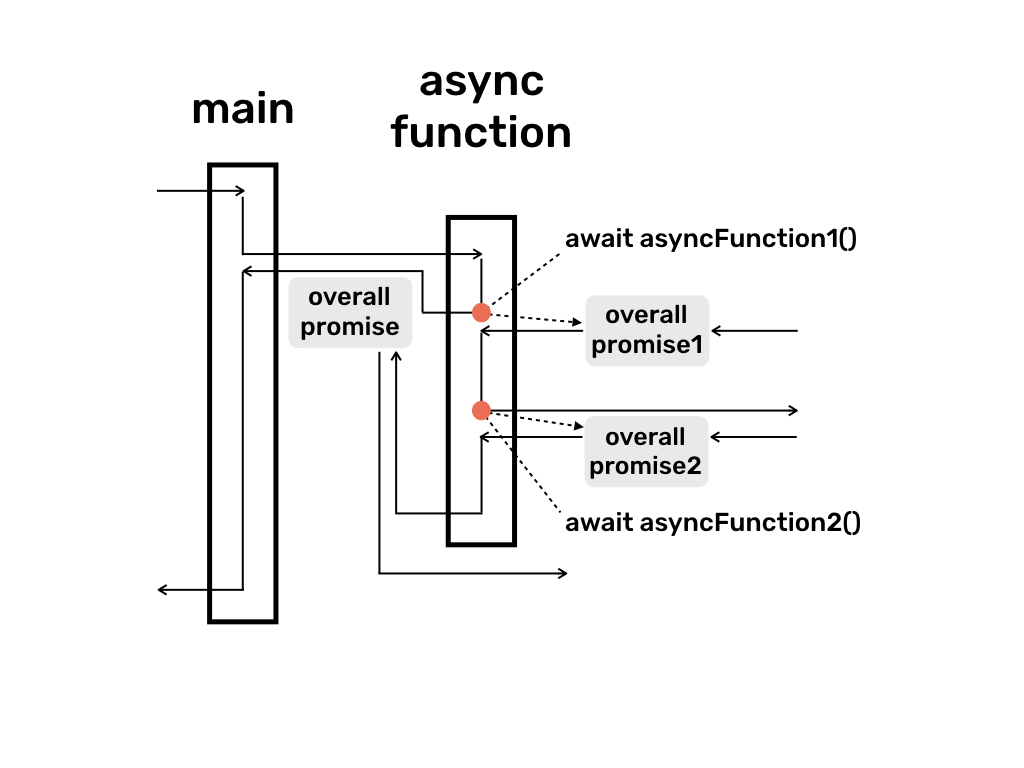
Return을 하는 Async/Await 정답은 async 함수를 프로미스로 취급한다.
타입스크립트를 해본 사람이라면 다들 알고 있겠죠.
컨티뉴에이션
컨티뉴에이션(Continuation)은 Coroutine처럼 제어흐름(Control flow)의 일종이다.
call-with-current-continuation(call/cc)를 이용하면 다음 이미지와 같이 마치 GOTO문처럼 사용할 수도 있다.
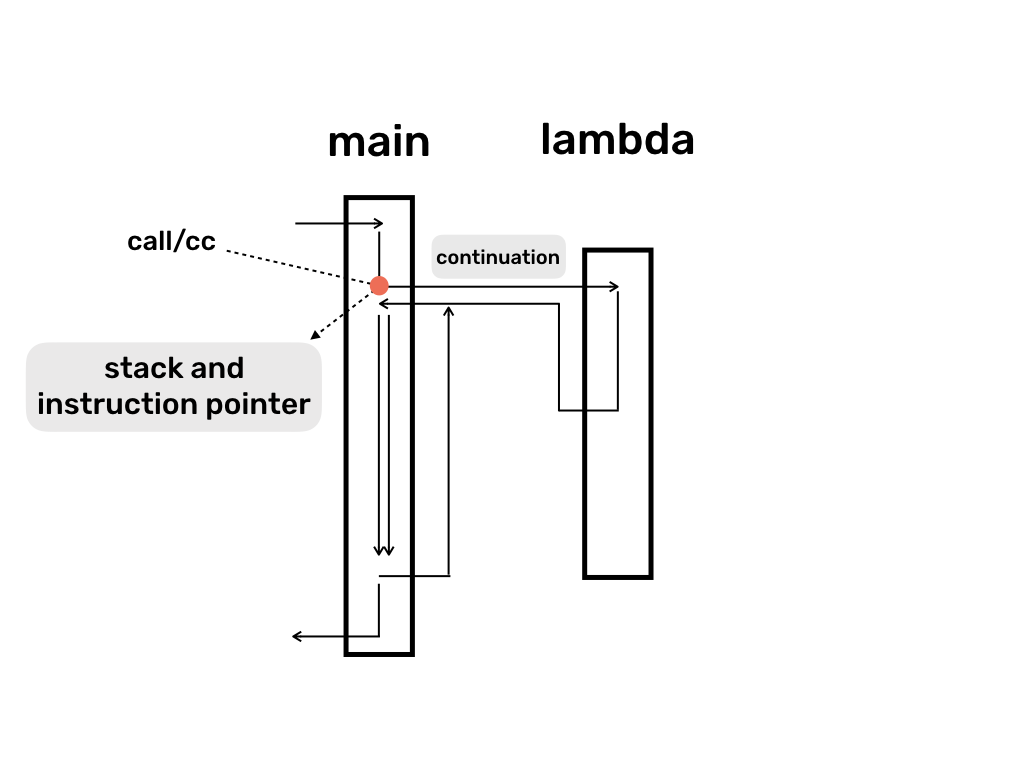
많은 설명글이 있지만 직관적이지 않다.
스텝 디버거를 개발하면서 나온 What’s in a Continuation와 F#을 이용한 Understanding continuations라는 글이 그나마 쉽게 설명되어 있다.
컨티뉴에이션의 컨셉 자체는 아주 쉽다.
대신 모든 함수형 프로그래밍이 으레 그렇듯 초반에는 쉽다가 급격히 러닝커브가 올라가는?

일반 / 컨티뉴에이션 방식 에러처리나 반환, 분기처리처리가 필요하면 함수를 실행함으로서 제어의 역전을 노리는 것이다.
그럼 처음 나왔던 call/cc 함수를 이용하는 예제를 살펴보자.
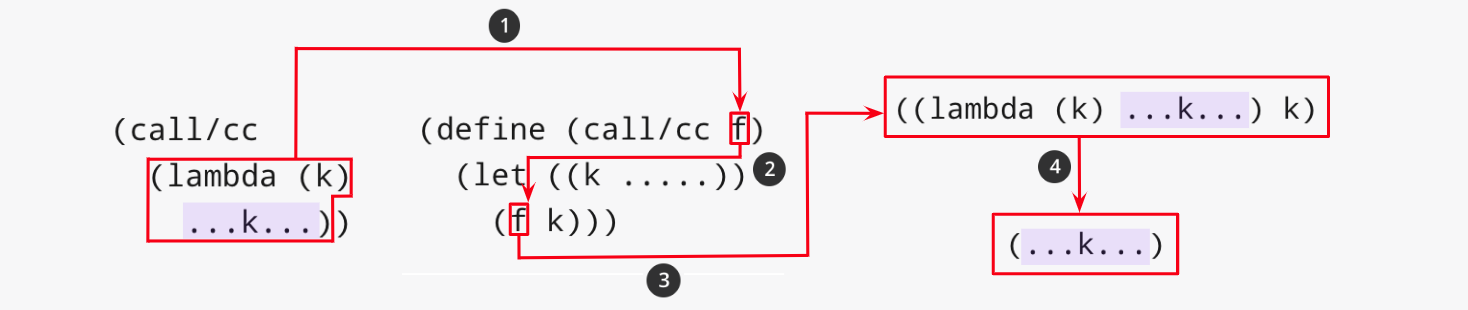
call/cc 다음 코드를 실행시키면 첫번째 console.log가 실행된 후, cont(5)에서 x의 값이 5로 할당되며 두번째 console.log는 실행되지 않는다.
분기문의 예가 될 수 있겠죠?

마찬가지로 다음의 예제에서도 두번째 배열 값에서 cont(true)가 실행되어 멈추고 x에 true가 할당된다.

그렇다면 GOTO는 어떤 방식으로 나타나는가를 살펴보자.
주요 아이디어는 내부가 아닌 외부에서 컨티뉴에이션 사용이다.
- value에 callCC의 컨티뉴에이션을 할당 [GOTO의 Label과 같은 역할]
- value는 함수니 "got a continuation!"이 출력
- value(x * 2) 실행 [GOTO 실행!!]
- value로 다시 돌아감, value에는 5 * 2로 10이 할당되어 있음
- value는 일반 값이므로 "computation finished 10"을 출력


마치 마법 같습니다.
GOTO문의 일종으로 취급될 수 있기 때문에 각종 제어흐름을 구현하는게 가능하다.
컨티뉴에이션을 활용하는 방법 중 하나인 Continuation Passing Style에 대해 알아보자.
Continuation Passing Style은 코틀린의 코루틴 구현 방식.
이번에는 Continuation Passing Style (CPS) 를 알아보자라는 글이 잘 설명되어 있다.
CPS는 꼬리재귀와 상당히 유사하다.

꼬리재귀에 관련 내용은 다음 글을 보시면 되겠습니다.
https://black7375.tistory.com/62
내 맘대로 프로그램 설계 7. - 함수형 프로그래밍.
내 맘대로 하는 프로그램 설계 시리즈. Chapter1 - 간단한 데이터 처리(4섹션) 2017/12/27 - [프로그래밍/설계] - 내 맘대로 프로그램 설계 1. - 이유와 준비. 2018/01/11 - [프로그래밍/설계] - 내 맘대로 프로
black7375.tistory.com
다만, 1, 2, 6, 24처럼 누산값(accumulator)을 전달하는 대신 컨티뉴에이션을 전달한다.
pow(제곱)함수를 컨티뉴에이션으로 반환하면 다음과 같다.

그래서 만약 다음 메인함수를 CPS 스타일로 변환한다면?

pow를 분리하여 순서를 맞추고, CPS로 변환하면 끝.



일반 유저가 사용하기에 콜백 헬이 생기기 때문에 코틀린의 예처럼 중간과정으로서 많이들 사용한다.
다음 자료에 앞선 그림자료와 예제코드까지 잘 설명되어있으니 참고바란다.
5. Promise와 Future, 스트림, 메세징
Promise / Future
Promise(약속)과 Future(미래,
선물)는 비동기 프로그래밍에서 항상 등장한다.둘은 생산자-소비자 관계라고 생각하면 쉽다.
이른바, 미래에 어떠한 데이터를 돌려주겠다는 약속.

- 퓨처: 읽기 전용으로 아직 계산되지 않은 값이다
- 프로미스: 퓨처가 참조하는 한번 결과를 할당 가능한 가능한 값이며, CompletableFuture나 Completer로도 불리기도 한다.
사용하게 된다면 다음과 같이 표현할 수 있다.

참고로 MPSC(Multi-producer, single-consumer)와 같은 용어를 본 적이 있을 것이다.
- M은 멀티, S는 Single
- P는 생산자, C는 소비자
관계이다.
Stream / Buffer
이번에는 커다랗거나 연속된 데이터를 다룬다고 생각해보자.
통으로 처리하거나 전달하기보다 덩어리(Chunk) 단위로 다루기를 원할 것이다.
스트림(Stream)은 연속적인 데이터 흐름이다.

Introduction to NodeJS Streams
- 시간 효율적: 모든 데이터를 사용가능할 때까지 기다릴 필요가 없음
- 공간 효율적: 모든 데이터를 사용하지 않기 때문에 필요한 메모리가 적음
그럼 임시적으로 데이터를 담아놓는 버퍼(Buffer)가 왜 필요할까?
- 전달이 빠름: 데이터를 바로 처리할 수 없기 때문에 저장
(비디오 다운로드가 보는 속도보다 빠를때 미리 저장해둠) - 전달이 느림: 처리할 크기가 될 때까지 저장
(연결이 느릴때 0.1초 단위로 비디오를 보여주기보다 1~2초단위로 보여주기 위해 저장)
버퍼는 일종의 큐이며, 보통 지정된 크기/길이를 가진다.
혹시 동기/비동기와 헷갈린다면 다음 그림을 참고해보자.
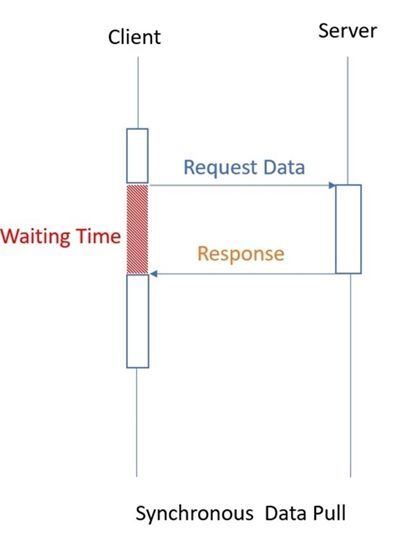
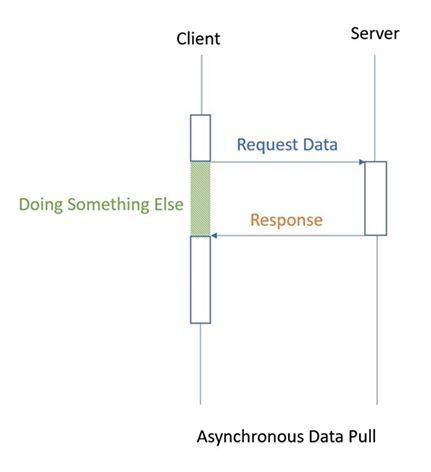
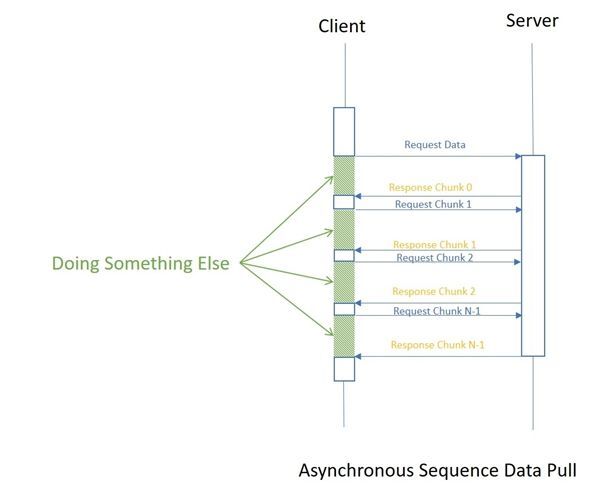
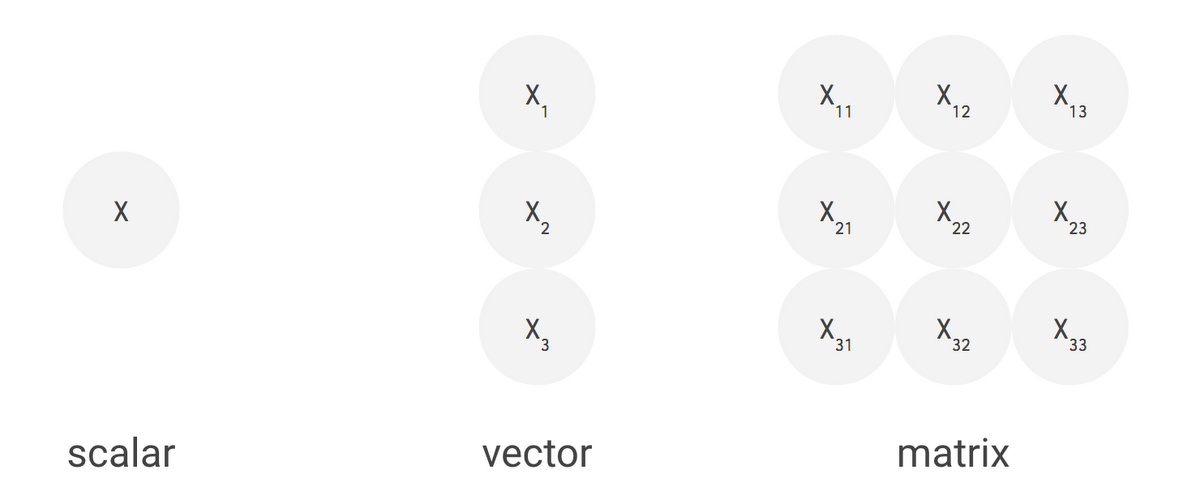
Stream은 전체 데이터를 나눠서 처리할 수 있음 한마디로 단일값과 벡터의 차이다.
Push / Pull
- What's the difference between push and pull protocols?
- Node.js Readable streams distilled
- Async streams in C# – Deep Dive
스트림처럼 연속된 데이터를 주고 받을때 필요한 개념이다.
Pull과 Push는 생산자와 소비자의 통신방식이다.
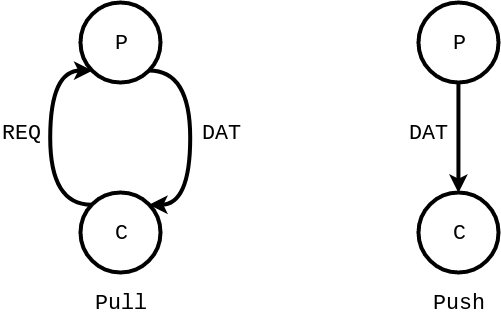
pull / push - Pull: 소비자가 요청하면 데이터를 줌
- Push: 생산자가 데이터를 주면 받아서 씀
Pull은 동기, Push는 비동기에 가깝다고 보면 된다.
역시 서로 유리한 지점이 다르다.
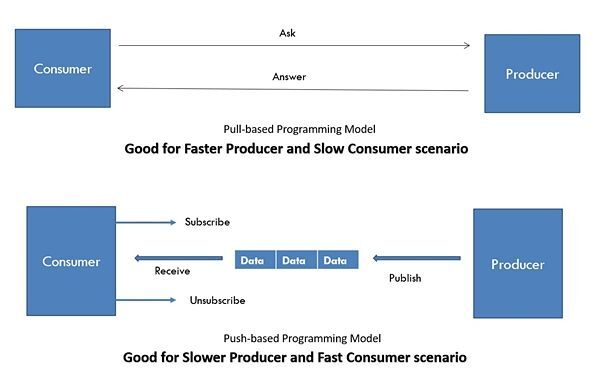
Pull/ Push - Pull: 요청이 들어오면 바로 데이터를 제공해야 하므로 빠른 생산자가 있을 때 유리
- Push: 데이터를 주면 바로 소비할 수 있는 빠른 소비자가 있을 때 유리
Push의 대표적인 예는 Promise와 Observable가 있다. [반응형 프로그래밍과 RxJS, The ultimate guide to Observables and/vs Promises (+RxJS7)]

Observable은 여러 값의 지연 푸시 컬렉션 앞서 스트림에 나온 Asynchronous Sequence Data Pull은 Async Iterator의 동작방식이나 다름없다.
Sub / Pub
그럼 생산자나 소비자가 여러개일 때 직접이 아닌 간접적으로 연결하고 싶다면 어떻게 될까?
ZeroMQ의 문서가 아주 잘 되어 있다.

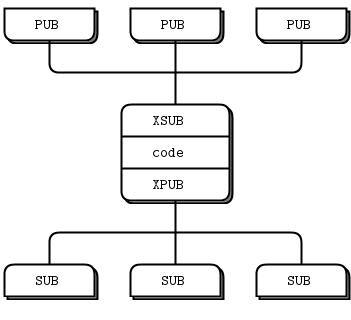
Pub / Sub 직접 연결인 Observer 패턴과 비교해보자.

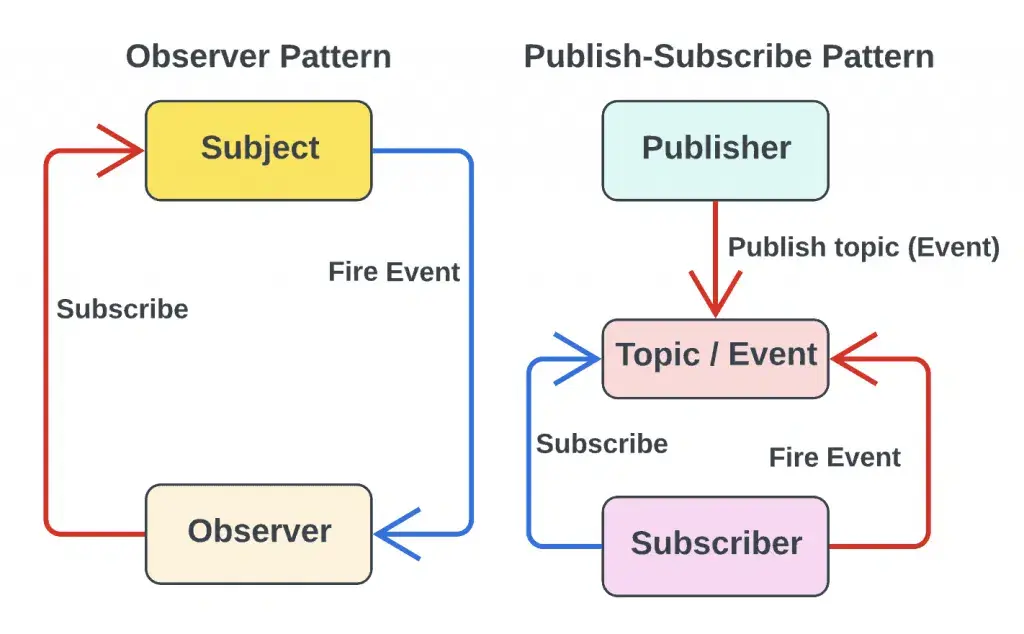
Observer vs Publisher-Subscriber Pattern, Observer vs. Pub-Sub Pattern: What is the Difference
ZeroMQ의 특이한점은 메세지 브로커 대신 소켓의 Wrapper로 해결하려 한다는 점.
큐 / 버스 / 브로커
중간의 역할에 있어서 여러 구분에 혼동이 올 수도 있다.
이렇게 정리해보자. [Event Queues, Event Bus Implementation(s), Event Driven Architecture – The Basics, EventBroker: a notification component for synchronous and asynchronous, loosly coupled event handling, The Engineers Guide to Event-Driven Architectures: Benefits and Challenges]
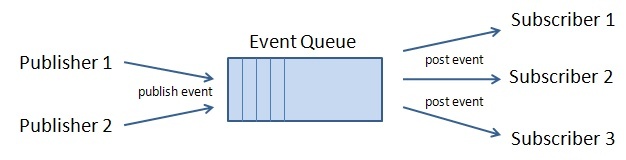
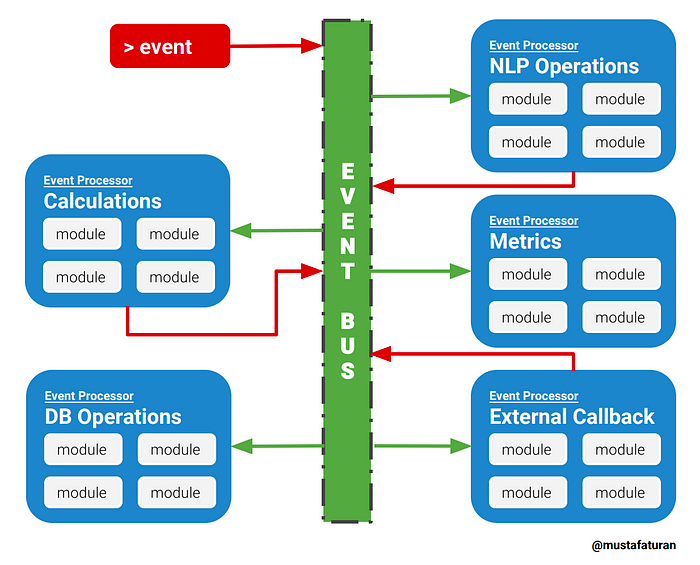
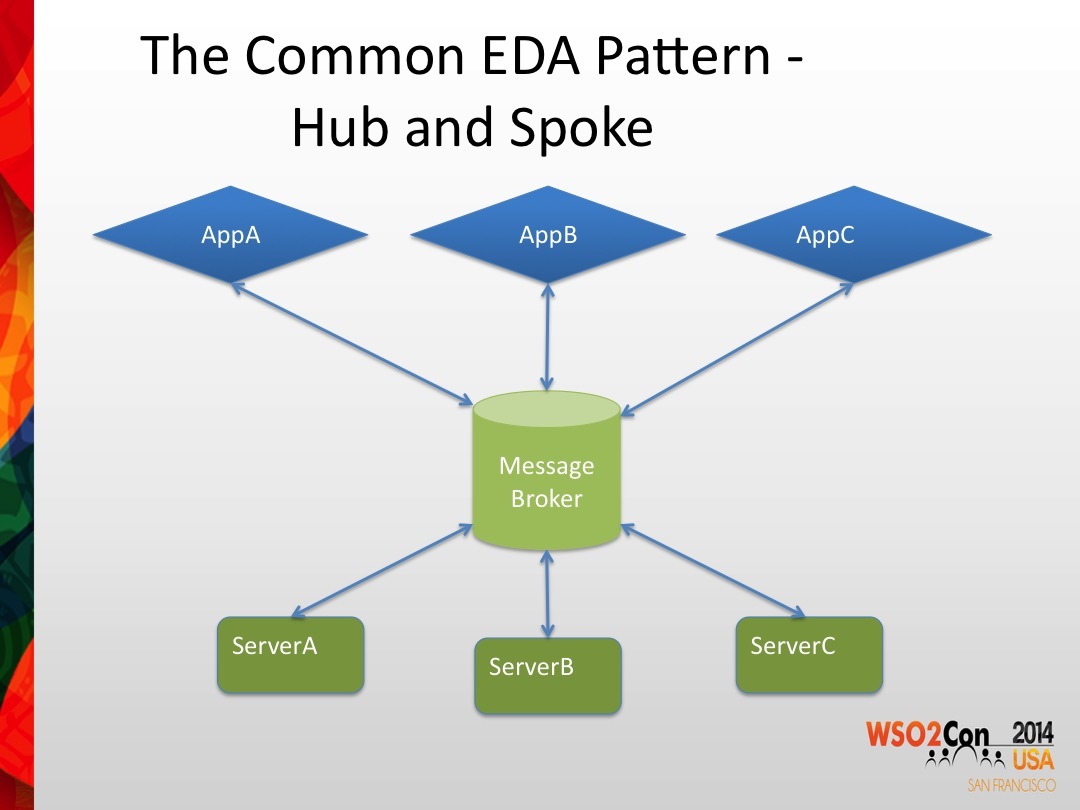

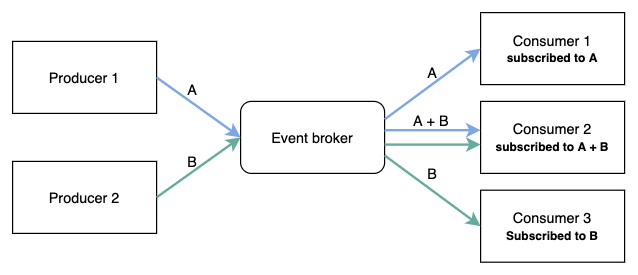
- 큐: 선입선출(FIFO)이 보장됨
- 버스: 여러 생산자가 있을 경우, 모든 내용은 공유됨, FIFO를 보장하지 않을 수도 있음
- 브로커: 일종의 허브로서 라우터 역할을 함
메세지 / 이벤트
이쪽은 헷갈리는 개념이 참 많다.
- 메세지: 다른 곳에서 사용하거나 저장하기 위해 서비스에서 생성한 원시 데이터
- 이벤트: 조건 또는 상태 변경에 대한 간단한 알림
이라고 한다.
일반적으로 메세지 중심의 경우 메세지가 중간에 사라지지 않고 처리하기를 기대하기 때문에 Pull에 가깝고,
이벤트 중심은 알림을 보낸 후 처리를 신경쓰지 않으므로 Push에 가깝다.
반응형 프로그래밍쪽에서는 세분화해 4~5가지 유형으로 나누기도 한다. [Types of Messages in Message-Driven Systems, Message Driven vs Event Driven]
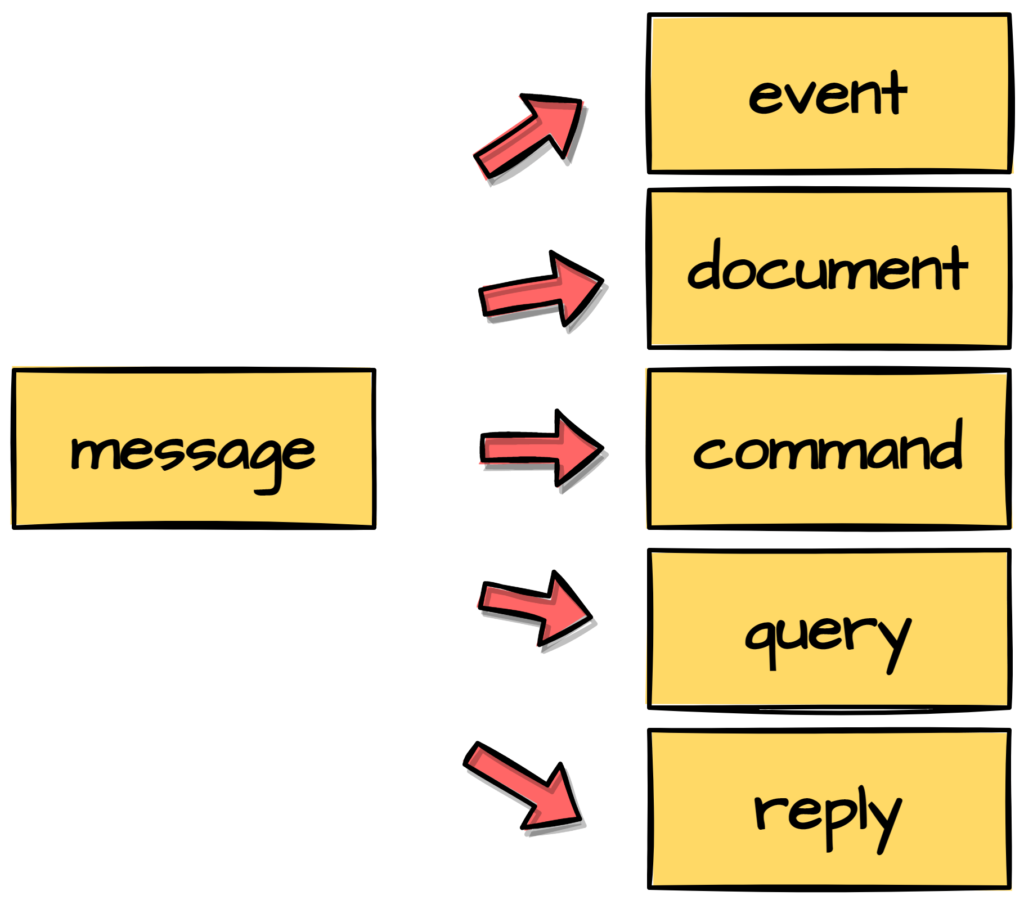
- 이벤트: 상태가 변경되었을때 내보내는 메세지
- 문서: 데이터를 처리하기 위해 제공하는 메세지 [문서는 이벤트와 다르게 타이밍의 중요성이 떨어지며 안전하게 전달함에 집중]
- 명령: 상태를 변경하기 위해 보내는 메세지
- 쿼리: 정보를 얻기 위해 보내는 메세지
- 회신: 명령 혹은 쿼리의 응답 메세지 [엄격하게 해석하면 쿼리에 대한 응답만 치는 경우도]
이외 궁금한 점이 있다면 Messaging Patterns 사이트를 참고해보자.
메세징 프로덕션 제품들
프로덕션 제품들은 여러가지 개념들을 섞거나 보완하기 마련이다.
종류가 많지만 유명한건 Kafka, RabbitMQ, ActiveMQ, ZeroMQ일 것이다. [Kafka vs ActiveMQ vs RabbitMQ vs ZeroMQ]
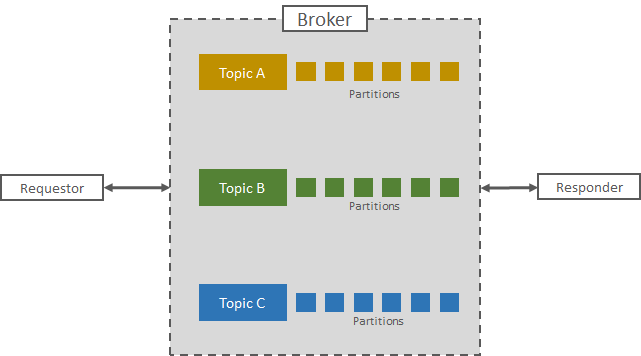
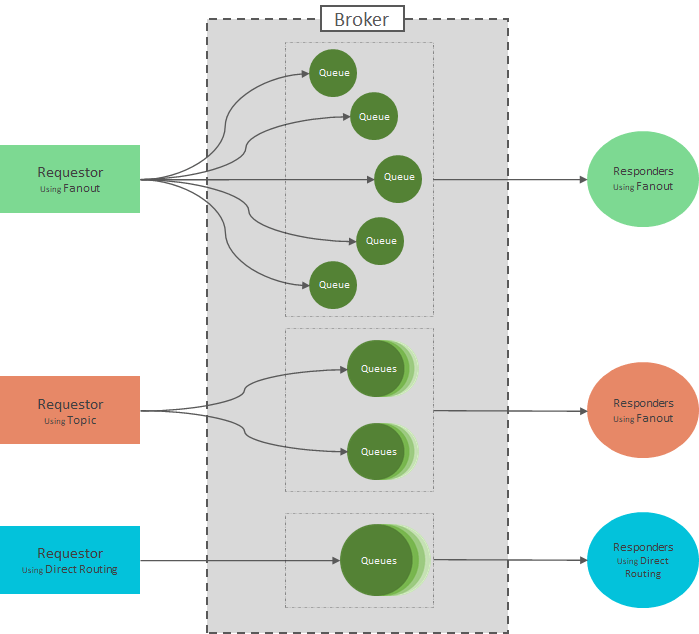


Kafka
Kafka에는 토픽으로 나뉘어 저장된다. [Kafka, Part 1: Apache Kafka for beginners - What is Apache Kafka? ]
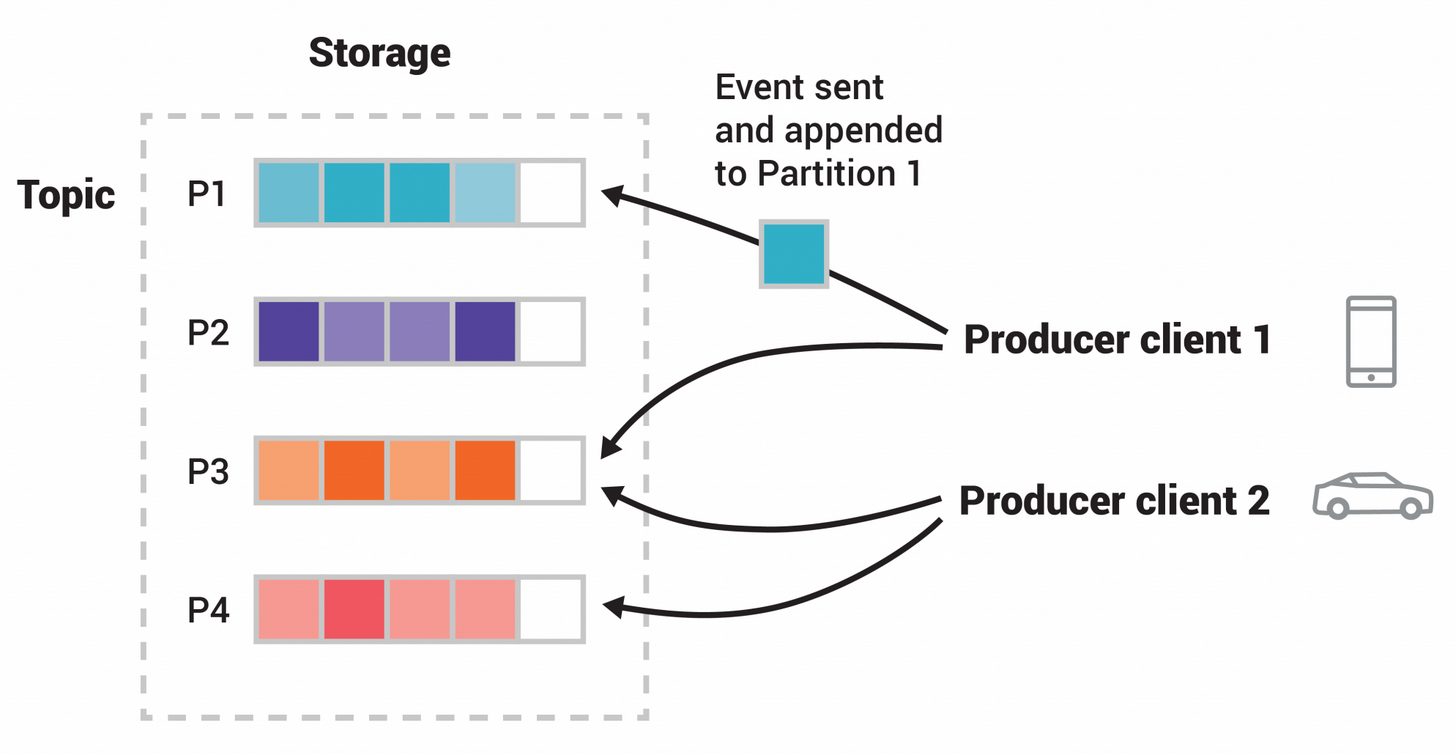
로그의 압축이 가능하다는 것도 특징

RabbitMQ
RabbitMQ의 브로커는 교환과 큐로 이루어져 있다. [Part 1: RabbitMQ for beginners - What is RabbitMQ?]
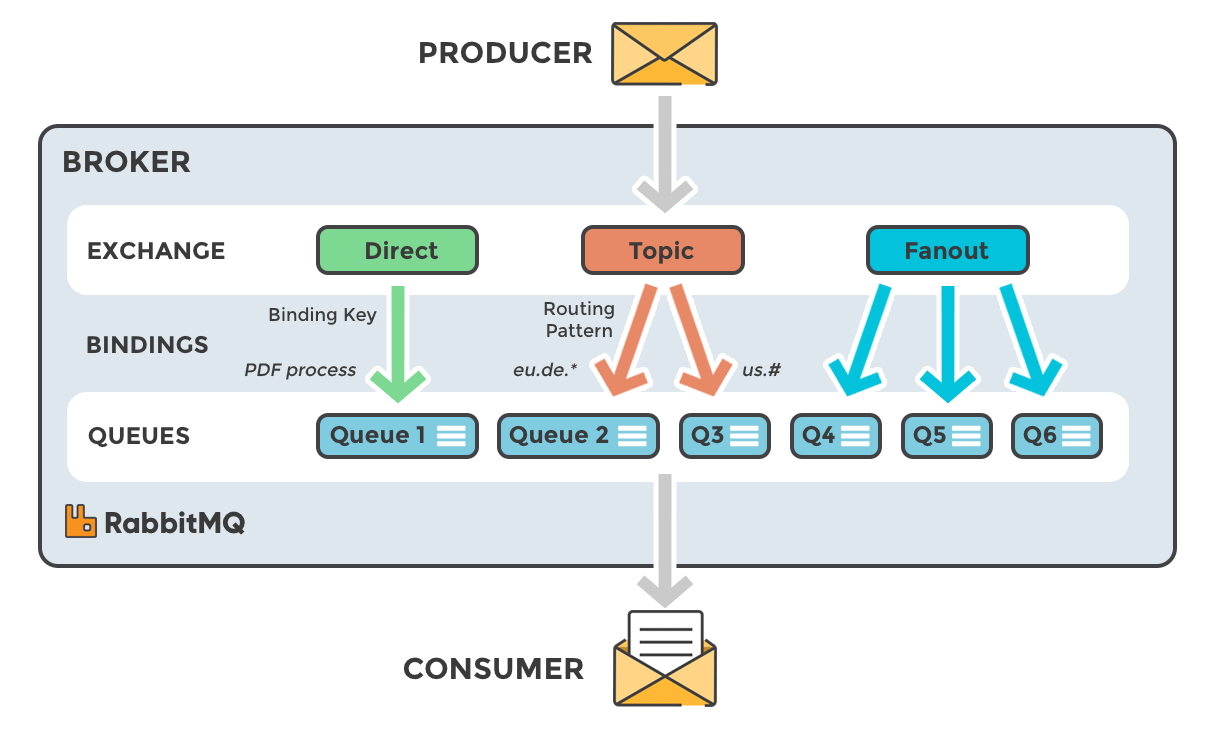
ZeroMQ
아까 나왔듯, ZeroMQ는 Socket의 Wrapper로 작동한다. [ZeroMQ vs Kafka]
6. I/O 멀티플렉싱
멀티플렉싱
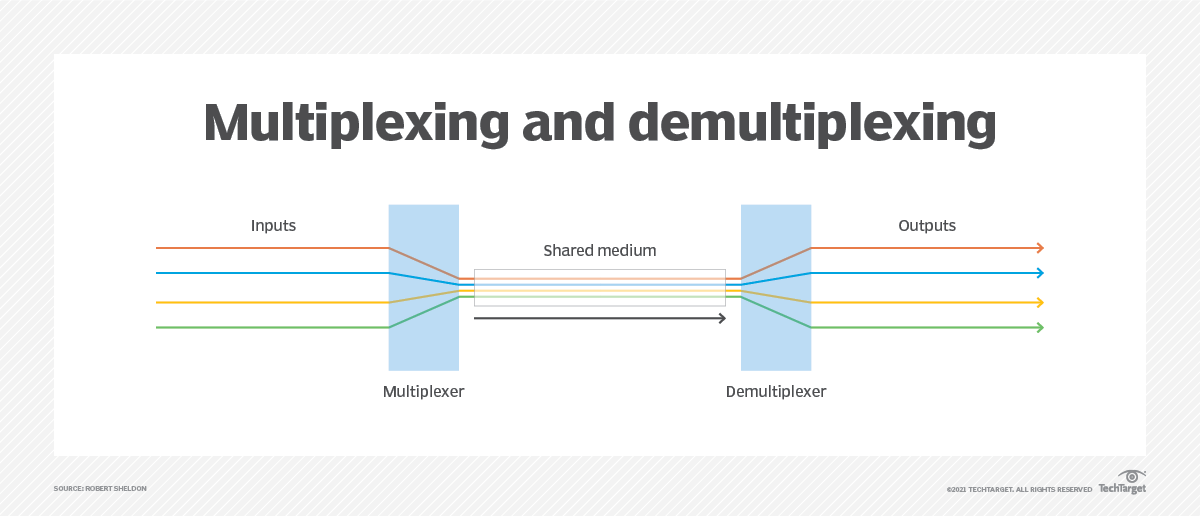
멀티플렉싱(Multiplexing, 다중화)는 여러 신호를 하나로 묶어서 전달하는 기법이다.
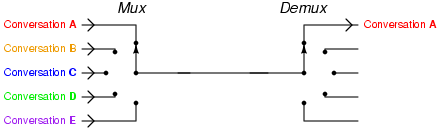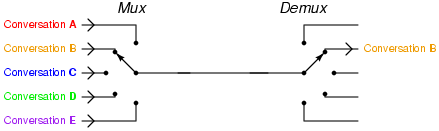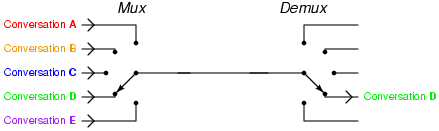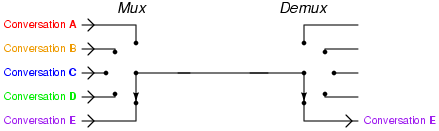
시분할 한정된 채널을 효율적으로 사용할 수 있게된다.
일반적인 통신에서 주파수 분할이나 시분할 기법등이 쓰이며, 컴퓨터 통신에서는 HTTP2.0이 대표적인 예.
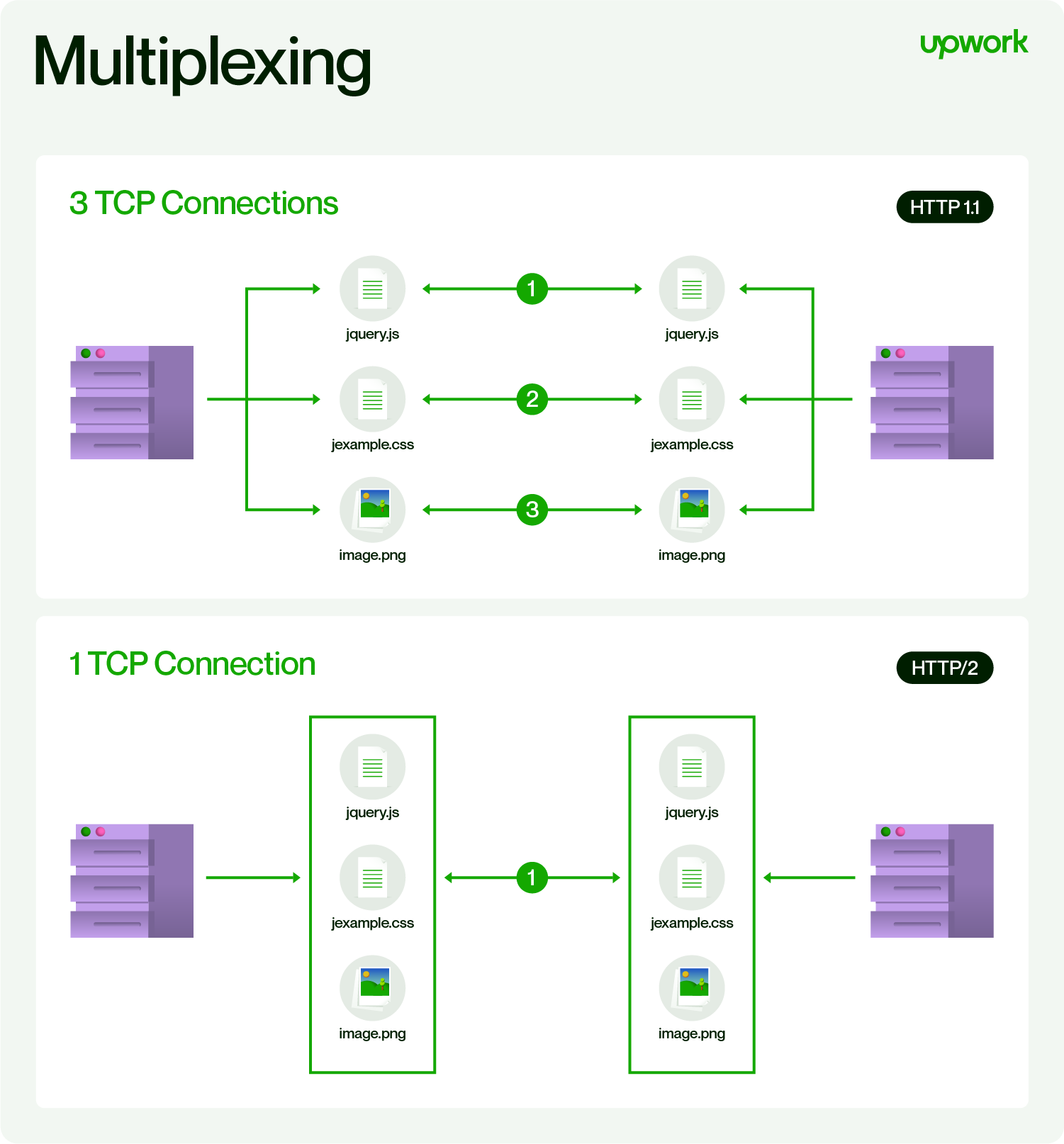
What is the HTTP/2 Protocol? Overview and Examples
멀티 플렉싱 기법은 채널을 효율적으로 사용하기 위해 여러신호를 묶는 기법이기 때문에 데이터 용량이 많거나 연속적일때 적합하지 않을 수도 있다.
- 클라이언트와 서버간의 송수신 데이터 용량이 작은 경우 적합
- 송수신이 연속적이지 않은 경우에 적합
- 멀티 프로세스 기반에 비해 많은 수의 클라이언트 처리에 적합
여러 커넥션 생성시 비용은 멀티프로세스 > 멀티쓰레드 > 멀티플렉싱 순이다.


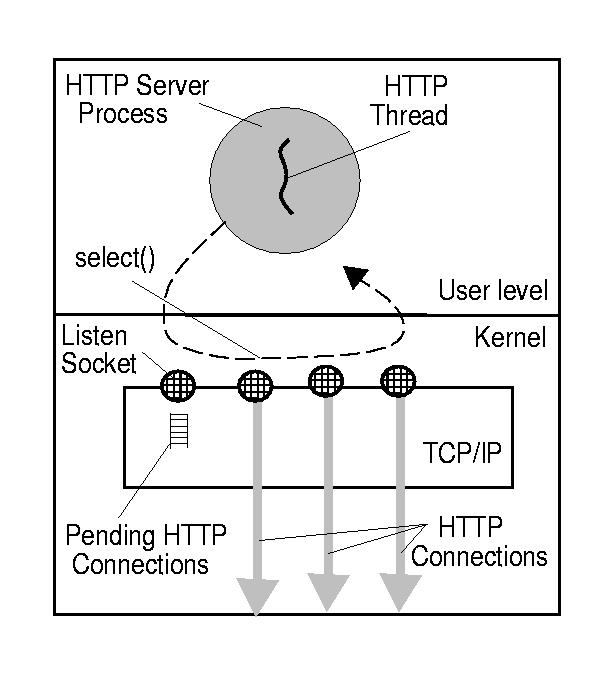
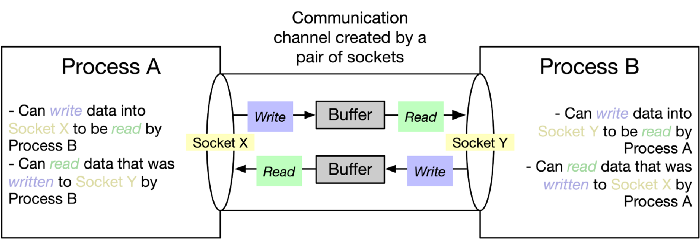
소켓
소켓은 프로그램간 양방향 통신의 엔드포인트다.
소켓에 데이터를 적으면, 데이터 전송은 소켓이 수행해준다. (낮은 레이어의 통신에 대한 일종의 추상화)
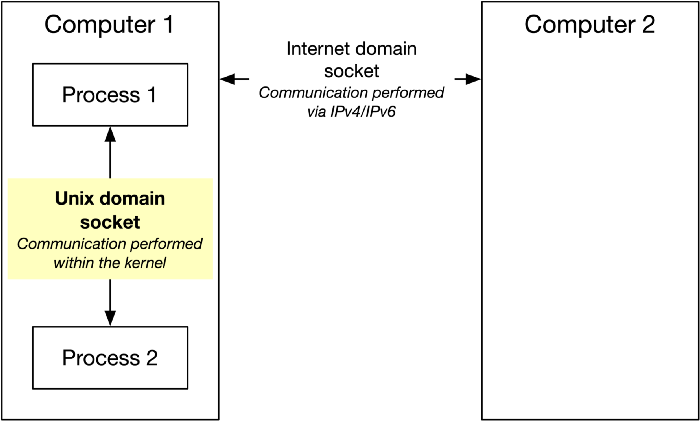
인터넷 접속 시 사용되는 네트워크 소켓과 프로세스간 IPC를 위한 유닉스 도메인 소켓으로 나눌 수 있다.
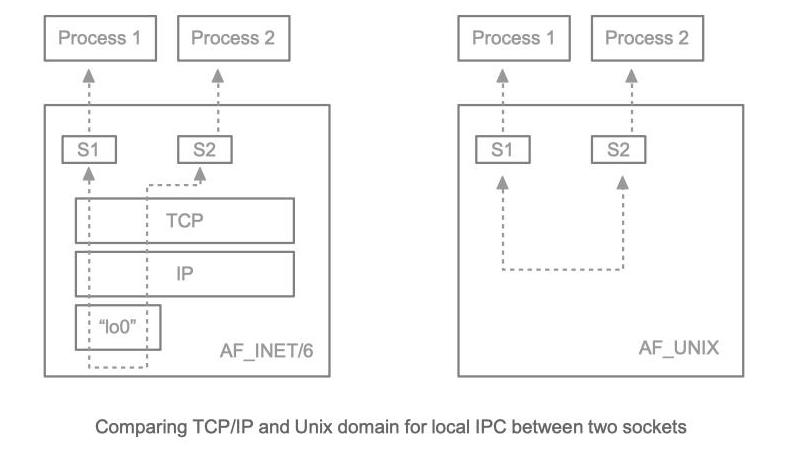
JEP-380: Unix domain socket channels
당연하겠지만 유닉스 도메인 소켓이 더 가벼운 편.
서버와 클라이언트 소켓은 다음과 같은 생명주기를 가진다.
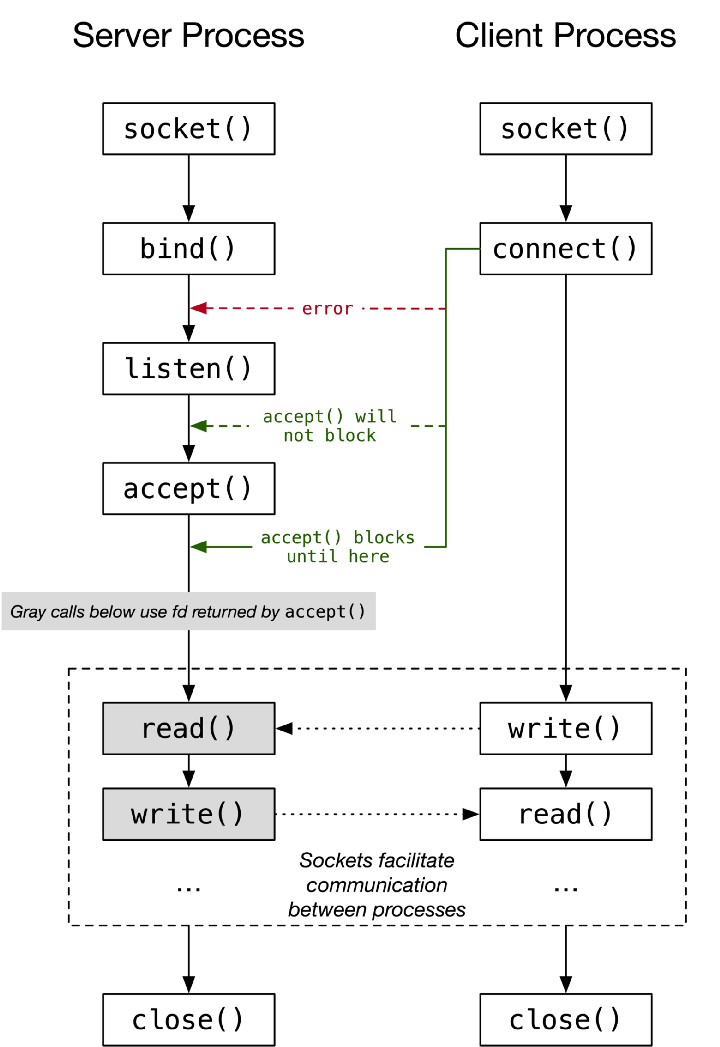
유닉스는 파일과 소켓 조작을 동일하게 간주하며, fd(File Descriptor)로 표현한다.
(윈도우는 소켓 API가 따로 존재)
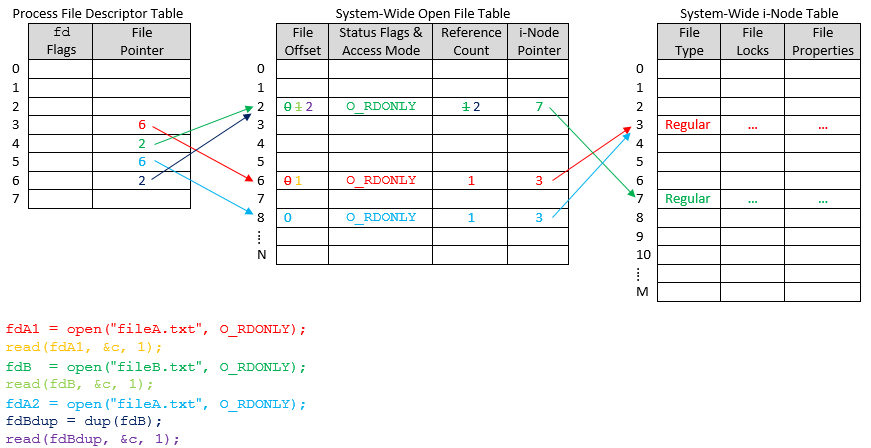
UNIX File Descriptors An Introduction
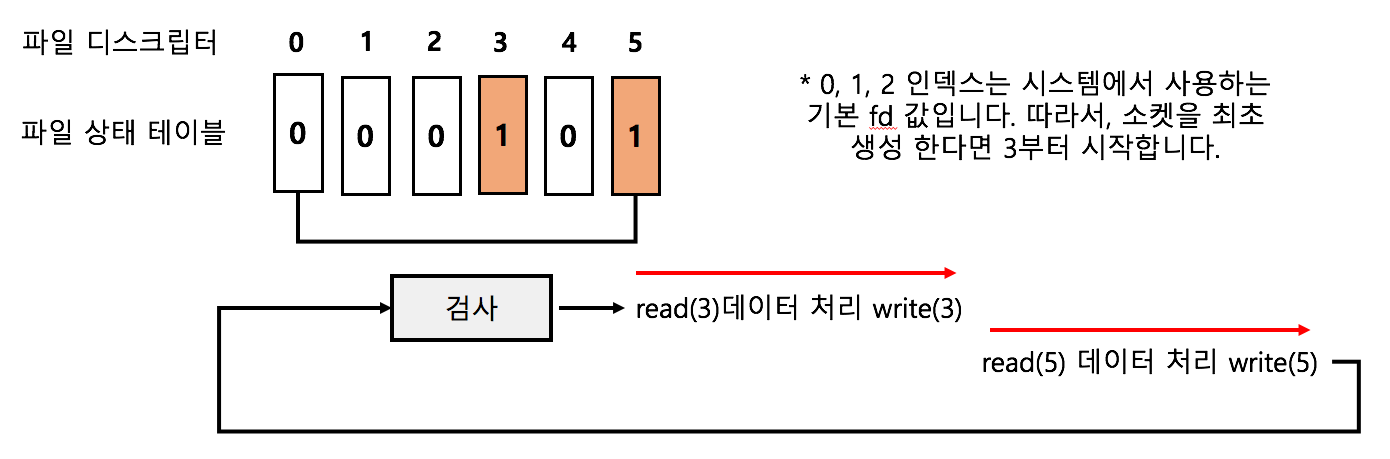
파일 디스크립터는 0(임력), 1(출력), 2(에러)로 정해져 있으므로 3번부터 실제 파일이 시작된다.
I/O 모델들
IO Multiplexing (IO 멀티플렉싱) 기본 개념부터 심화까지와 I/O Model이라는 글이 잘 설명해주고 있다

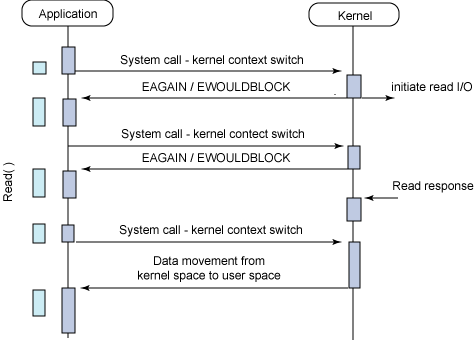
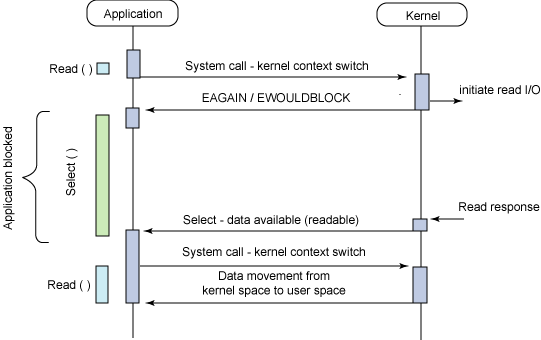
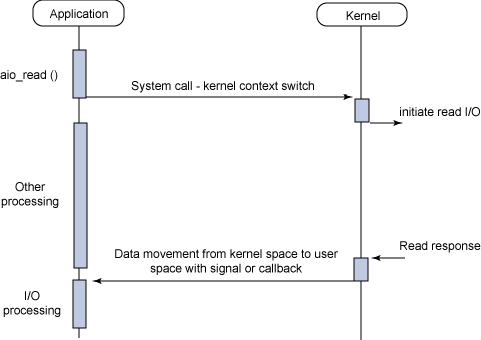
동기-블럭킹 / 동기-논블럭킹 / 비동기-블럭킹 / 비동기-논블럭킹 - 커널이 메세지를 반환해야지만 처리할 수 있는 동기 블럭킹 I/O
- system call을 통해 반복적으로 확인(폴링)해야해 컨텍스트 스위칭 오버헤드가 있는 동기 논블럭킹 I/O
- 한번에 많은 fd를 처리할 수 있지만 select와 read로 두번의 시스템 콜이 발생하고 비동기 블럭킹 I/O
- 결과를 마치 이벤트처럼 전달받을 수 있는 비동기 논블럭킹 I/O
그러나 리눅스에서는 동기 I/O가 충분히 빠르고 AIO시 지연 때문에 Epoll을 주로 사용
select가 대표적인 멀티플렉싱 I/O 모델로 3번째인 비동기 블럭킹 I/O다.
체크할 파일 디스크립터 목록을 배열로 만들어놓고, select에서 반환되면 순회하여 데이터를 처리한다.
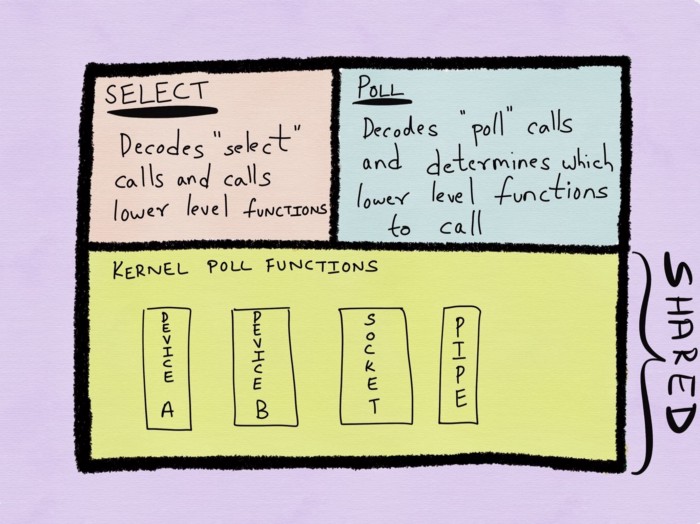
Epoll(리눅스), Kqueue(BSD), IOCP(Windows)가 더 발전된 방법이다.
Epoll은 유저 스페이스 단이 아닌 커널 단에서 멀티플렉싱을 지원하고 변경된 목록을 반환한다.
따라서 상태가 변경되었는지 매번 디스크립터 목록을 순회할 필요가 없으며, 커널에서 상태 정보를 유지하므로 관찰할 파일의 정보를 매번 전달할 필요가 없다.
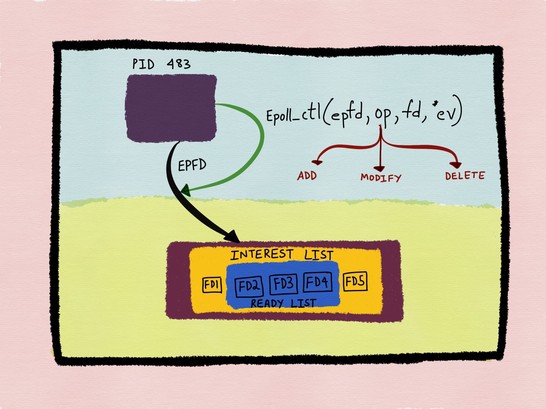
Kqueue는 FreeBSD에서 사용되며 kevent를 담은 kqueue를 사용한다. [Kqueue: A generic and scalable event notification facility, kqueue和FSEvents, HN, Scalable Event Multiplexing: epoll vs. kqueue]
Epoll과 비교하자면 소켓과 파이프I/O만 지원하는 Epoll과 달리 signal, timer등 다양한 타입들을 지원한다.
또한 kevent()는 단일 시스템 콜로 여러개의 업데이트를 한번에 수행할 수 있다.(Epoll은 매번 epoll_ctl()을 사용해야 함)
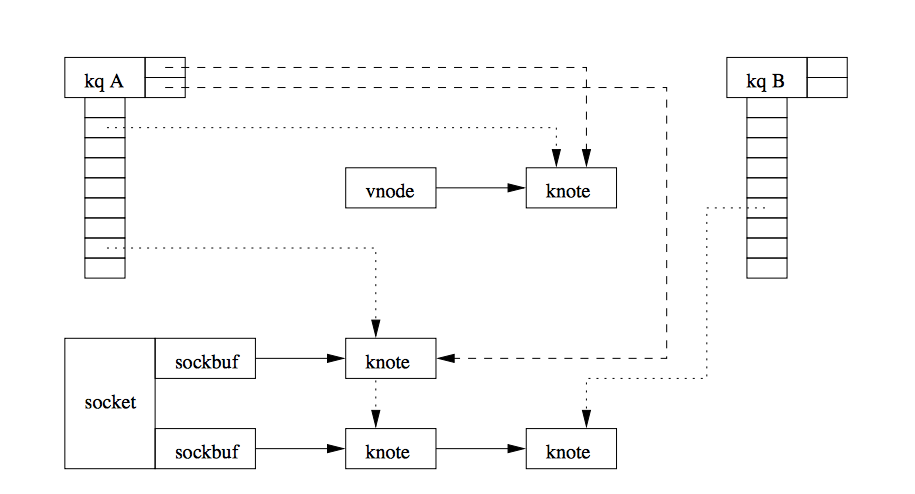

윈도우의 IOCP(I/O Completion Ports)는 멀티쓰레드로 동작하며 4번 비동기-논블럭킹 모델이다. [Iocp 기본 구조 이해, Windows IOCP vs Linux EPOLL Performance Comparison, Windows Registered I/O (RIO) vs IOCP]

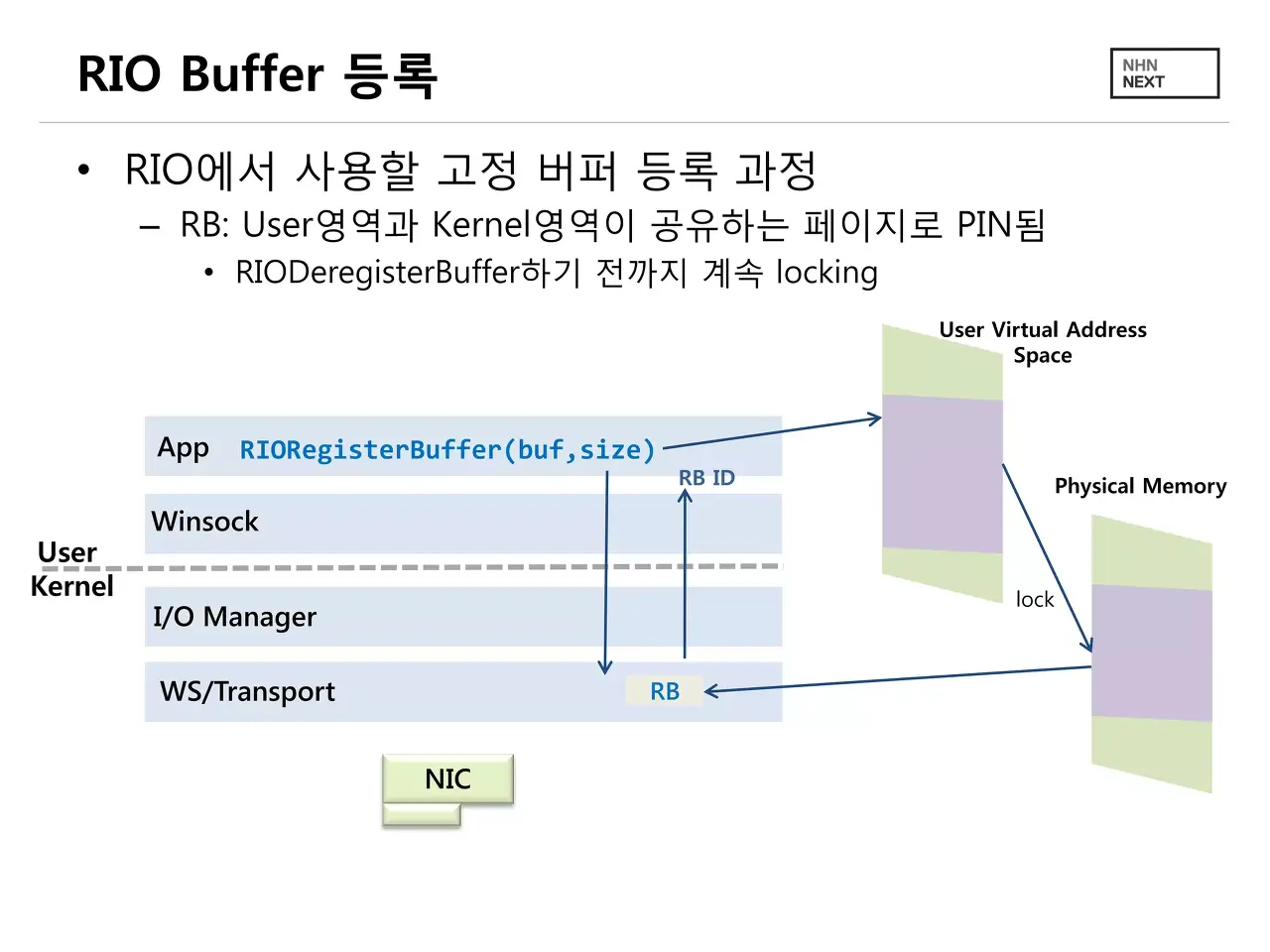
IOCP 윈도우 RIO(Registered I/O)는 한번 더 나아가, 고정 크기의 버퍼를 등록해 컨텍스트 스위칭을 낮출 수 있다.
물론 코딩은 어려워짐을 감안해야 한다.
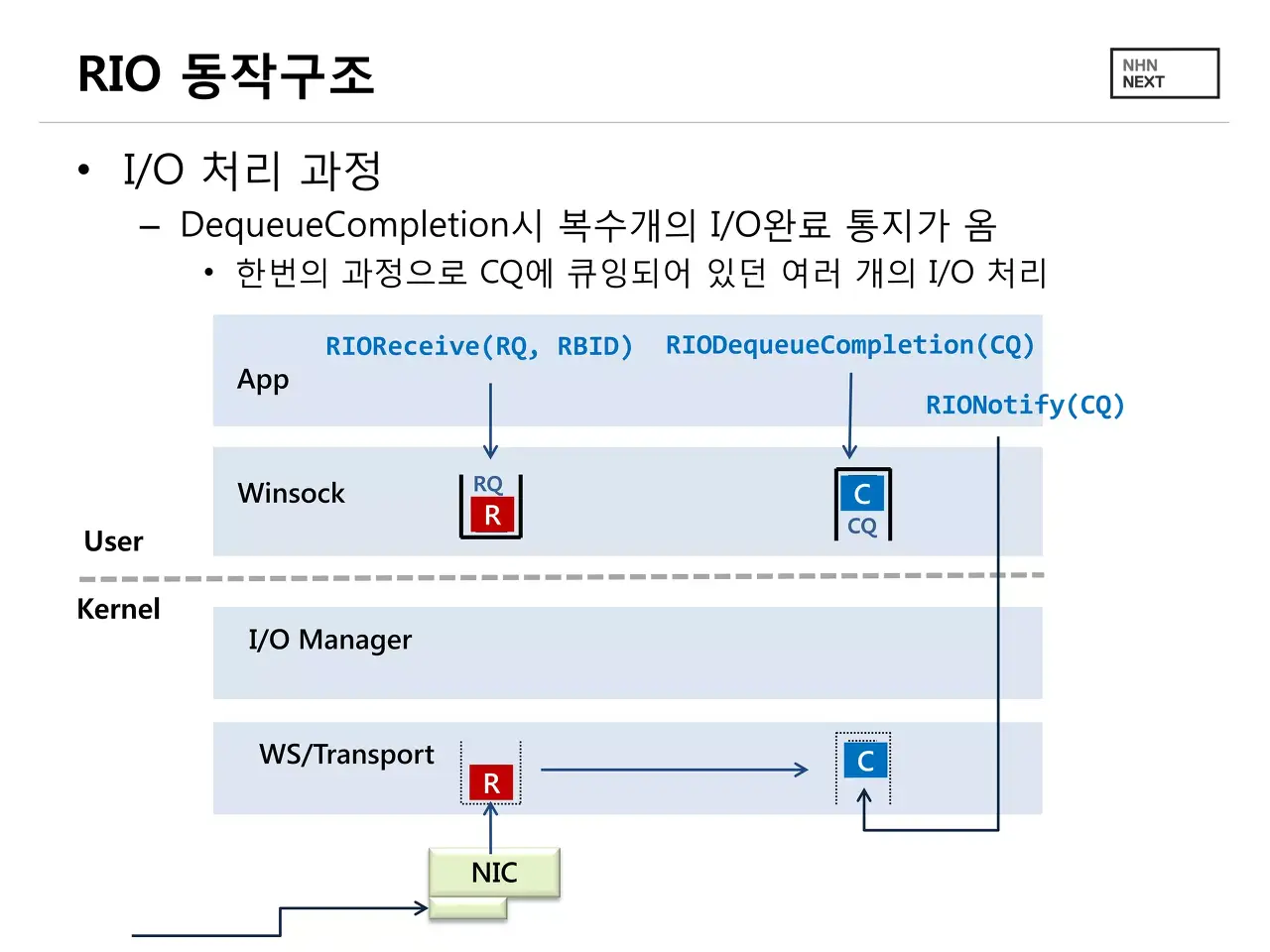
등록과 동작 7. 링버퍼, 최신 I/O 모델, LMAX Distruptor
링버퍼
링버퍼는 성능 저하없이 배열을 dequeue처럼 사용할 수 있다.
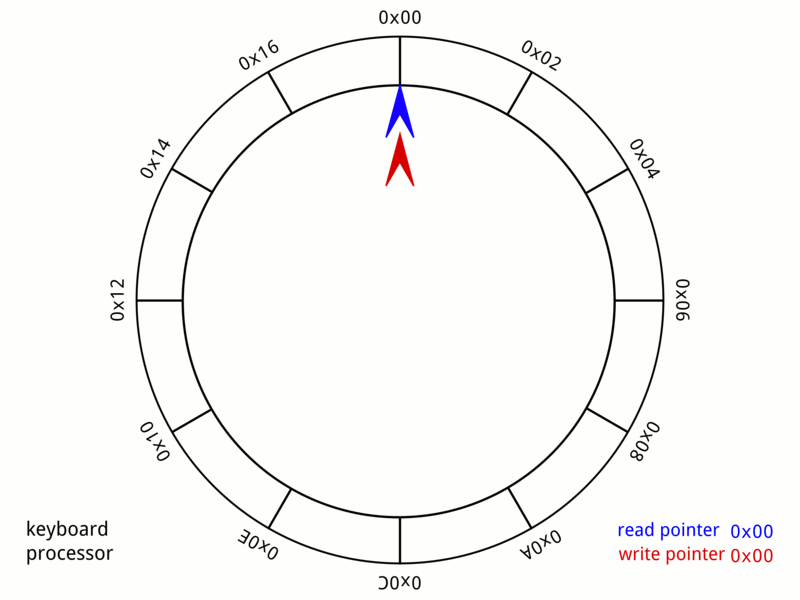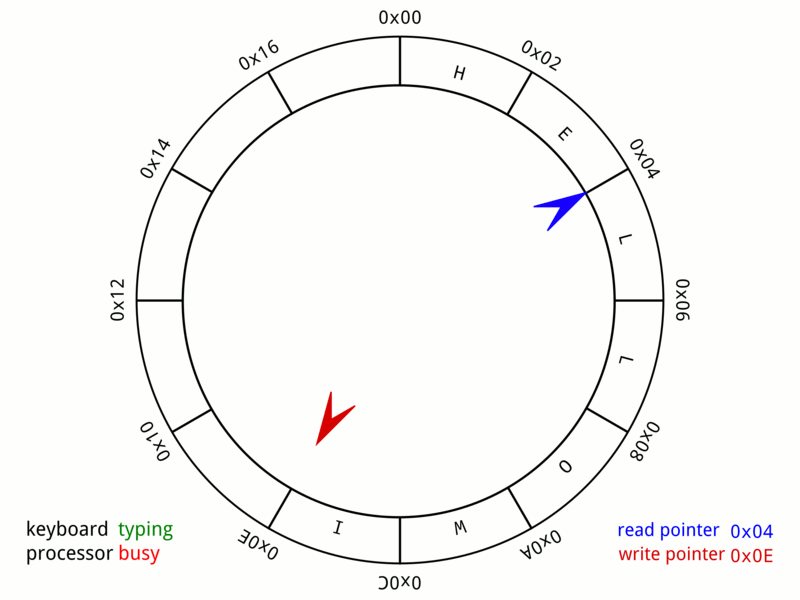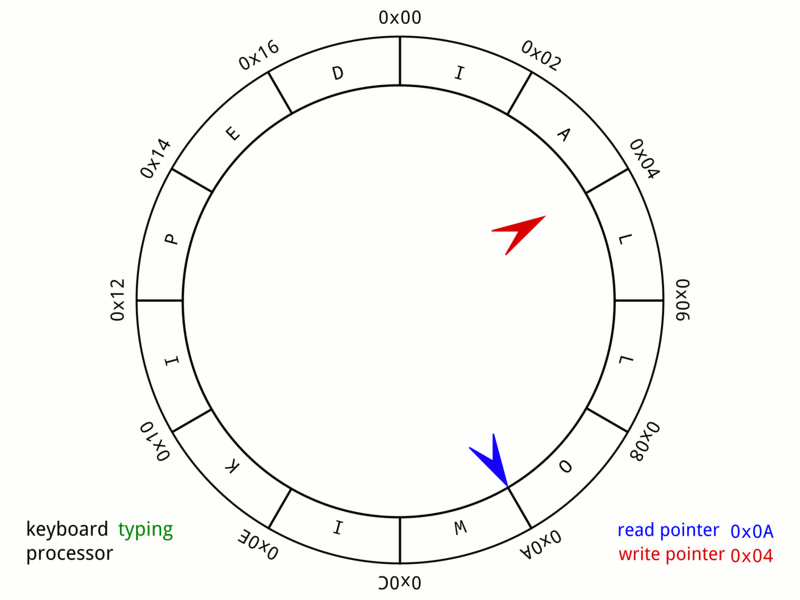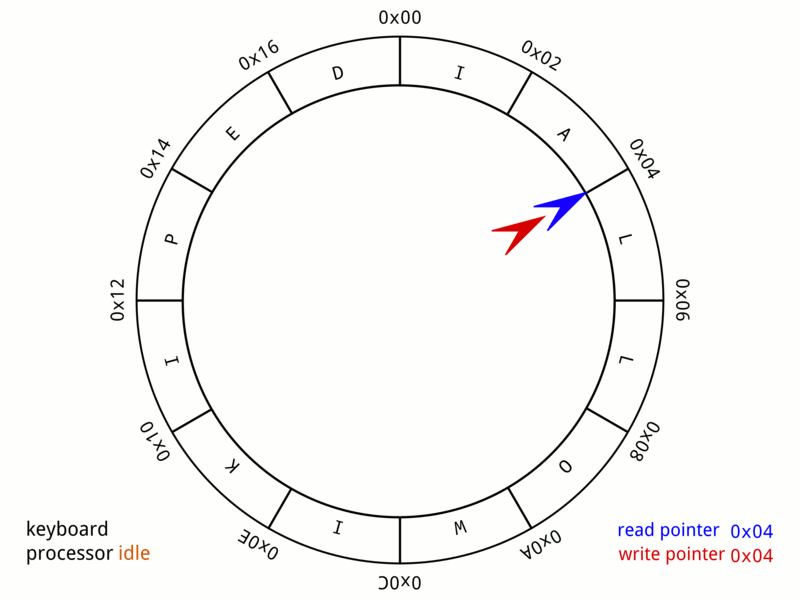
링버퍼 최신 I/O 모델
리눅스(io_uring)와 윈도우(IoRing) 모두 차세대 I/O모델로 택하고 있다. [IoRing vs. io_uring: a comparison of Windows and Linux implementations]
아이디어는 유저 스페이스와 커널 스페이스가 공유하는 공간을 만들어 컨텍스트 스위칭시 복사비용을 현격하게 낮추는 것.
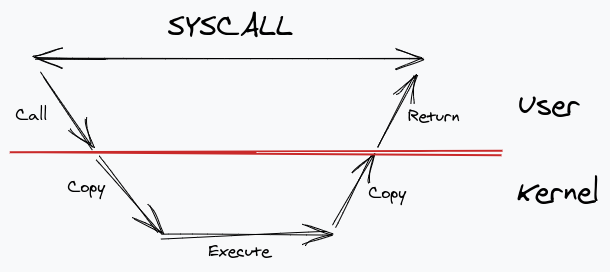
Getting Hands on with io_uring using Go
SQ(submission queue) 버퍼에는 유저 스페이스에서만 쓰기가 가능하고, CQ(completion queue)에서는 커널 스페이스에서만 쓰기가 가능하다.
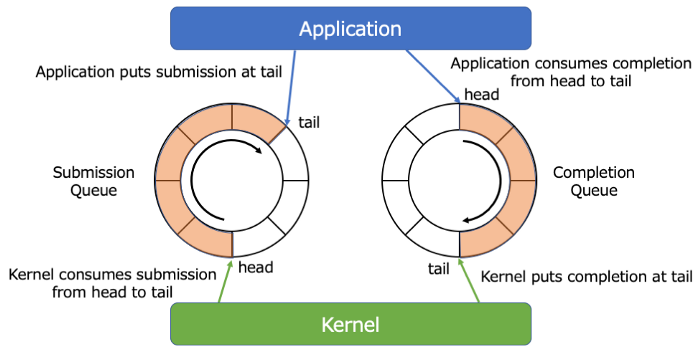
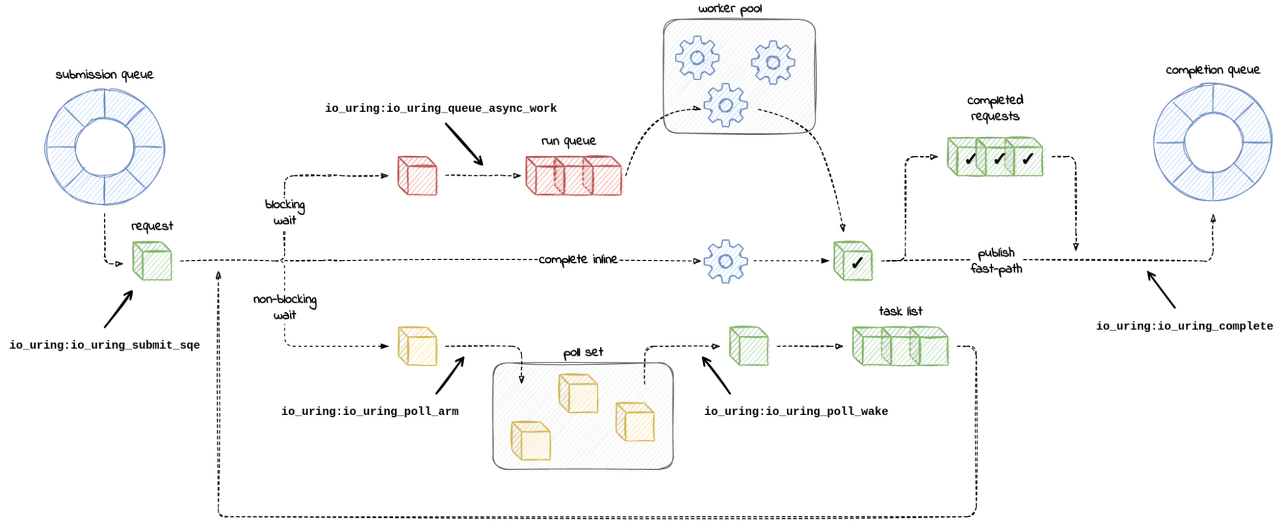
Missing Manuals - io_uring worker pool
LMAX Disruptor
LMAX Disruptor는 데이터를 전달 시 큐를 이용할때 지연시간을 줄이기 위해서 만들어졌다.

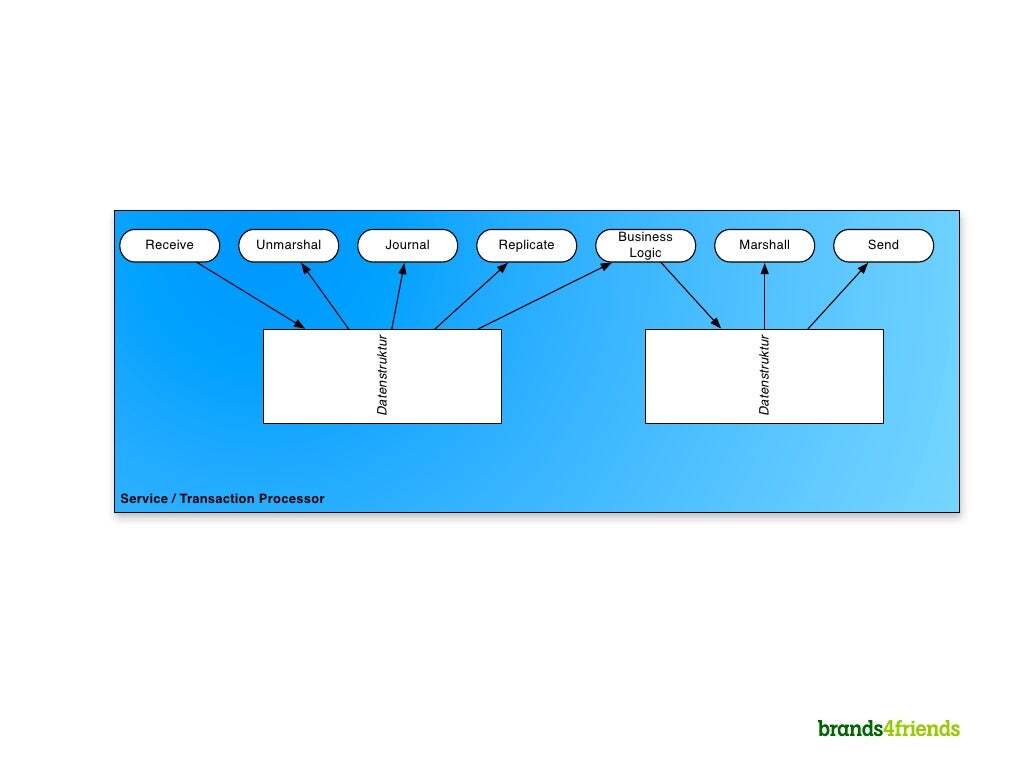
왼쪽에서 오른쪽 처럼 그러기 위해 링버퍼를 택했다.
전반적인 아이디어는 IO Uring과 일치한다.

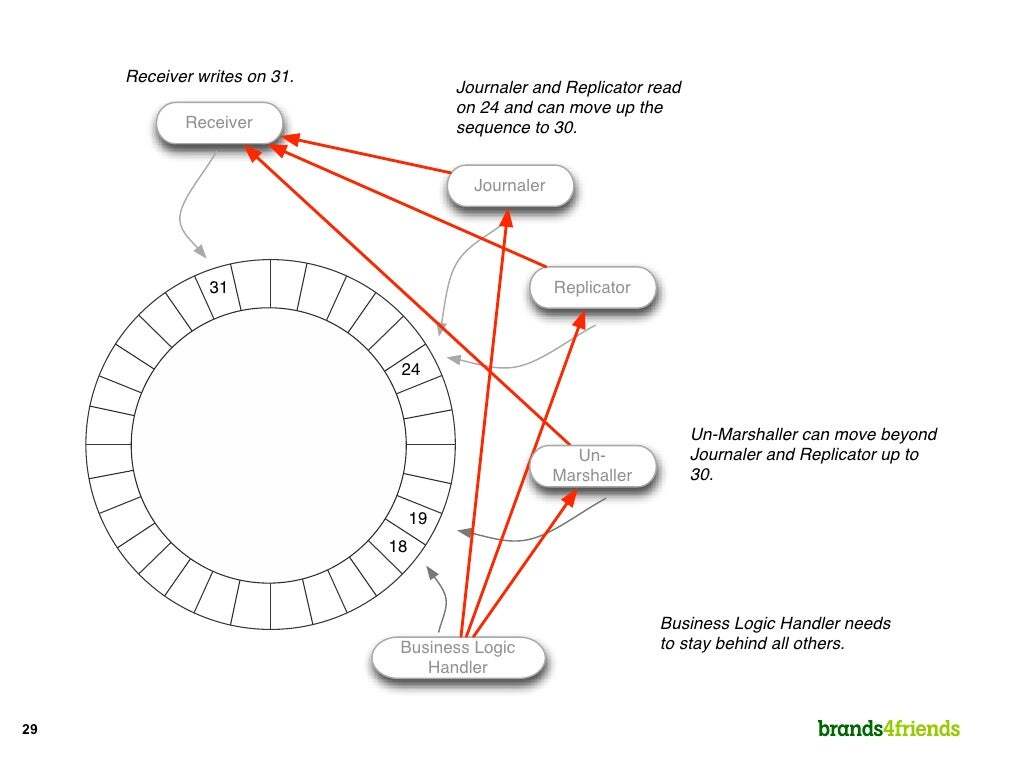
각 필드는 캐시라인을 고려해 64byte, 링버퍼의 크기는 2의 n 제곱, 배치 프로세싱등의 세부적인 최적화 사항이 있지만 더 자세한 내용들은 다음을 참고해보기 바란다.
- LMAX Architecture(프리젠테이션)
- The LMAX Architecture(마틴 파울러 블로그)
- Introduction to the Disruptor
- LMAX Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads
8. 동기화 프리미티브
필요성
쓰레드가 공유 변수에 접근하게 되면 경쟁조건(Race Condition)이 생기게 된다. [바로 위의 링버퍼를 사용하면 효율적으로 접근을 할 수가 있었다.]
예를 들어 다음처럼 동시에 값을 수정할 때가 있겠다.
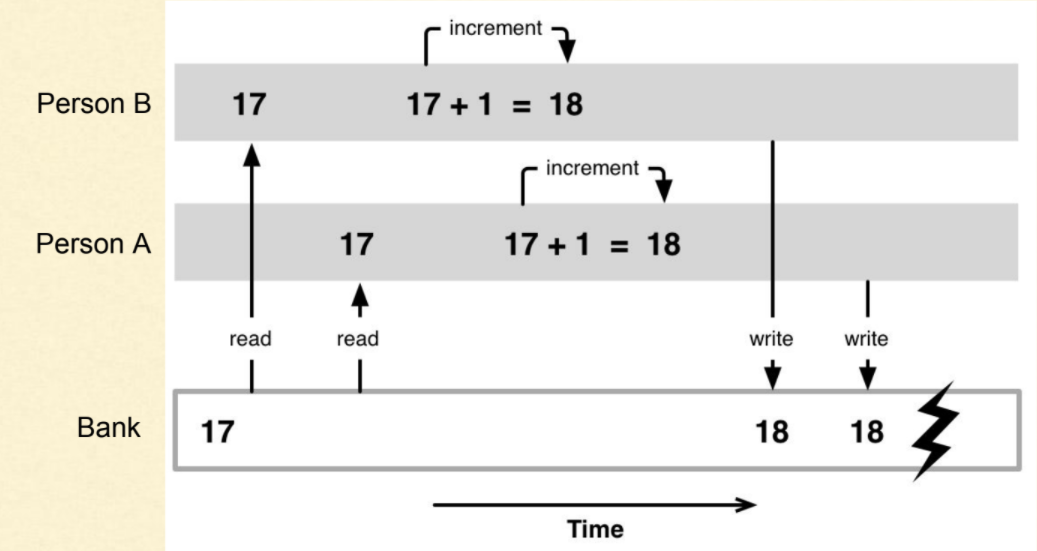
이를 막는 간단한 방법은 동시에 접근하지 못하게 막는것(잠금, Lock)이다.
그래서 다음과 같이 임계구역(Critical section)을 설정해 쓰레드간 동기화를 할 수있다.
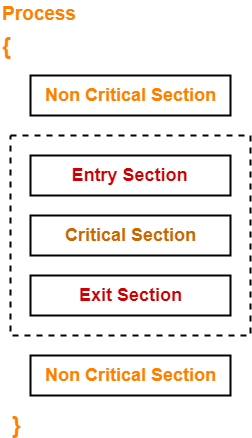

Critical Section | Critical Section Problem, Mutex lock과 condition을 사용한 생산자 소비자 문제의 구현
그러나 락을 잘못 사용하게되면 서로가 서로를 기다리는 교착상태(Deadlock)이 생길 수도 있으니 조심해야한다. [Deadlock, Livelock and Starvation]
반대로 서로 넘겨주느라 일을 못하는 Livelock 상태도 있다.

데드락 스레드 안전
여러 스레드가 동시 실행될 때 코드가 올바르게 작동하면 스레드 안전(Thread safe)하다고 할 수 있다.
보통 다음과 같은 경우를 알아보면 된다.
- 전역변수, 힙, 파일등 전역범위에 동시에 접근
- 핸들/콜백 또는 포인터로 간접적으로 접근
- 전역범위의 리소스 할당, 재할당, 해제 (사이드 이펙트)
스레드 안전을 달성하기 위해서는 다음과 같은 방법을 사용한다.
우선 공유상태를 피하는 방법.
- 재진입성: 어떤 함수가 한 스레드에 의해 호출되어 실행 중일 때, 다른 스레드가 그 함수를 호출하더라도 각 결과가 올바르게 반환되어야 함
- 스레드 지역 저장소: 변수를 각 스레드가 고유한 복사본을 갖도록 복사
- 불변객체: 만들어지고 변경할 수 없기 때문에 동시에 읽기만 가능, 변경이 필요할 경우 새로운 객체를 만드는 형식
공유상태를 피할 수 없다면 다음과 같은 방법을 사용할 수 있다.
- 상호배제: 항상 하나의 스레드만 공유 데이터를 읽거나 쓸수 있도록 직렬화
- 원자 연산: 다른 스레드에 의해 중단될 수 없는 원자성 작업을 이용하여 다른 스레드가 접근하는 방식과 상관없이 유효함을 달성
스레드 안전의 또 다른 고려사항은 컴파일러로, 최적화 때문에 명령의 순서가 바뀔 수 있다.
메모리 장벽(Memory Barriers)은 임계구역의 일종으로 메모리의 작업이 올바른 순서대로 일어나도록 보장한다. [Memory Barriers in .NET, User-space RCU: Memory-barrier menagerie]
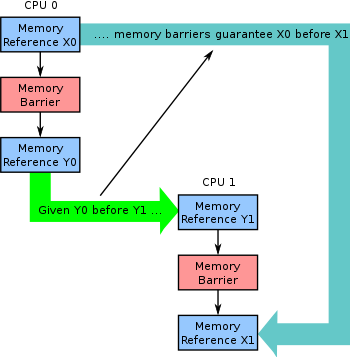
메모리 장벽 이 파트에서는 공유상태를 피할 수 없을 경우를 가정하고 동기화 프리미티브를 소개한다.
앞서 나온 Future/Promise와 후에 나올 메세지 전달도 동기화 프리미티브의 한 종류며 공유를 피하는 방식의 구현이다.
예를 들어 메세지 전달의 채널 방식은 값을 복사하거나 옮겨 스레드 지역 저장소의 방식의 일종이다.
스핀락
스핀락(Spin lock)은 가장 간단한 동기화 방법이다.
Lock 상태에 접근하면 Lock이 풀릴 때까지 반복적으로 뺑뺑이돌며(Spin) 확인하다가 풀리면 접근하는 방식이다.
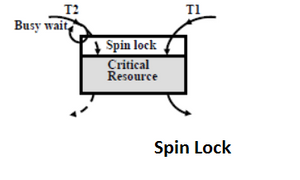
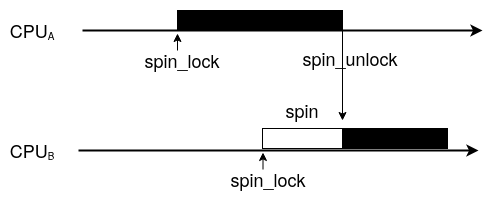
spinlock, The Linux Kernel Locking API and Shared Objects
유저스페이스에서만 동작하기 때문에 컨텍스트 스위칭 비용이 없다.
그렇기에 다른 프로세스와 공유, 오래 대기하는 경우에는 문제가 생긴다.
뮤텍스
뮤텍스(Mutex)는 운영체제를 통해 락을 걸어준다.
다른 락이 풀릴 때까지 계속 확인하는게 아닌 대기하는 상태가 된다.
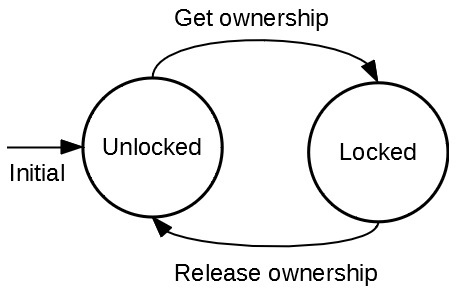
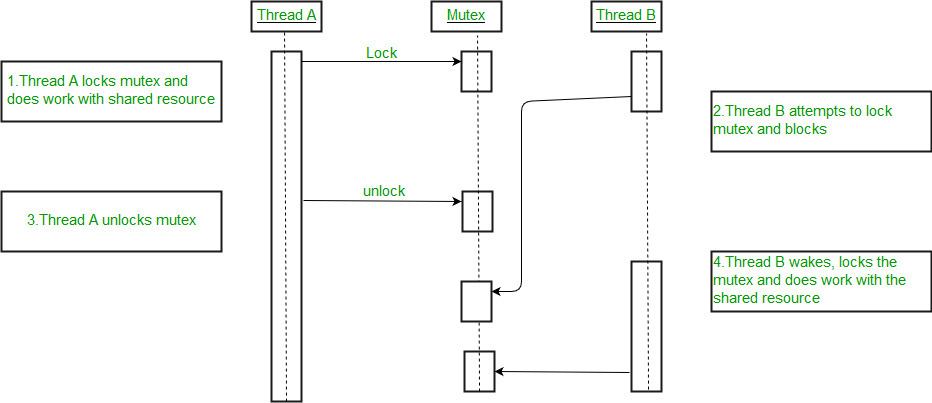
RTOS: Mutex and Semaphore Basics, Mutex lock for Linux Thread Synchronization
앞서 말했듯 커널을 거치기에 컨텍스트 스위칭 비용은 있다.
세마포어
세마포어(Semaphore)는 배열처럼 여러 값에 접근할 때 사용한다.
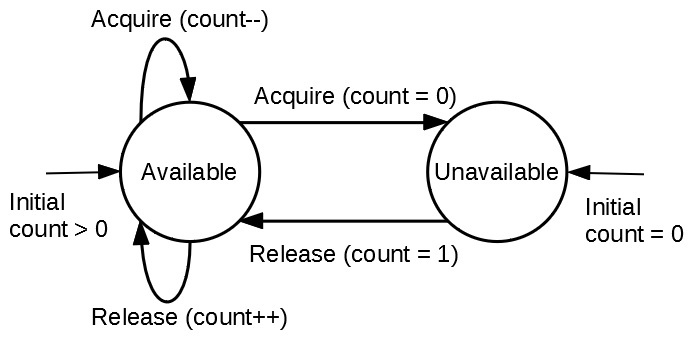
뮤텍스와 비교하자면 다음같은 양상.
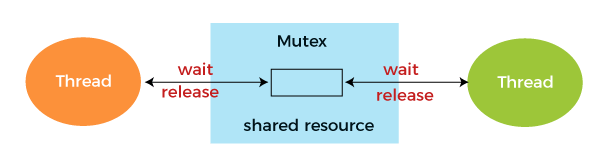
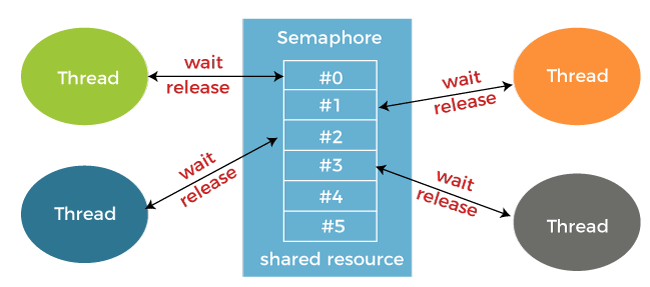
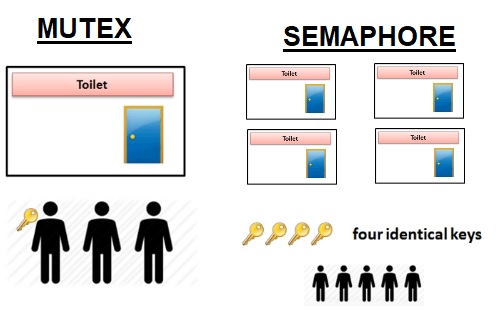
Mutex vs Semaphore, Java Thread Interview Questions & Answers (All About Java Semaphore and Mutex)
STM
잠금/잠금해제 작업이 상당히 머리 아프기에 변수가 알아서(?) 관리해주면 좋겠다고 생각한적이 있다면, 그 답은 소프트웨어 트랜잭션 메모리(STM, Software Transaction Memory)다.
상호배제가 아니라 원자연산을 활용했다.
트랜잭션? 어디서 많이 들어봤죠?
바로 DB에서 사용하는 방법이다.

락 대신 버전을 체크하고 커밋을 하는 형태이다.

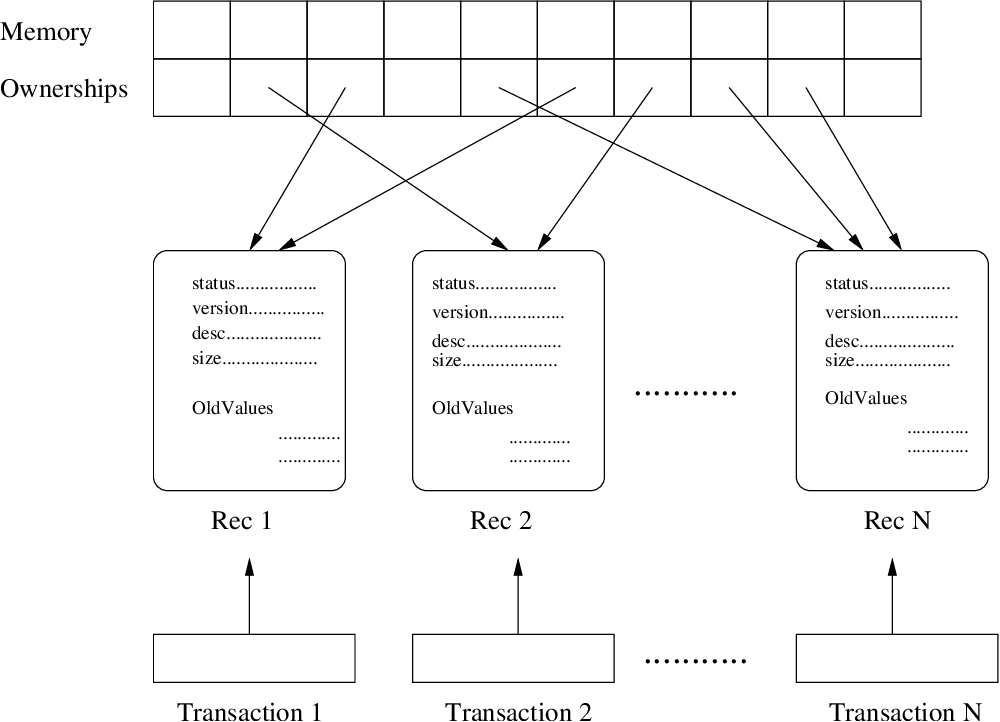
Clojure STM - What? Why? How?, A Qualitative Survey of Modern Software Transactional Memory Systems
각 작업을 조금 더 자세히 들여보면 다음과 비슷할 것이다.
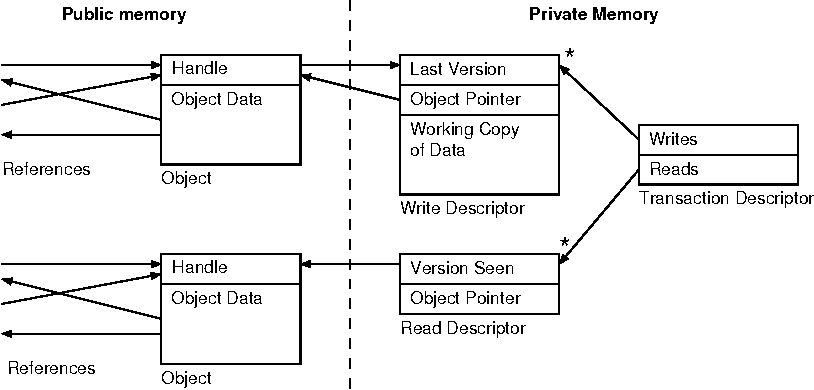

Software Transactional Memory Should Not Be Obstruction-Free
GIL
까다로운 동기화 문제 때문에 파이썬의 경우 GIL(Global Interpreter Lock, 전역 인터프리터 잠금)로 해결을 한다.
좋은 방법은 아니라 생각하지만..
각설하고 파이썬이 GIL을 사용하게 된 계기를 알아보자.
파이썬은 마크&스윕 방식이 아닌 레퍼런스 카운팅 방식으로 메모리 관리를 한다.
여러 쓰레드가 동시에 레퍼런스 카운트에 접근한다면 문제가 생긴다.
단순히 생각하면 객체들에 락을 걸면되겠지만 매우 느렸다.
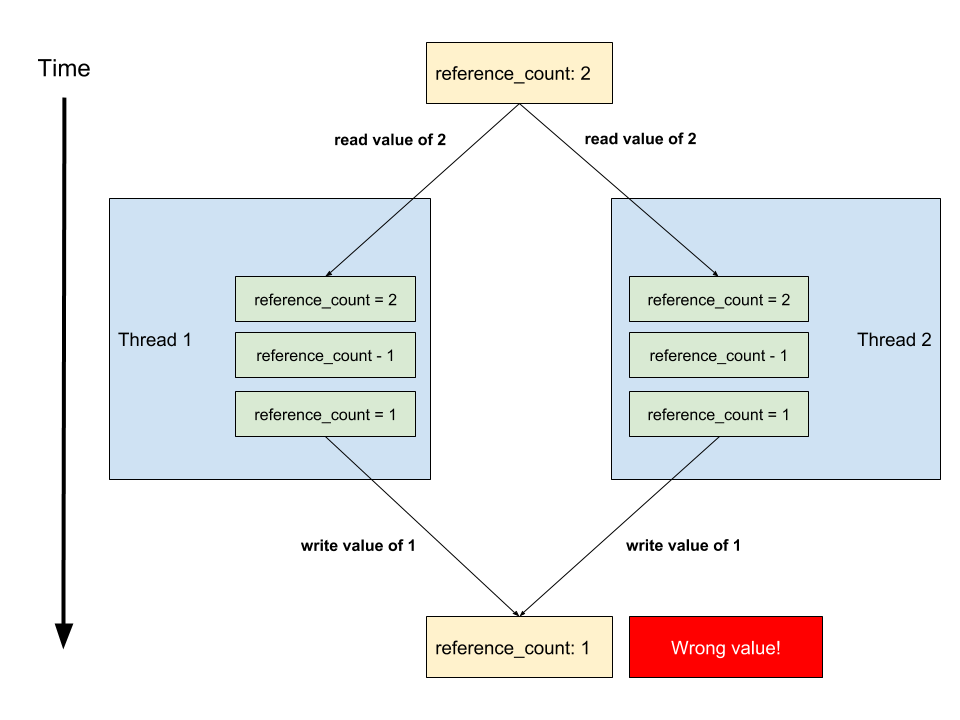

The Python Global Interpreter Lock
따라서 쓰레드에 락을 걸어 코루틴처럼 만들어버린다.
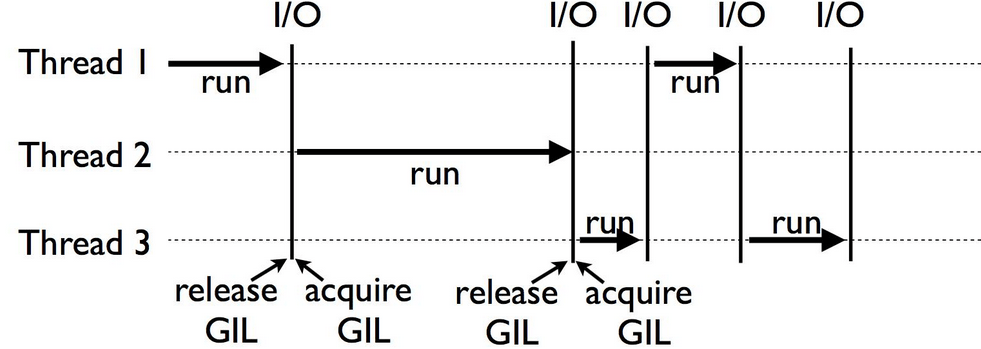
Python Global Interpreter Lock Tutorial Python Global Interpreter Lock Tutorial
쓰레드를 코루틴처럼 만들어 버리다니 I/O에서는 괜찮을 수 있겠지만 CPU 바운드 작업에서는 상당한 문제가 생긴다.
때문에 파이썬은 C라이브러리들과의 바인딩을 통해 해결하며, 다음 챕터에서 다른 스크립트 언어의 접근법을, 그 다음 챕터에서 더 나은 모델을 알아보자.
9. 다른 스크립트 언어의 접근법과 Reactor/Proactor 패턴
Ractor (루비)
루비에는 한때 Guild라고 불렸던 Ractor가 있다.
루비에 있던 GIL에서 벗어나면서도 호환성이 있는 동작을 목표로 했다.
길드는 파이버를 하나 이상 가진 쓰레드로 구성되며, 한 길드에서는 GGL(Giant Guild Lock)로 다른 쓰레드가 실행될 수 없게 보장된다.
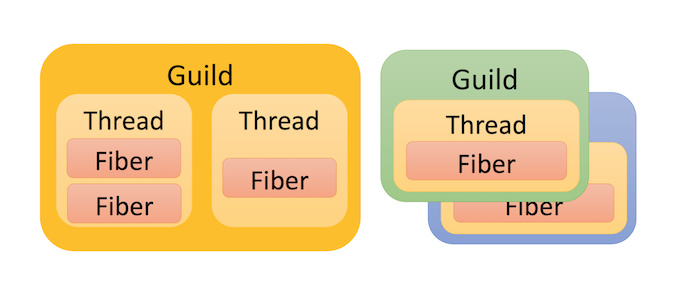
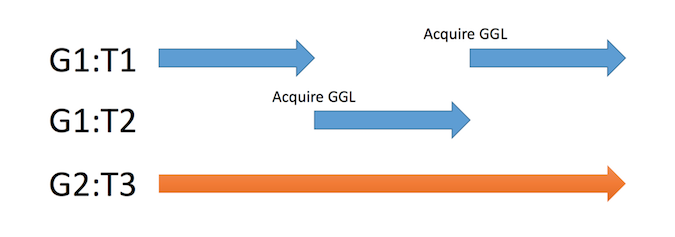
Concurrency in Ruby 3 with Guilds
길드간에는 채널을 통해 복사 또는 이동을 하여 데이터를 전송하는 형태.


Ractor에 관심이 있다면 다음 글들도 읽어보기를 바란다.
- A proposal of new concurrency model for Ruby 3
- Ractor: Ruby’s Version of the Actor Model
- Introduction to Concurrency Models with Ruby. Part II
No GIL (파이썬)
파이썬도 가만히 있지 않고 성능 개선 작업을 진행 중에 있다.
그렇다면 파이썬의 GIL에 대한 해결책은 무엇인가하면 두가지 방식이 경쟁중인 상황!!
바로 No GIL과 Sub-interpreter.
Sub-interpreter의 접근방식은 LWN에 나오듯 후에 나올 자바스크립트의 Worker와 비슷하다.
여기서는 No Gil의 방법을 살펴보자.
- The Python GIL: Past, Present, and Future
- Talks - Cheuk Ting Ho: Trying No GIL on Scientific Programming
다음은 현재 GIL 동작, GIL이 없을때 생기는 문제를 보여준다.
GIL이 없을 경우 동기화 프리미티브 소개에 경쟁조건이라 나왔던 현상이 나타난다.
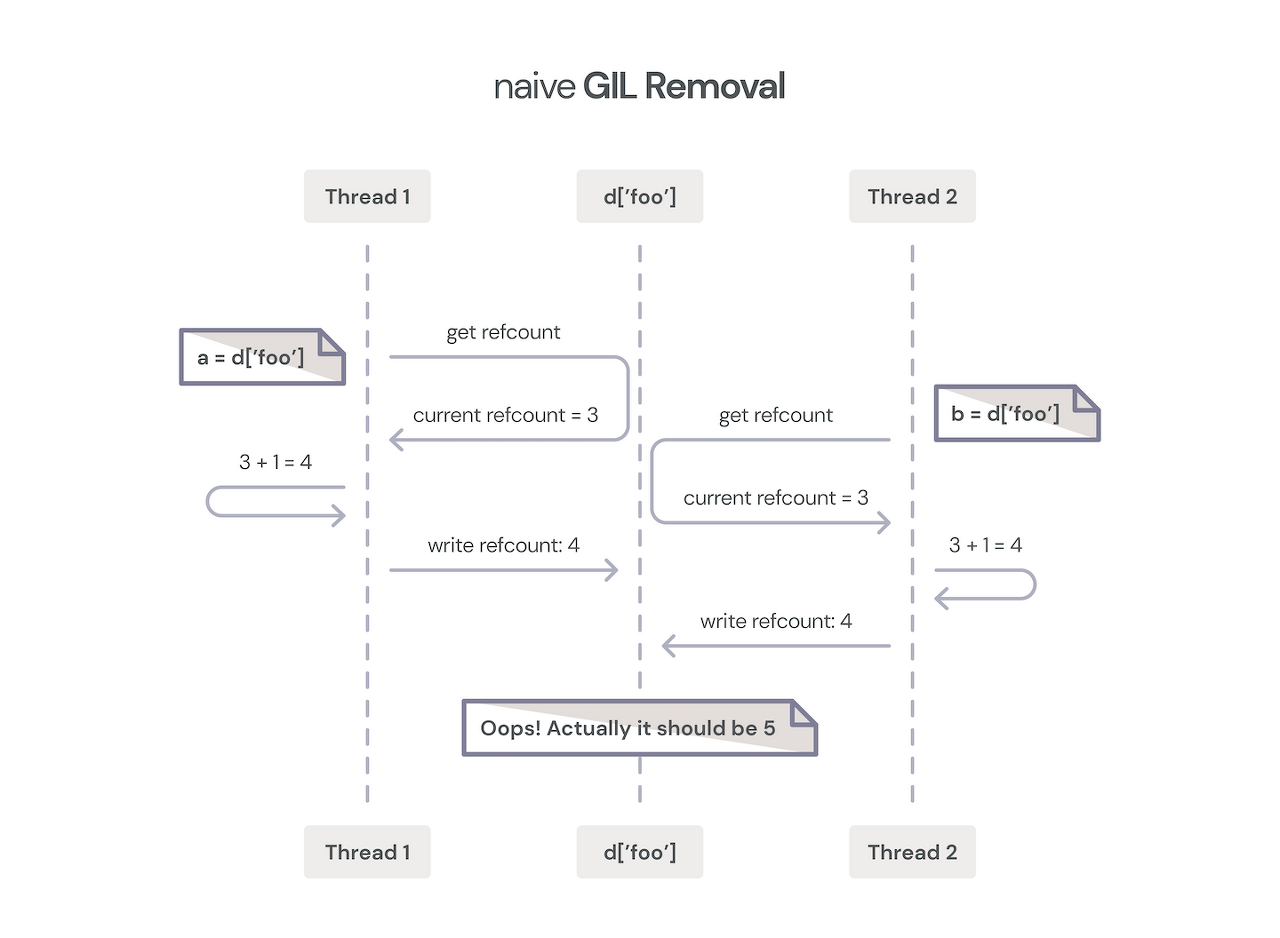
GIL을 없애려는 시도는 총 3가지로 나타나는데, 첫번째는 앞서 스레딩을 하려 했으나 느렸다는 것(1999년).
두번째 2015년의 시도는 STM처럼 atomic하게 만들자 아이디어로 일명 Gilectomy라 부른다..
하지만 캐시 일관성의 파괴와 버스에서의 통신 오버헤드를 해결하기가 쉽지 않았다고 한다.
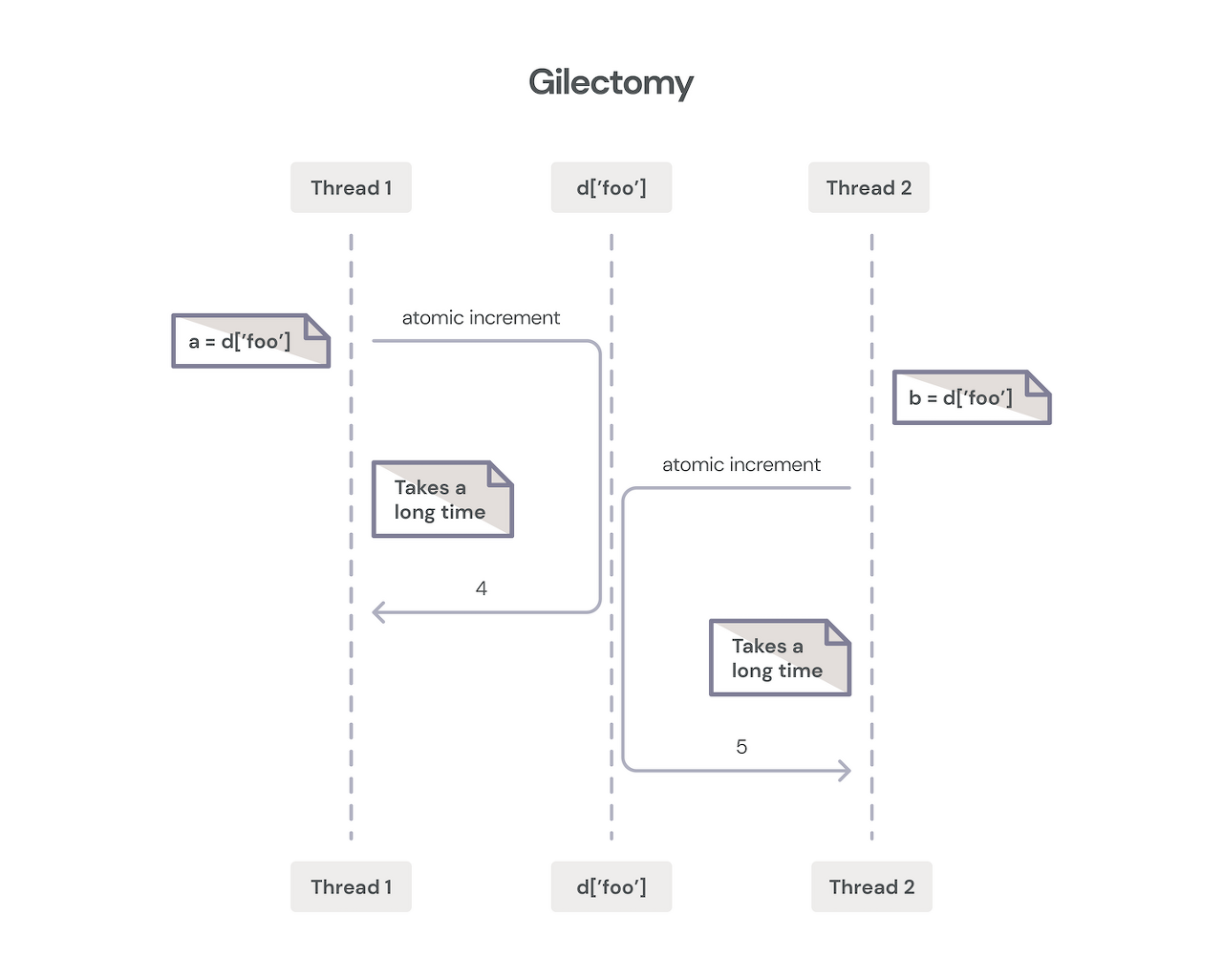
그리고 마지막, 현재 No GIL.
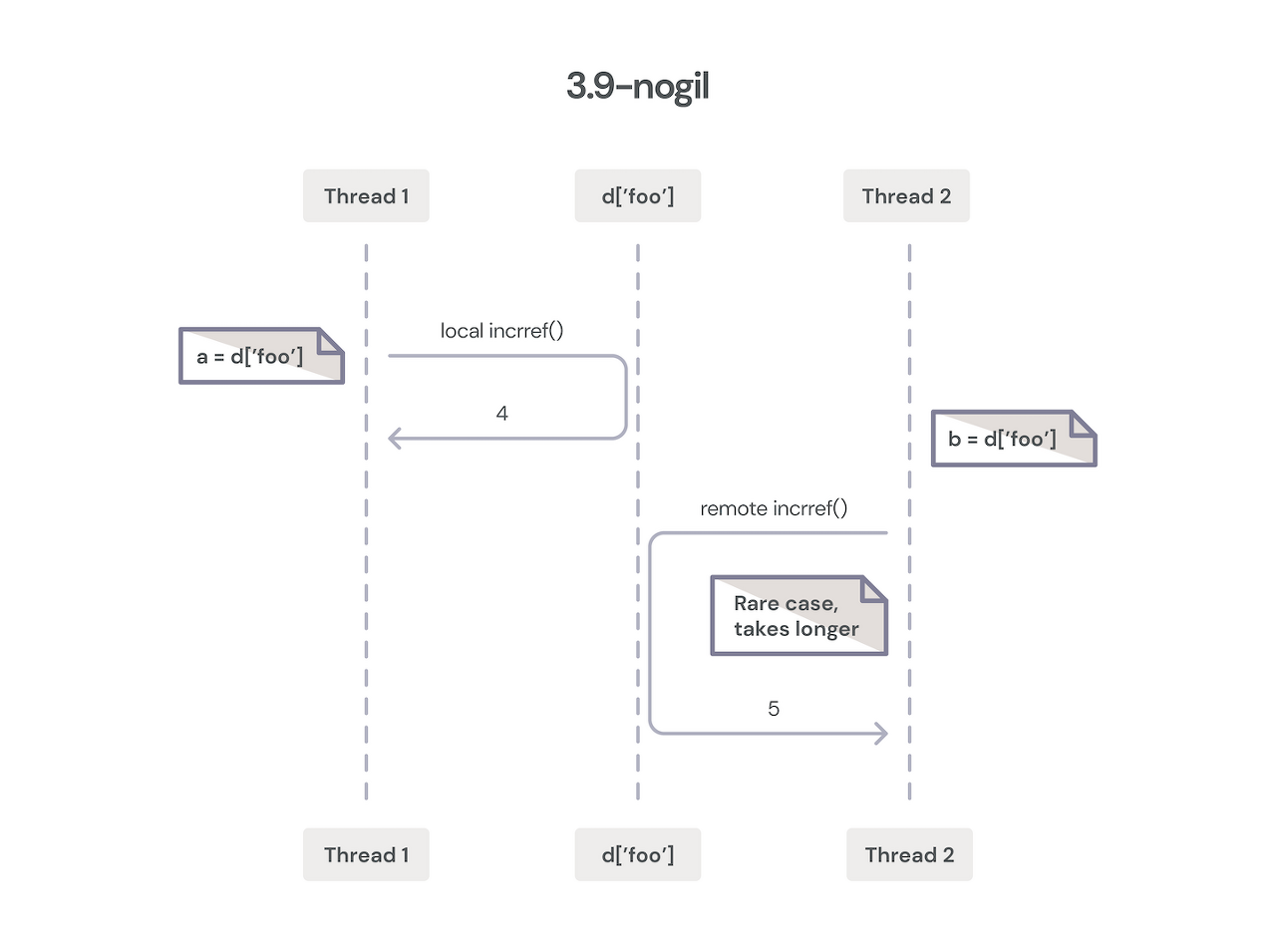
- 스레드 안전한 메모리 할당자 사용
- 항상 참조횟수가 0 이상을 유지되는 True, False, None등은 recount 매크로가 작동하지 않도록해 경쟁조건 회피
- 다른 쓰레드가 접근할때만 Atomic하게 업데이트
대부분의 객체 엑세스는 소유 스레드의 로컬일때 일어나므로 효율적임 - 컬렉션의 lock을 위한 효율적인 알고리즘
Worker (자바스크립트)
자바스크립트는 기본적으로 싱글 쓰레드 언어다.
이유는 동기화에서 안전하지 않기 때문이다. [Understanding Worker Threads in Node.js]
대표적인 예로 부동소수점 연산 관련이 있다.
그럼 싱글 쓰레드를 유지하며 멀티코어를 이용할 방법은 없을까?
여기 쉬운 방법이 있다. 바로 shell scirpt에서 sub shell 만들 듯 띄워버리면 그만이다 ㅋㅋ
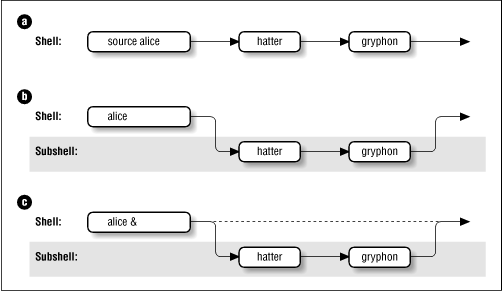

Basic Shell Programming, ./ ,bash ,bash -c "", source, subshell vs childprocess
이게 서브 인터프린터의 기본 개념이다.
워커 자체는 여전히 싱글 스레드로 실행되며, shell과는 달리 sleep 없이 동시에 실행가능해야 한다.
그래서 postMessage()를 통해 데이터를 주고 받는 형태를 띄고 있다.


The JavaScript Event Loop: Explained, The Ultimate Guide to Web Workers
물론 오버헤드와 API 제한은 있다. [How JavaScript works: The building blocks of Web Workers + 5 cases when you should use them]
ArrayBuffer를 사용하지 않는 이상 직렬화-복사-역직렬화 과정이 일어나며, window나 documnet 등의 객체에는 접근할 수가 없다.

Node.js (Reactor 패턴)
지금까지 자바 스크립트 언어자체에는 스레드가 없다고 하였다.
즉, 멀티쓰레드는 없고 앞서 나온 멀티플렉싱 기법과 같이 이벤트를 처리한다.
싱글 쓰레드가 라운드 로빈식으로 동작한다는 말.
- Node.js event loop architecture
- What you should know to really understand the Node.js Event Loop
- Node.js 이벤트 루프(Event Loop) 샅샅이 분석하기
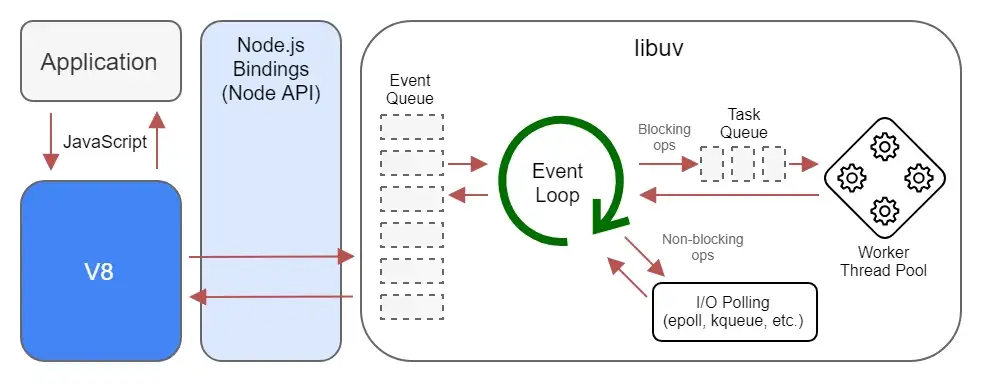
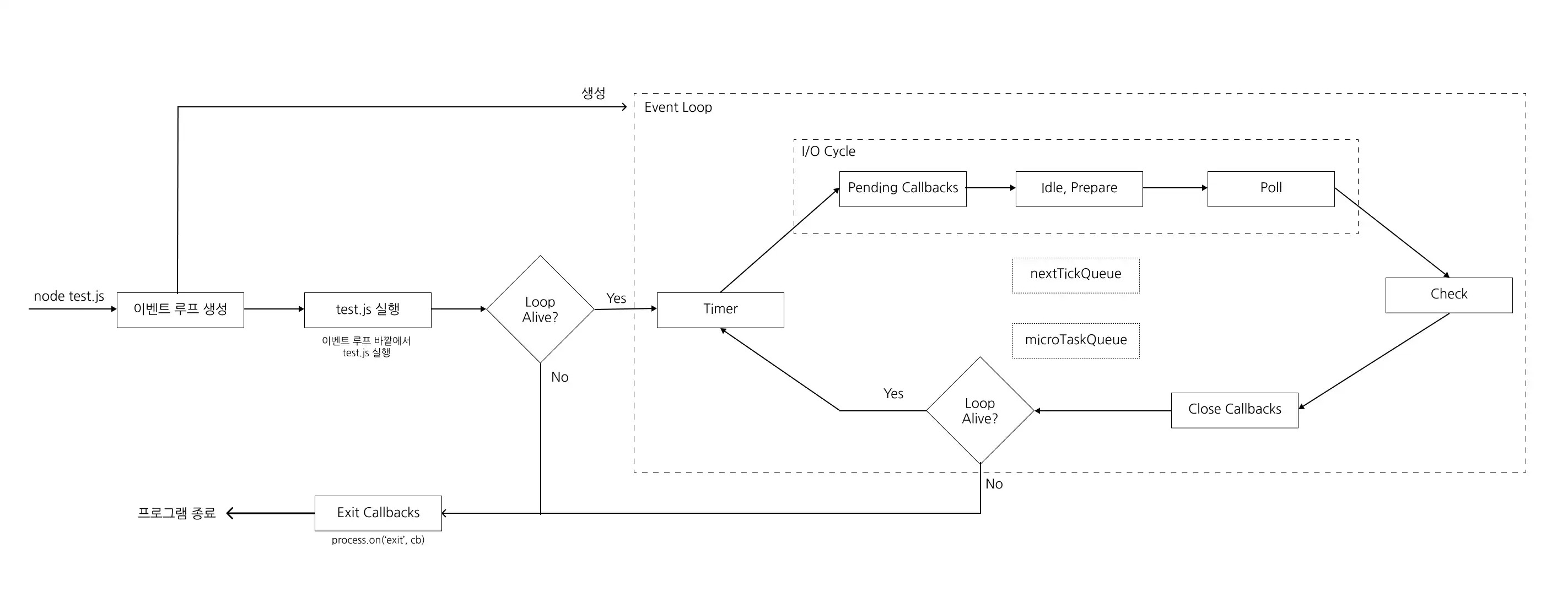
Node.js 아키텍처와 I/O 루프
그럼에도 불구하고 최대한 성능을 내기 위해 Node.js의 백그라운드에서 멀티 쓰레드로 일부 동작한다. (Reactor 패턴)
기본적으로 4개인걸로 알려져있으며 동작은 상당히 제약적이다.
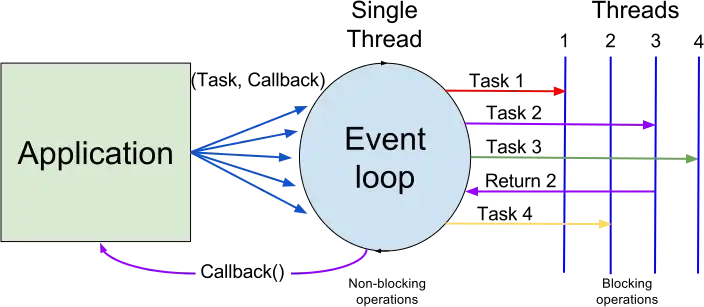
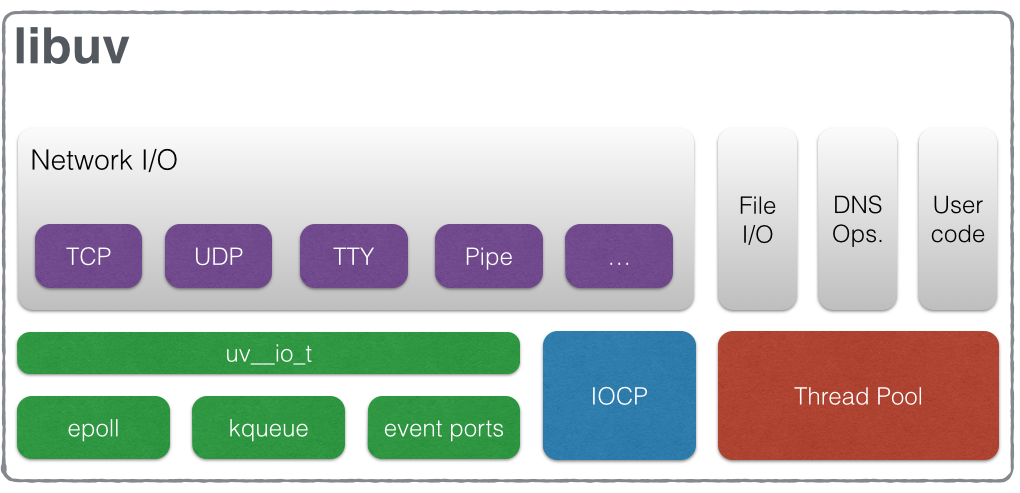
- 단일 스레드지만 운영체제의 Epoll, kqueue 등을 활용: 네트워크(TCP/UDP), TTY, 파이프
- 쓰레드 풀에서 실행: 파일 I/O, DNS, 사용자 지정 코드
그렇다면 자바스크립트의 비동기는 어떻게 동작하길래 실행순서가 다른가?
답은 큐가 여러개다.

Understanding the Node.js Event Loop
다음 애니메이션을 보면 이해가 더 쉬울 것이다.
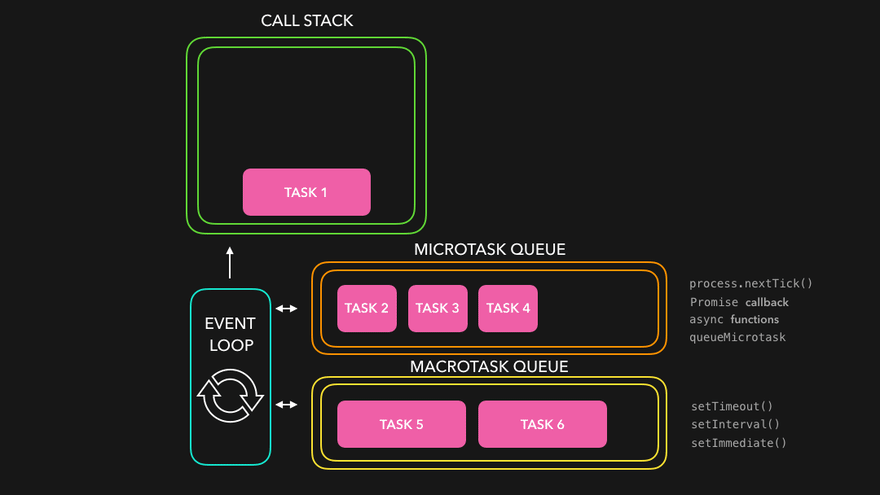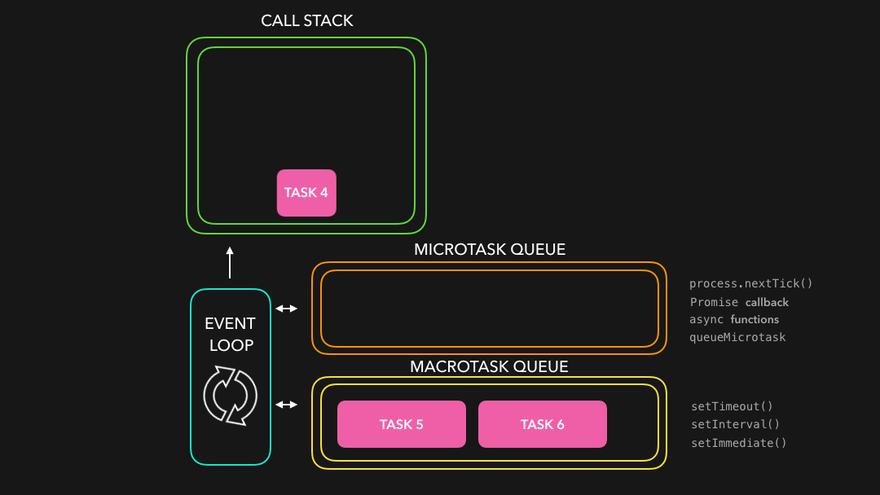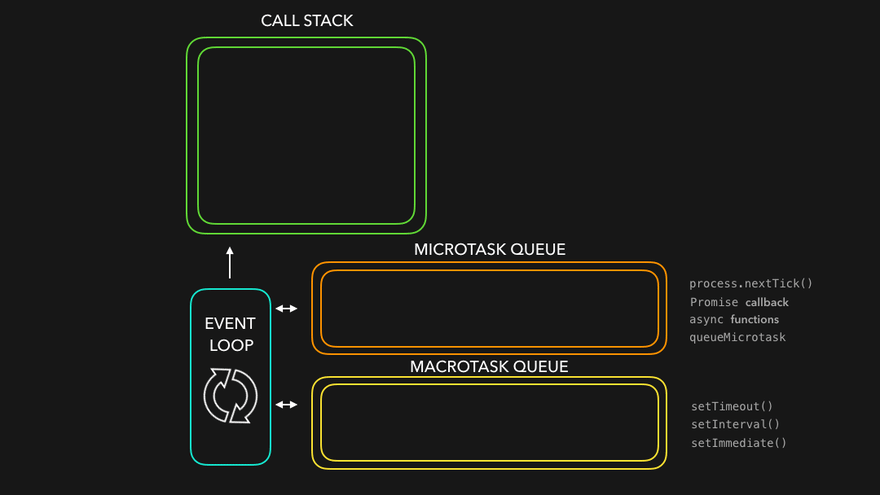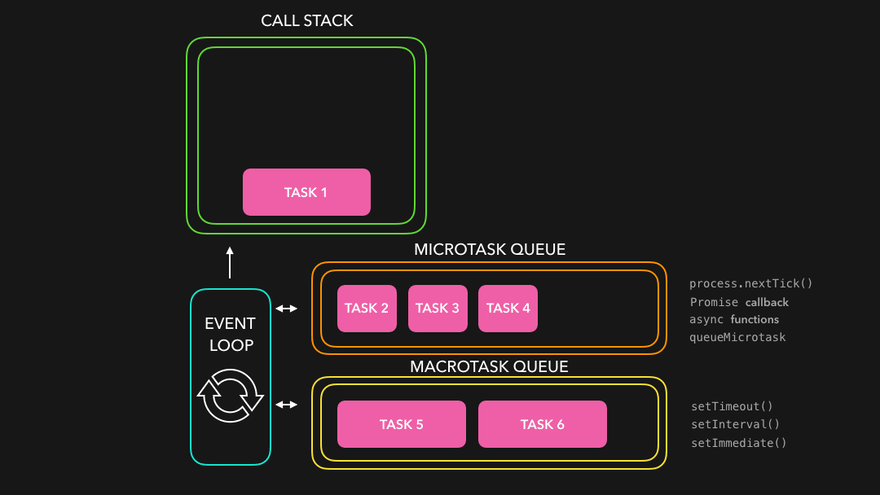
JavaScript Visualized: Promises & Async/Await
위의 Worker와 함께 실행되는 모습을 상상해보면 다음과 같다.
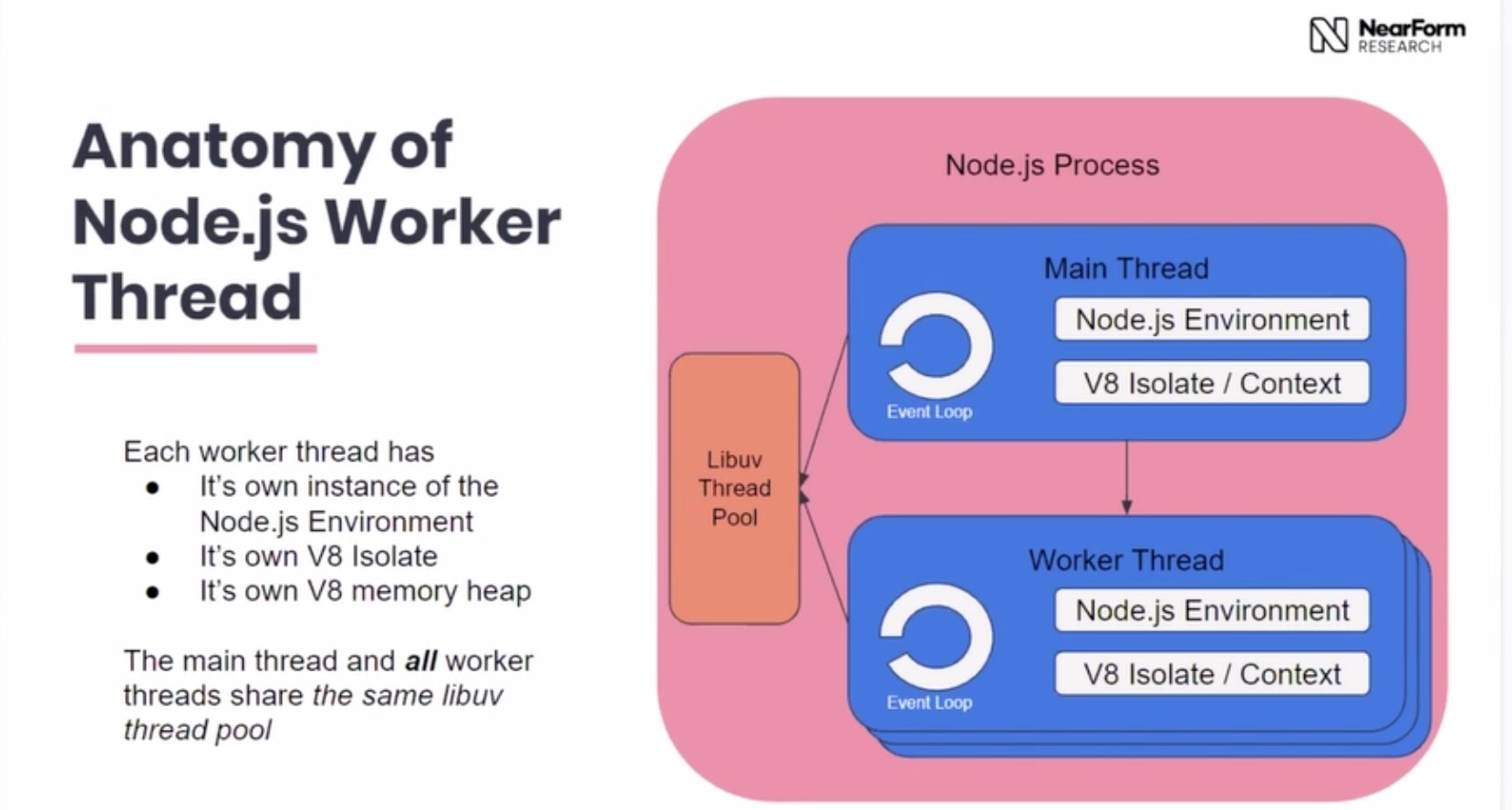
각 워커도 한개의 이벤트 루프를 가지고 있는 싱글 스레드로 동작한다 - 트위터
Proactor 패턴
앞선 노드 JS는 Reactor 패턴이다.
Reactor, Proactor 패턴은 이벤트 핸들러의 논블럭킹을 지원한다.
Reactor는 동기적, Proactor는 비동기적이다.

The Proactor and Reactor Design Patterns
다음 Reactor 패턴 그림을 보면 동기적이며, Node.js 이벤트 루프와 비슷하다는 것을 단번에 알아챌 수 있을 것이다.

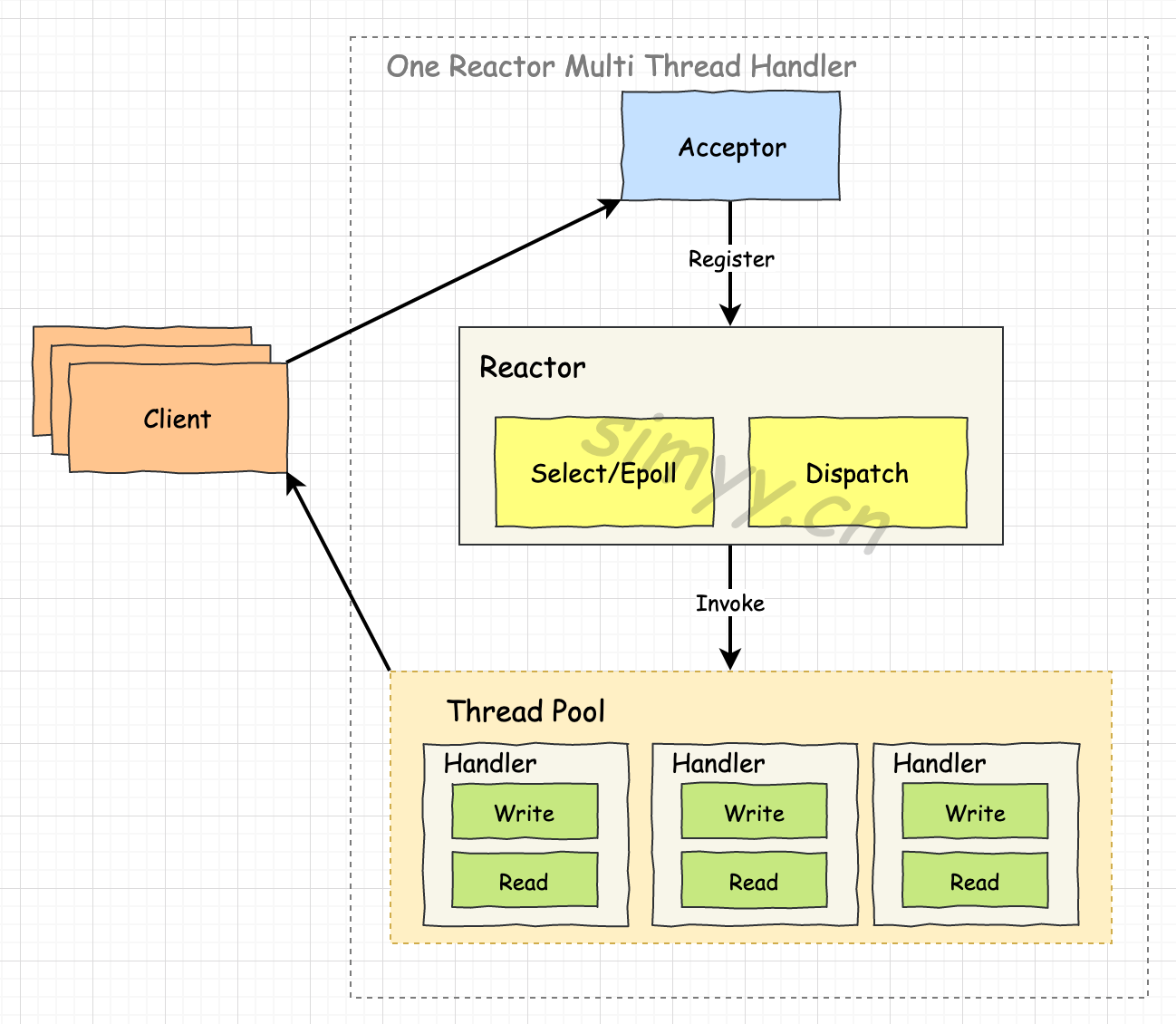
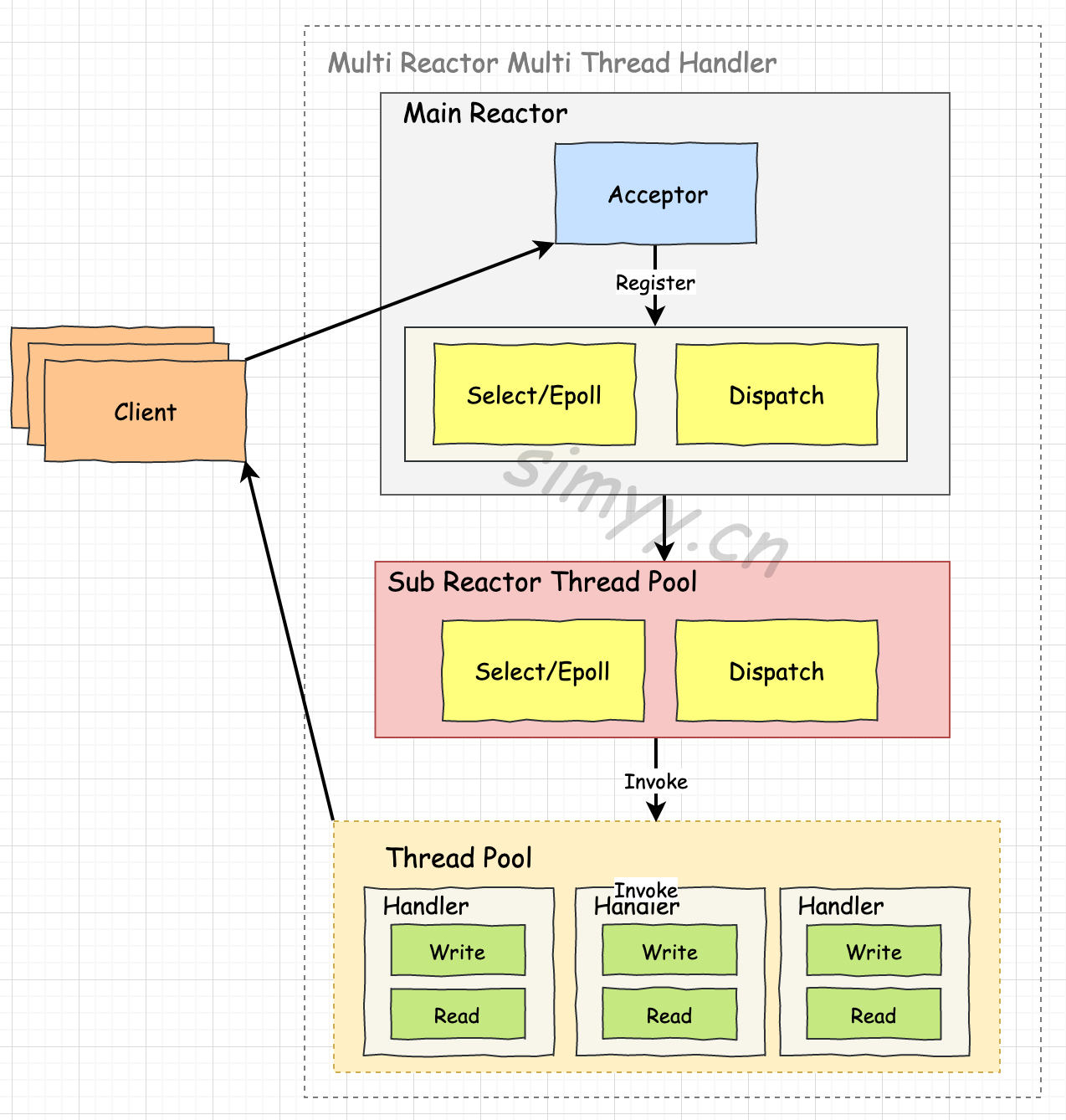
기본, 멀티 쓰레드 핸들러, 멀티 리엑터 - 멀티 쓰레드 핸들러 노드 JS는 첫번째 싱글 쓰레드 방식이다.
가장 복잡한 형태인 멀티 리엑터 - 멀티 쓰레드의 예는 Vert.x가 있다.
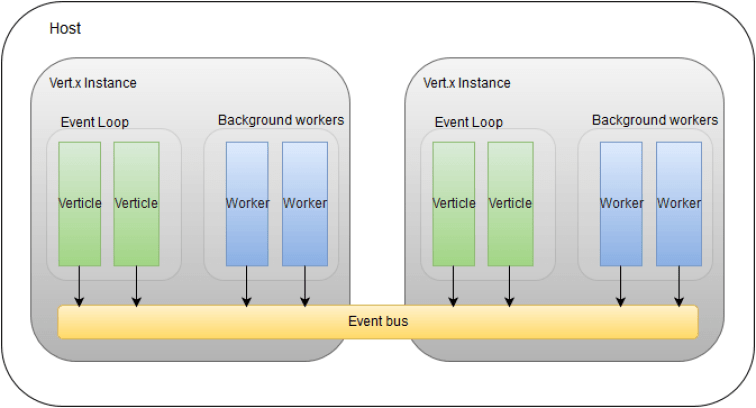
Vert.x에서는 한 쓰레드당 2개의 이벤트 루프를 가진다.
Proactor는 비동기답게 통지해주는 방식이다.
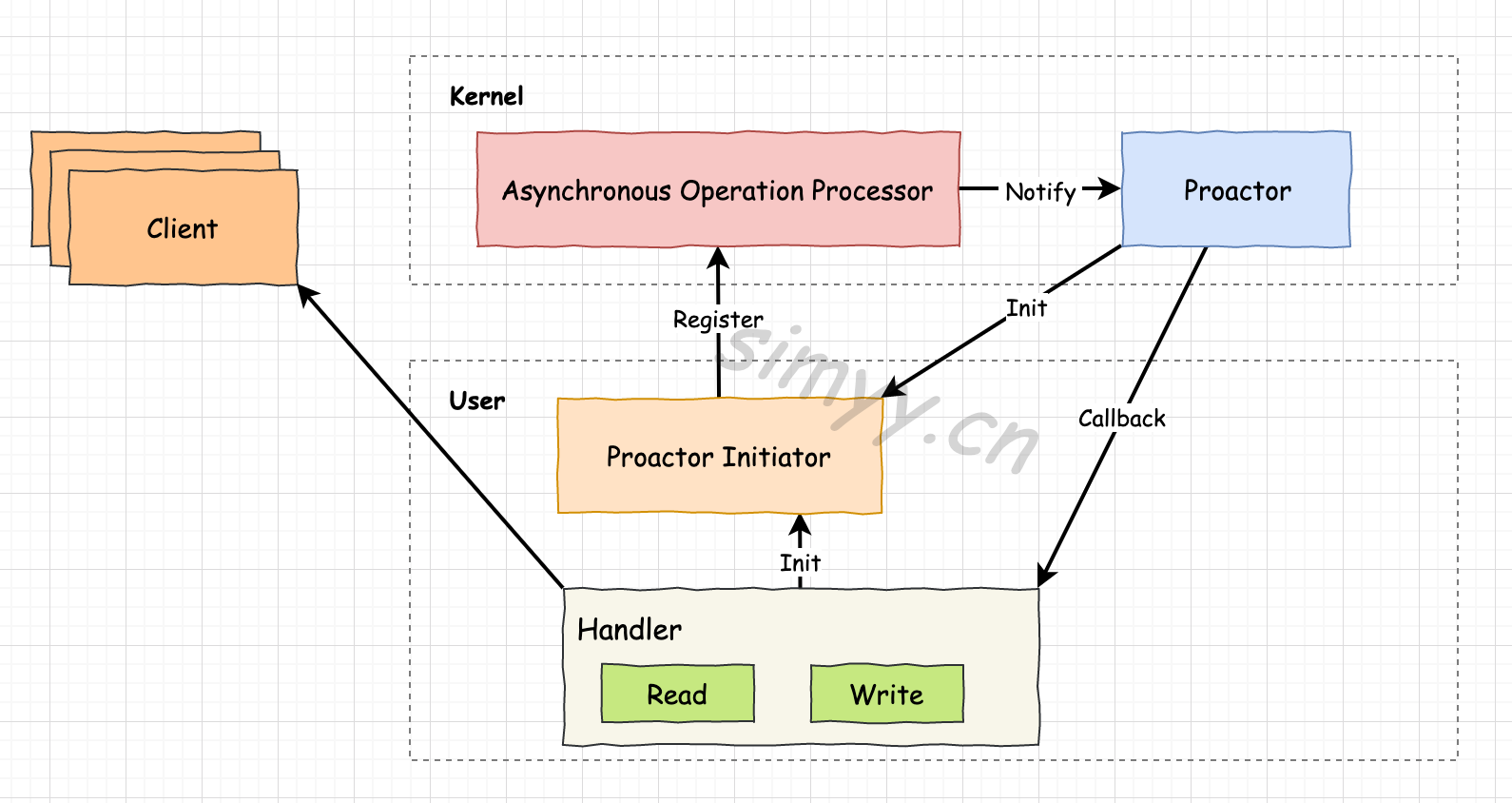
Proactor가 비동기라고 무조건 좋은것은 아니라 구현의 복잡도와 오버헤드가 존재하기 때문에 적절한 상황에서 쓰는게 좋다. (앞서 리눅스 AIO도 오버헤드 때문에 느렸다)
부스트 Asio와 Quarkus가 대표적인 Proactor 패턴의 예이다.
신기하게 영문 자료보다 중국쪽 자료가 많은 것 같다.
화웨이쪽 글 빼면 이미지 이해에 지장없으니 번역기 사용해서 보세요.
10. CSP와 액터
동시성을 위해 이런저런 방식이 있지만 최근 가장 인기있는것은 CSP(순차 프로세스 통신, Communication Sequential Process)와 액터(Actor)다.
두 방식 모두 메모리를 공유하는 대신 통신을 한다.
CSP
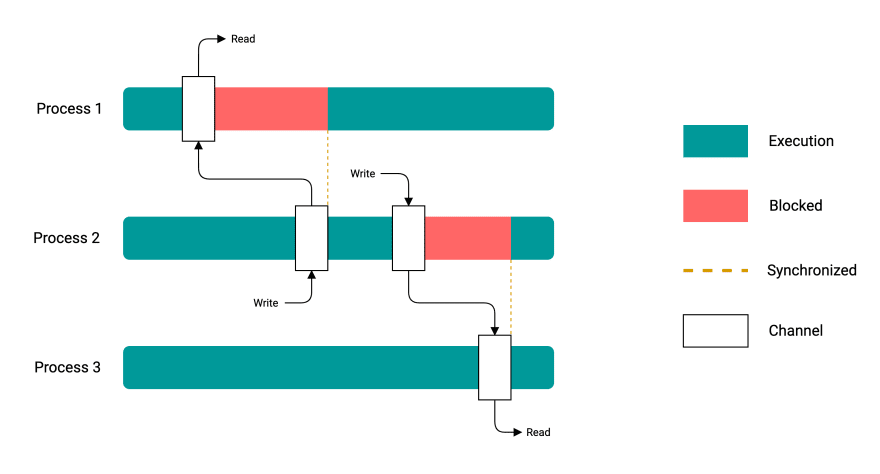
CSP vs Actor model for concurrency
CSP는 채널을 통해서 통신한다.
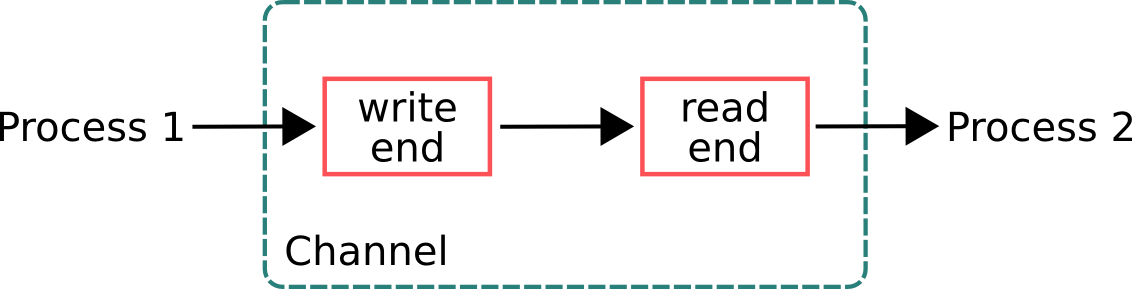
Communicating Sequential Processes (CSP) An alternative to the actor model
마치 변수를 계산하는 것처럼.
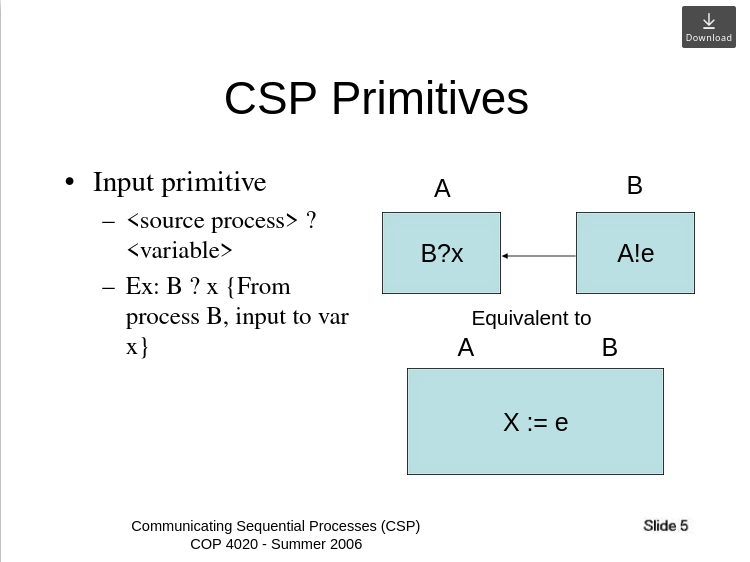
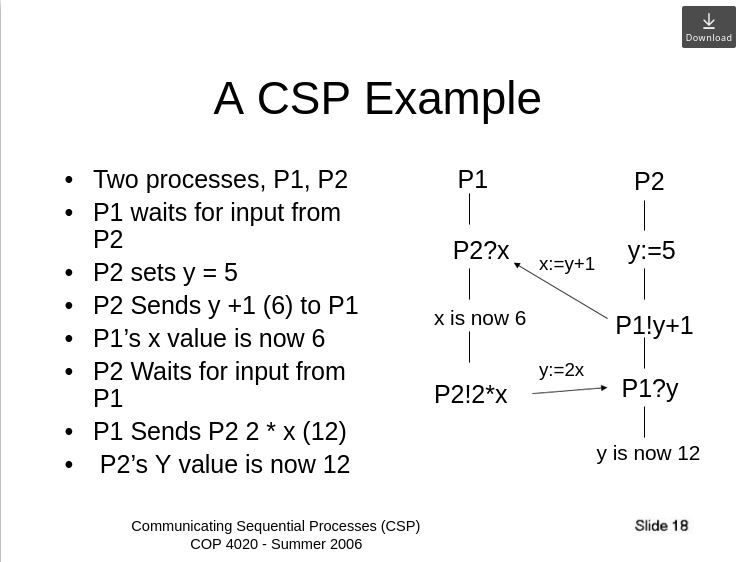
Communicating Sequential Processes
액터
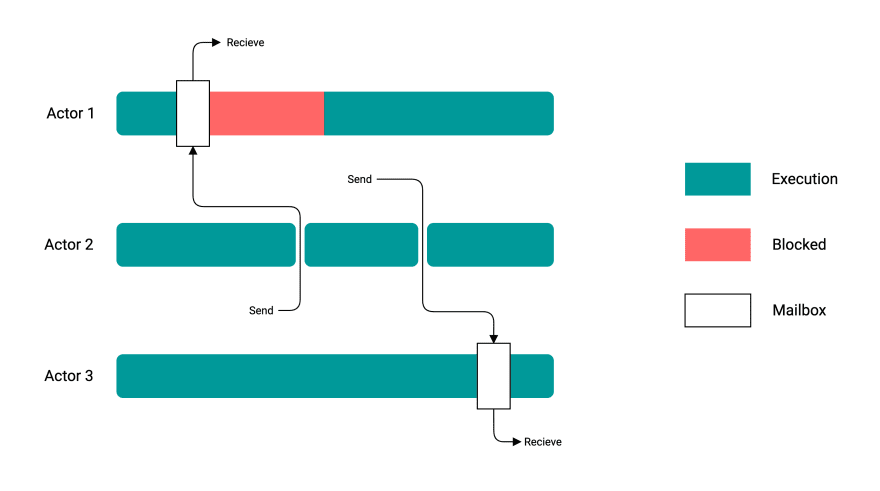
액터 모델은 채널 대신 메세지 박스(메일 박스)를 이용한다.

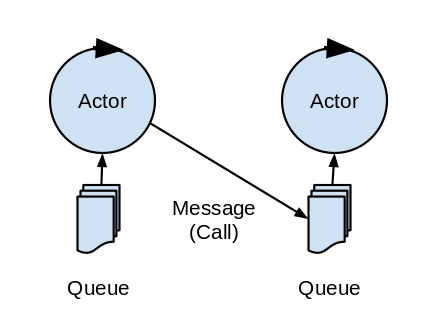
내용만 보면 상당히 비슷하다만 보통 다음과 같은 차이를 가지고 있다고 설명한다.
- CSP의 프로세스는 익명, 액터는 ID를 가지고 있음
- CSP의 메세지는 동기화된 입출력으로 보낸 순서대로 도착한다
- 액터의 메세지는 단방향이며 비동기적이다
- 액터는 메세지에는 액터의 주소가 포함될 수 있다
- CSP는 경계 비결정론적이지만, 액터는 무한 비결정론적이다.
11. 그린 쓰레드, 고루틴 그리고 최신 비동기 런타임 기술들
그린 쓰레드
그린 쓰레드는 커널이 아닌 유저 스페이스에서 관리하는 쓰레드다. [Are go-langs goroutine pools just green threads?]
JVM에서 시도해서 실패했지만(1:N 모델로 Stackful 코루틴과 차이가 크지 않았음) 최근 여러 구현체가 나오고 있다.
대표적인게 OpenJDK의 프로젝트 룸(Project Loom)이다.
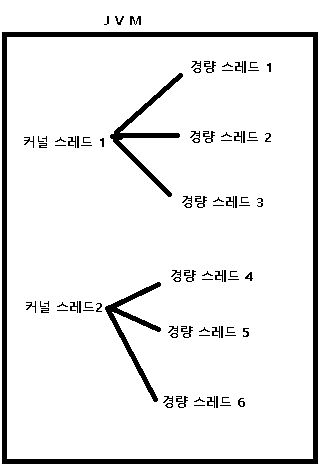
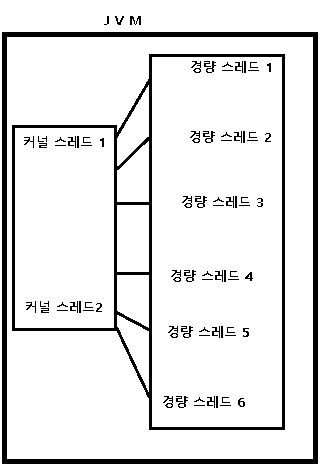
그린 쓰레드 vs 프로젝트 룸 프로젝트 룸은 어차피 다음에 나오는 런타임 기술들과 겹치는게 많으니 궁금하면 링크들을 읽어보기 바란다.
- 프로젝트 룸(Project Loom)이란 무엇인가?
- Java의 동시성 개선을 위한 Project Loom은 reactive streams를 대체할 것인가?
- Project Loom: Fibers and Continuations for the Java Virtual Machine
- Sexy async code without await?
- A first look into the Project Loom in Java
- Going inside Java’s Project Loom and virtual threads
- Will Project Loom obliterate Java Futures?
최신 CSP 런타임
앞서 나온 여러 개념들이 혼합되서 들어간다.
- The Go scheduler
- A Deep Dive Into Go Concurrency
- How Does Golang Channel Works(Deep Dive to Golang Channel, 한글)
- Making the Tokio scheduler 10x faster
- Reducing tail latencies with automatic cooperative task yielding
- Tokio internals: Understanding Rust's asynchronous I/O framework from the bottom up
- If a goroutine create a new goroutine, which one would scheduler pick up first?
이 둘이 빠른 이유는 크게 두가지, 스케쥴링과 채널(메세지)으로 나뉠 수 있다.
먼저 스케쥴링부터 알아보자.
다음은 고루틴의 스케쥴링 모델인데 좀 복잡해 보인다.

- 쓰레드풀과 갯수
먼저 하나의 OS 쓰레드 1개와만 매핑되던 오리지널 그린쓰레드와 다르게 여러개를 사용한다. [위에서는 P(Virtual Processor)의 갯수]
- 쓰레드 풀을 사용해 생성과 종료시 시스템콜과 자원의 할당/반납 오버헤드를 줄일 수 있음
- Goroutine, Tokio의 모두 논리코어(OS에서 인식하는 코어 수)의 갯수대로 생성
- 논리코어보다 많으면 컨텍스트 스위칭의 오버헤드가 추가되며, 적은 수의 스레드가 항상 활성화 상태일 때가 더 바람직함
- 코루틴
그리고 말단은 여러 코루틴(고의 고루틴, Tokio의 태스크)들을 사용한다.
- 앞서 배웠듯 생성에 필요한 크기가 작음
- 유저스페이스에서 전환이 일어나므로 비용이 적음
- 고루틴은 컨티뉴에이션을 이용해 컨텍스트 스위칭을 최소화함
- Task 구조도 Hot 데이터(header)와 Cold 데이터 (Trailer)를 나누어 캐시라인에 최적화 (고루틴의 경우 2kb)
- Tokio의 경우 작업이 끝났다는 알림을 캐시라인 크기에 맞추어 복사 가능하게 만들고 레퍼런스 카운팅(Arc)을 줄임
- 큐와 작업 훔치기(Work stealing)
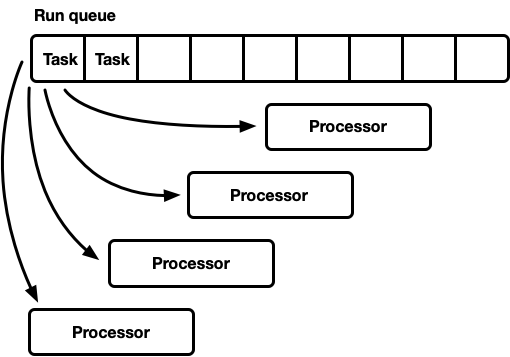

만약 큐가 하나(GRQ, Global run queue)만 있다면 대기열에서 경합이 생긴다.
반대로 여러개(LRQ, Local run queue)가 있다면 완전히 균일한 작업이 아닌이상 놀고있는 프로세서가 생긴다.
따라서 방법은 둘 다!! + 다른 큐의 작업 훔쳐오기
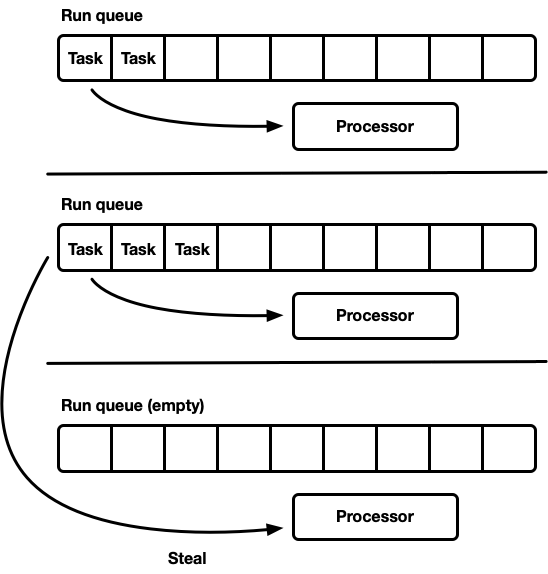

- LRQ는 워크 스틸링과정의 오버헤드를 줄이기 위해 M이 아닌 P당 1개씩 할당
- LRQ는 FIFO큐와 1개의 LIFO(Next Job) 큐로 구성
- 새로 생성한 작업이 Next Job일 때 프로세서에 남아있는 캐시를 최대한 이용할 수 있음((LRU 캐시를 생각해보자)
- 짧게 반복하는 작업이 오랫동안 LIFO를 점유할 수 있기 때문에 점유시간을 제한 (공평한 스케쥴링, 고루틴에서는 10ms)
- FIFO큐의 경우 원형큐로 단일 생산자(현재 프로세서), 다중소비자(Front는 현재 P, Back은 작업을 훔쳐갈 P) 구조 [SPMC]
- GRQ는 LRQ에 할당되지 못한 작업들로 구성된 큐
- LRQ가 가득찬 경우
- 쓰레드에서 일정기간 작업 실행 후 timeout된 작업 (오래 걸릴거라 예상되는 작업을 공평한 스케쥴링을 위해서 선점, 역시 고루틴에서는 10ms)
Tokio의 경우 선점하지는 않지만 작업 예산 개념이 있어 양보할 수는 있음
- 자신의 LRQ - 다른 LRQ - GRQ 순으로 작업을 가져옴
- 캐시의 지역성을 위해 특정한 기간동안 못가져가도록 제한할 수 있음 (고루틴의 경우 3ms)
- 특정 횟수마다 GRQ에서 작업을 가져옴(역시 공평한 스케쥴링을 위해서, 고루틴과 Tokio 모두 61번째)
- GRQ에도 작업이 없으면 네트워크 풀링을 하여 일이 있나 검사를 한다
- 작업을 가져올 때 경합과 오버헤드를 줄여야함 (epoll 작업으로 여러 소켓이 멀티플렉싱되어 동시에 끝나므로 경합하는 경향이 큼)
- 무작위로 무작위로 훔치려는 형제 LRQ를 선택하여 경합을 줄임
- 훔칠 수 있는 작업을 수행하는 P의 갯수를 제한 (일종의 스로틀링, Tokio에서는 P의 절반값)
- 검색 상태가 끝나야 알림을 함
- 블럭킹 작업
- 작업이 오래걸리는 블러킹 작업이나 CPU 바운드 작업은 전용 워커에서 실행해야 함
- CPU 바운드의 경우 고정된 크기의 쓰레드풀이 따로 있는게 효율적
- 고루틴의 경우 네트워크 비동기 작업들을 Net poller라는 배경 쓰레드가 처리후 해당 이벤트가 필요한 P의 LRQ에 넣어줌
컨티뉴에이션은 물론, 원형큐(링버퍼)등 지금까지 나온 거의 모든 개념을 효율적으로 활용하는 것을 볼 수 있다.
각 태스크끼리 효율적으로 정보를 주고받는 작업도 중요한데, Deep Dive to Golang Channel 에서 잘 다루어주고 있다.
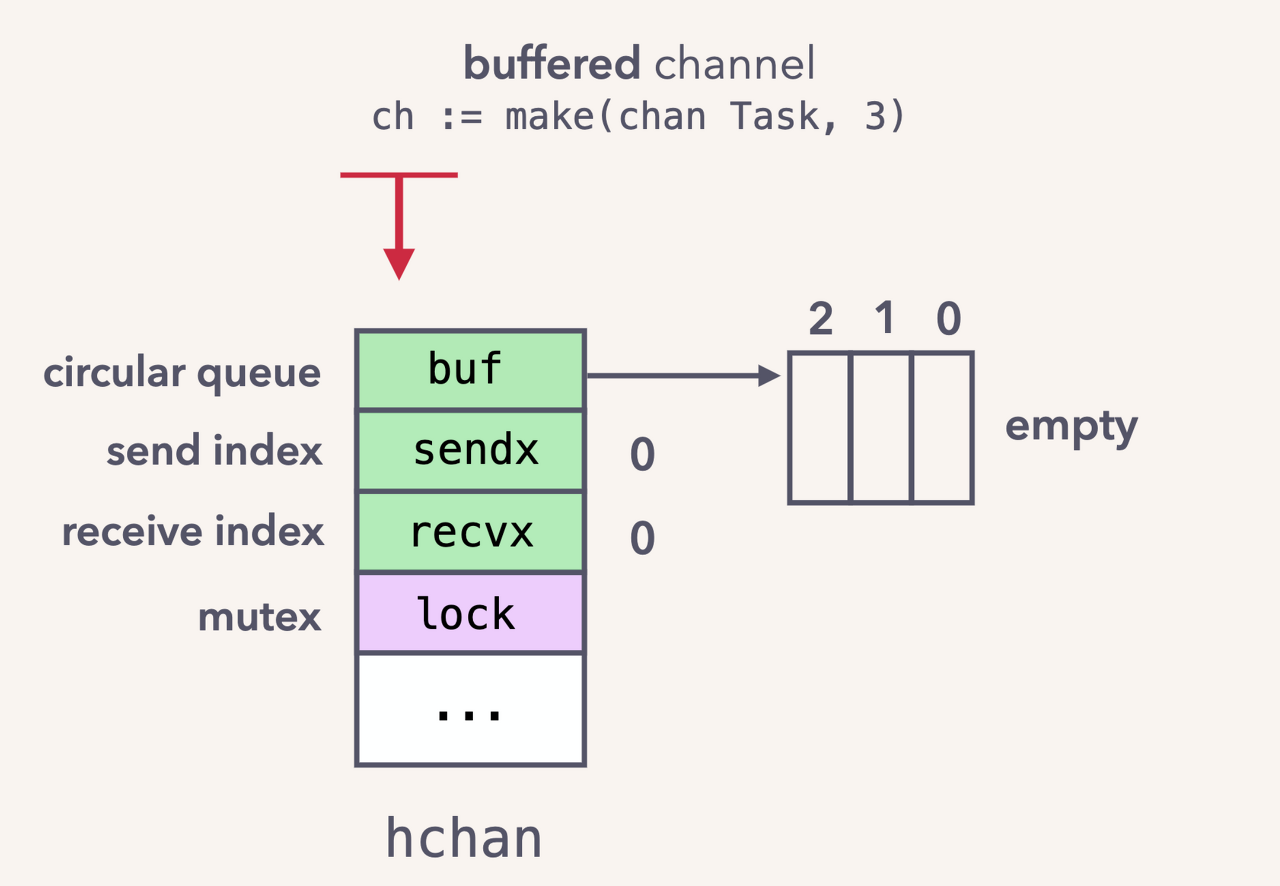
- buf: 링버퍼이며 데이터를 덮어써도 되기 때문에 유용하다
- sendx:전달할 데이터의 인덱스
- recvx: 받을 데이터의 인덱스
- mutex: 주고( send) 받는(recv) 작업을 할 때 락을 걸어 쓰레드 안전하게 만든다


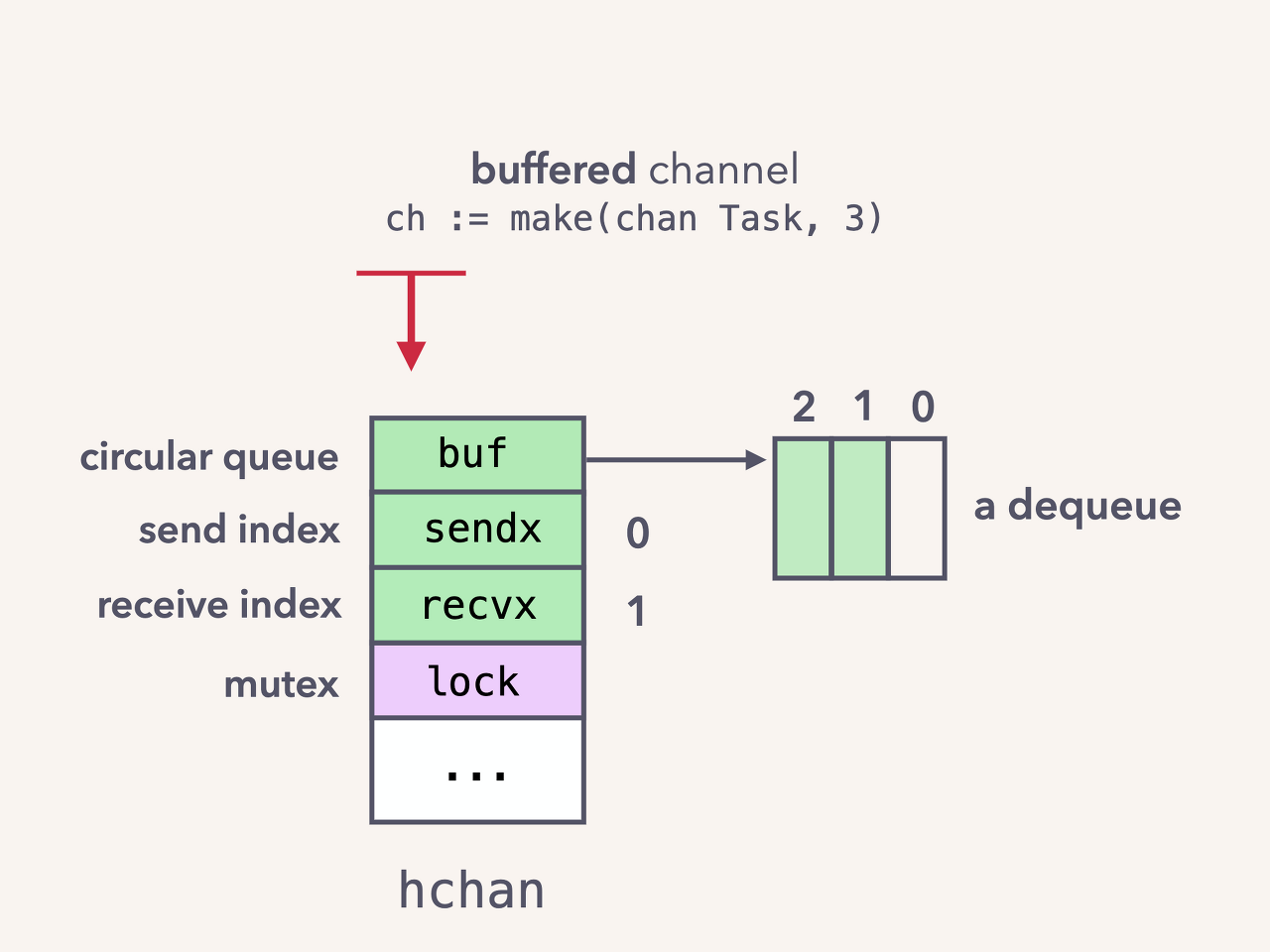
- 1개가 전달되어 sendx의 인덱스가 증가
- 버퍼가 꽉 차도록 전달되어 sendx의 인덱스가 다시 처음으로 돌아옴
- 데이터 한 개를 소비하여 recvx의 인덱스가 증가함
러스트의 빠른 채널 구현체인 Crossbeam, Flume과 Kanal에도 관심을 가질 수도 있다.
최신 액터 런타임
액터 런타임으로 유명한 것은 Erlang의 BEAM과 스칼라의 AKKA가 있다.
Go와 Tokio에 비하면 상대적으로 오래된 런타임이긴 하지만 엑터도 보여줘야하지 않겠는가.
사용되는 기술 자체는 비슷하기에 둘의 특이한 점을 위주로 서술하려한다.
- Elixir and The Beam: How Concurrency Really Works
- Unique Resiliency of the Erlang VM, the BEAM and Erlang OTP
- BEAM (Erlang VM) as a Soft Real-time Platform
- Erlang-Internals-Info
- Erlang VM Tuning
Erlang의 VM의 스케쥴링은 C수준에서 협력적이며, Erlang 수준에서는 선점적이다.
언어 수준에서 재귀를 제외하고는 루프구조가 없으며 Tokio처럼 주어진 예산이 모두 감소(Reduction)하면 양보하는 형태다.
또한 스케쥴러는 각 프로세서당 1개씩 존재하며 우선순위가 존재할 수 있고 로드밸런서에 의해 조정된다.
최대한 많은 스레드를 로드하려하는 compaction과 부하를 분산하는 balancing 모델이 존재한다.

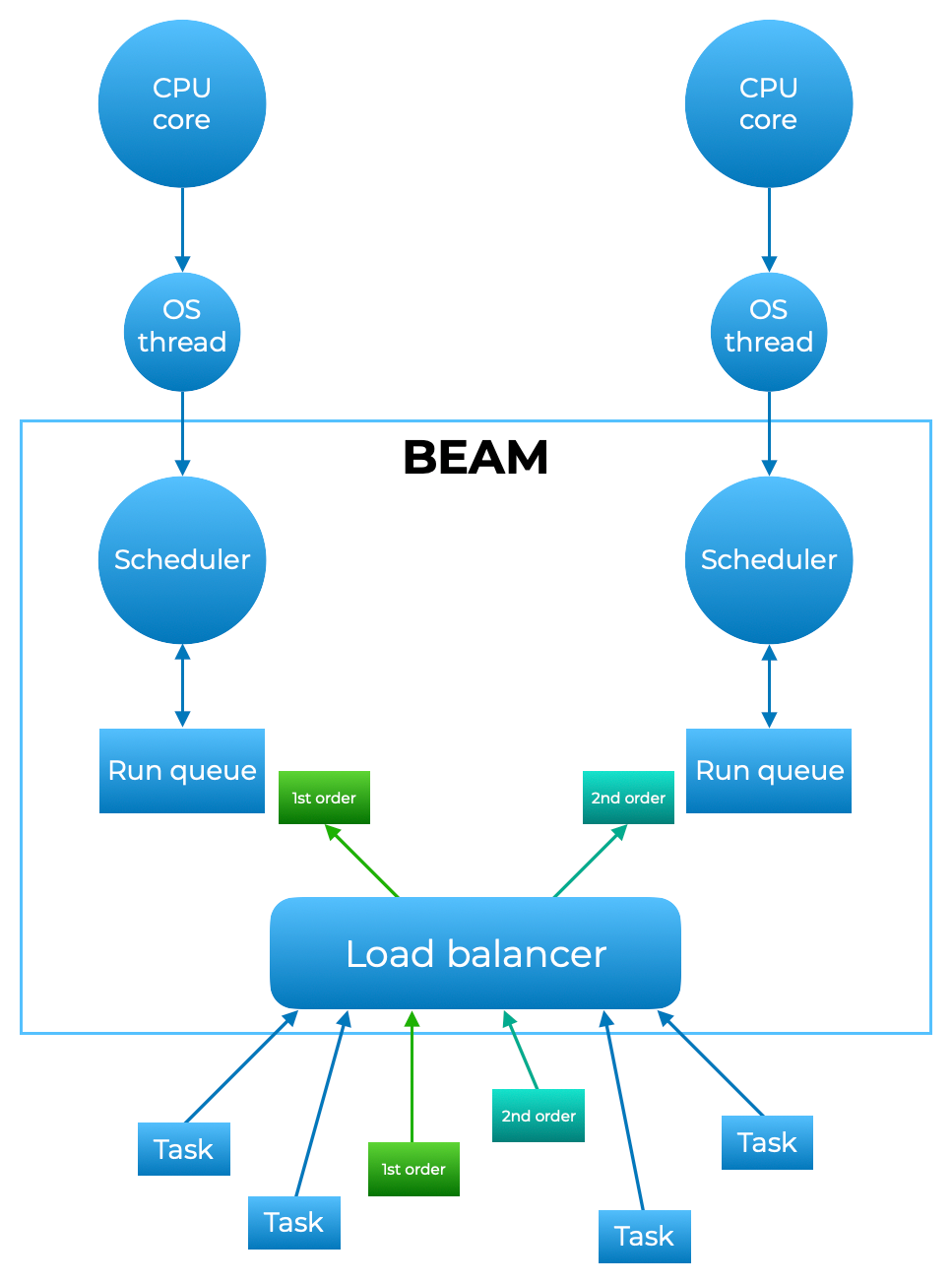
Concurrency and parallelism with Elixir and BEAM
Erlang VM의 각 프로세스(Tokio의 태스크)는 격리된 자체적인 메모리 모델을 가지고 있다.
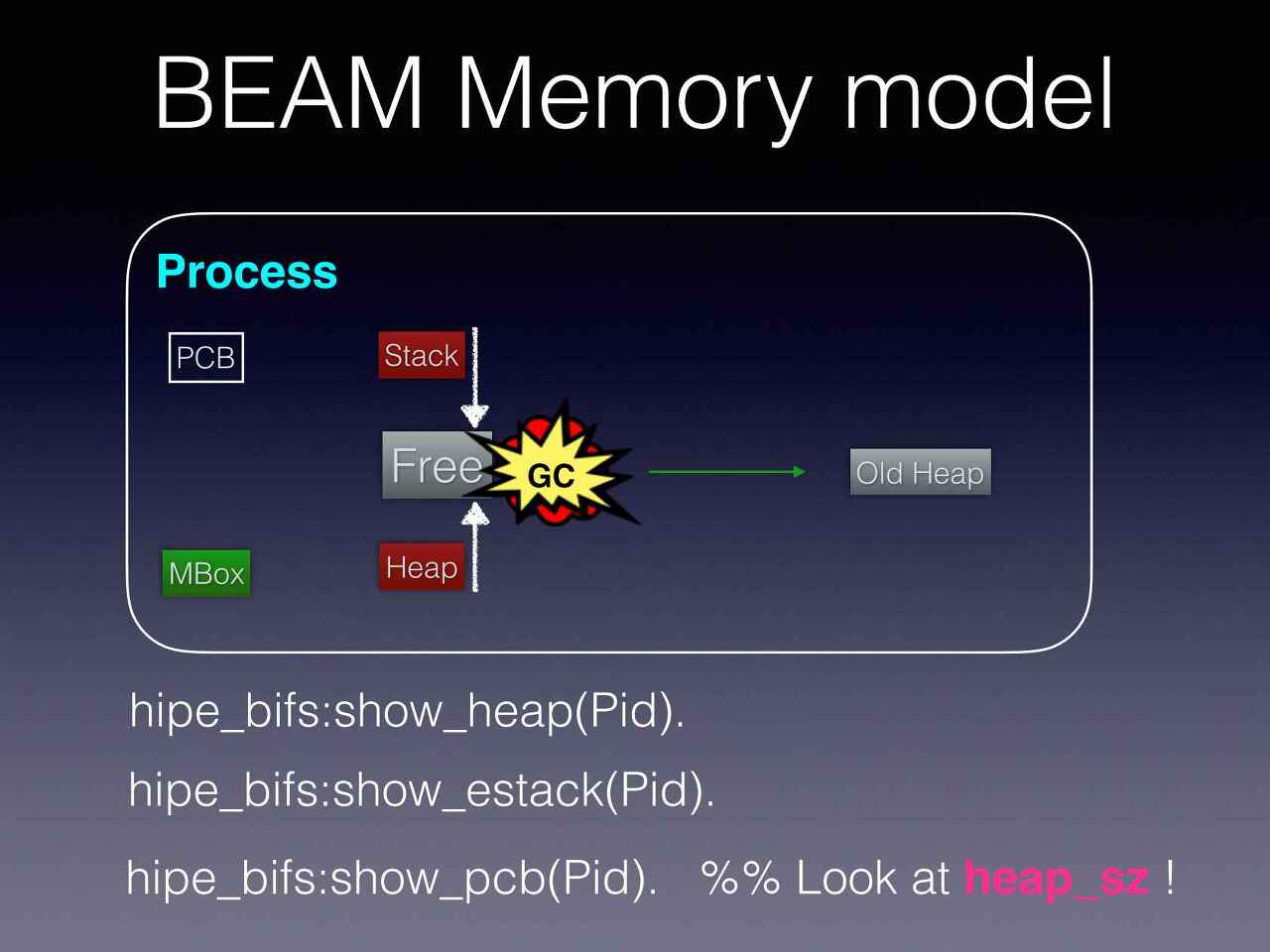

- PCB(Process Control Block)는 정적
- Stack은 아래로, Heap은 위쪽 메모리 주소 방향으로 할당됨
- Stack과 Heap이 만나면 GC가 발생하며 충분한 메모리가 회수되지 않으면 커질 수 있음
- 초기 메모리 주소는 233워드(64bit 기준 1.864kb)으로 매우 저렴함
- 격리되어 있으므로 Stop the world 걱정에서 해방됨
- 격리되어 있으므로 무한루프가 걸렸을 때 태스크를 kill 하기 쉬움
위와 같은 이유로 Erlang VM은 장애가 생겼을때도 고가용성을 제공하며 Soft Realtime 플랫폼으로 작동한다.
디스코드의 메세지 전달을 분배하여 메세지 전달을 최적화한 사례도 눈여겨볼만 하다.
Akka의 성능에 대한 게시물은 거의 찾아보기가 어려웠다.
있다면 디스패치 관련 글.
우선 액터 시스템은 쓰레드와 이벤트를 대체할 수 있으며, [Scala Actors: Unifying thread-based and event-based programming, Event Driven and Reactive Architecture]
Akka의 액터 시스템은 이벤트 루프와 비교했을때 다음과 같이 작동한다.
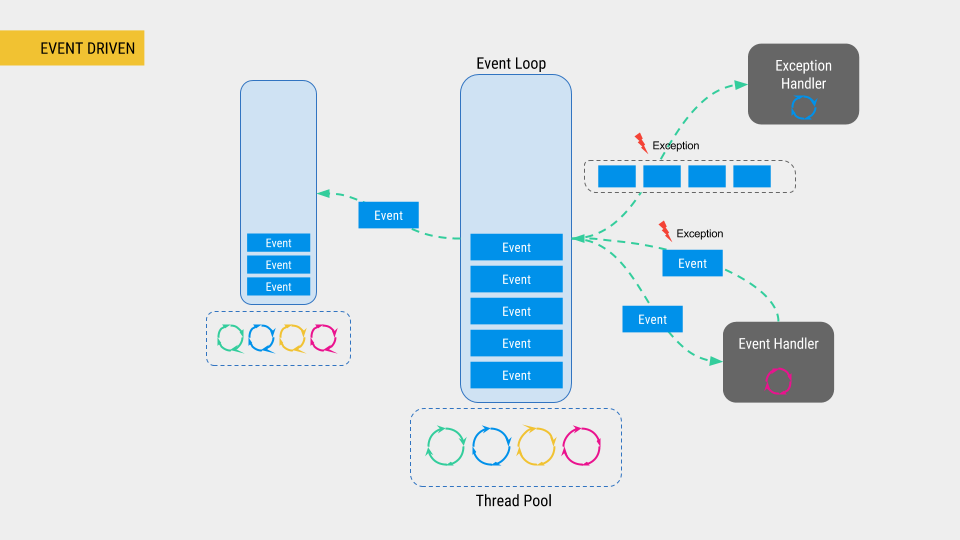

이벤트 vs 액터 조금 더 간략하게 보자면 다음과 같다.
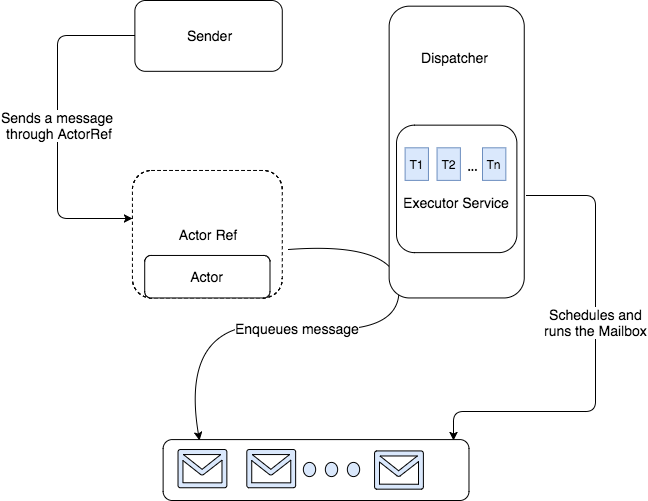
- Sender는 Actor Ref에 메세지를 전달 (Actor자체는 격리되어 있어 접근할 수 없음)
- 메세지 큐(메일박스)에 들어감
- 메세지 디스패처가 스케쥴링에 따라 실행함
디스패처의 역할이 중요하다는 점을 눈치챌 수 있다.
Akka의 디스패처는 3종류,
- 기본: 자동으로 스레드풀에 바인딩
- 고정: 각 액터가 자체 스레드 풀이 있는 CPU 바운드 작업용
- 스레드: 한 스레드에서만 호출을 실행하며, 동시성을 제거해야할 때 사용
여기서는 기본 기준으로 다룬다.
우선 CPU 캐시를 최대한 이용하기 위해 으레 그랬듯 각 스레드에 대해 별도의 대기열을 만들고, 일관된 메일박스를 유지하기 위해 메일박스가 예약되면 전 실행과 동일한 스레드에서 실행한다.
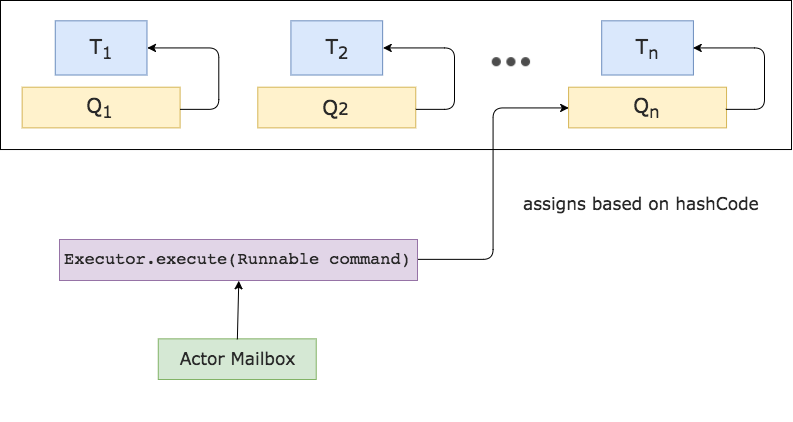
Lock Free를 유지하기 위해 CAS(Compare-and-swap)를 사용하고 스레드 경합을 줄임.
Akka의 진정한 장점이라면 액터를 기반으로 엄청나게 많은 기능을 제공한다는 것이다.
12. 병렬
SIMD와 파이프라이닝
SIMD(Single Instruction Multiple Data)는 SISD(Single Instruction Single Data)와 달리 1번의 명령어로 여러 개의 값을 동시에 계산할 수 있다.

SIMD (Single Instruction Multiple Data)에 대한 집중탐구!
보다시피 벡터/행렬 관련 연산을 할 때 유리한 편이다.
CPU에 있는 파이프라인과 분기예측을 최대한 이용할 수도 있다.
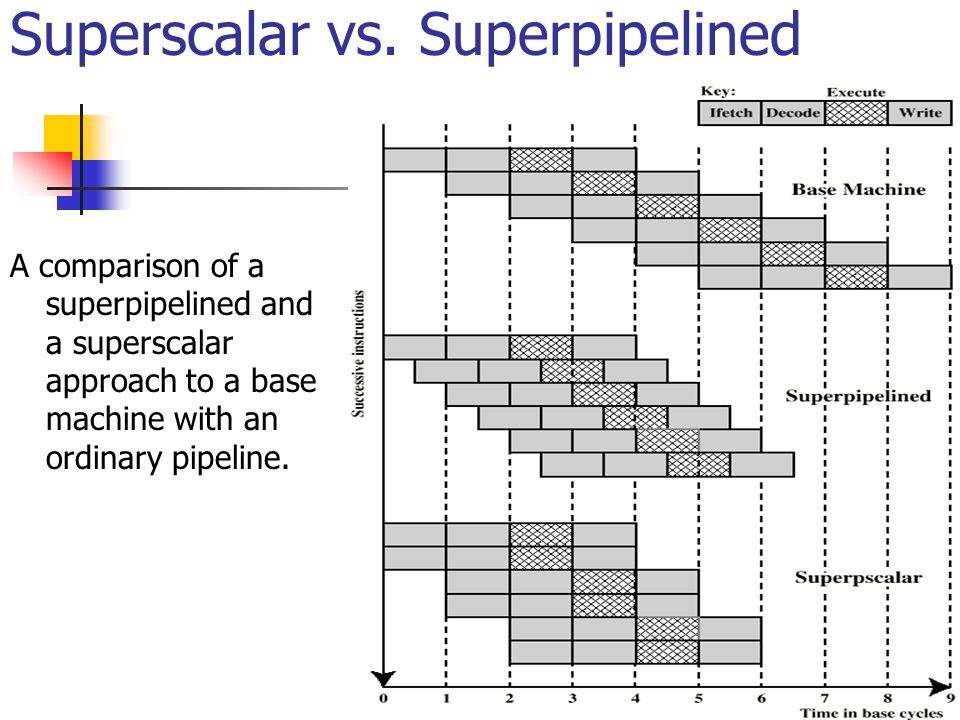
Instruction-Level Parallelism and Superscalar Processors
이를 최대한 이용한 라이브러리 Polars의 I wrote one of the fastest DataFrame libraries를 읽어보자.
OpenMP & MPI
동기화 프리미티브의 임계구역처럼 멀티 쓰레드/프로세스가 필요할 때는 구역을 만들수가 있다.
OpenMP가 대표적인 예이며 for 루프의 부하를 map-reduce 방식으로 적절히 계산해준다고 생각하면 된다.

Introduction to Parallel Programming with MPI and OpenMP
반대로 메세지 패싱 스타일인 MPI도 존재한다.
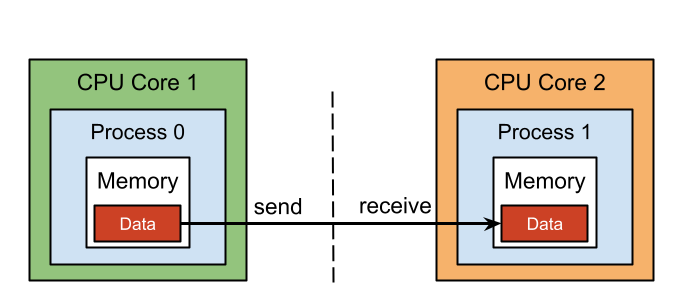
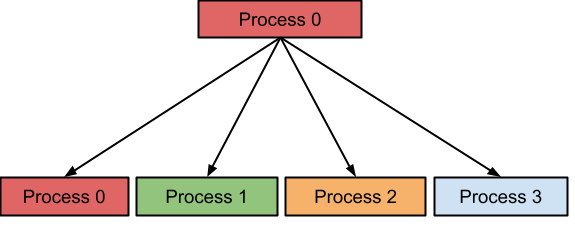
공유메모리인 OpenMP, 분산된 스타일인 MPI 둘의 장점을 모두 이용하기 위해 다음과 같이 하이브리드 방식으로 사용하기도 한다. (NUMA의 관점에서도 생각해볼 수 있을 듯)
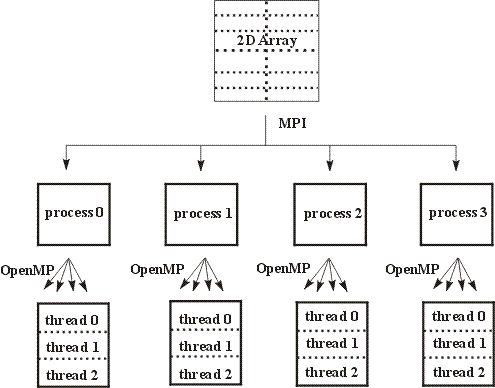
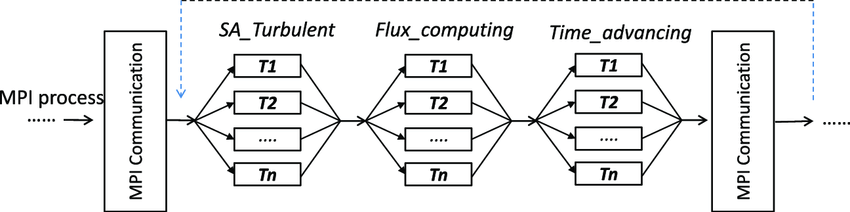
hyPACK-2013 Mode-1 : Mixed Mode of Programming MPI- OpenMP, Parallel multibody separation simulation using MPI and OpenMP with communication optimization
최신 병렬 기법
Cilk는 for 루프뿐만 아니라 spawn 시에도 적절히 병렬화가 되도록 만들어준다.
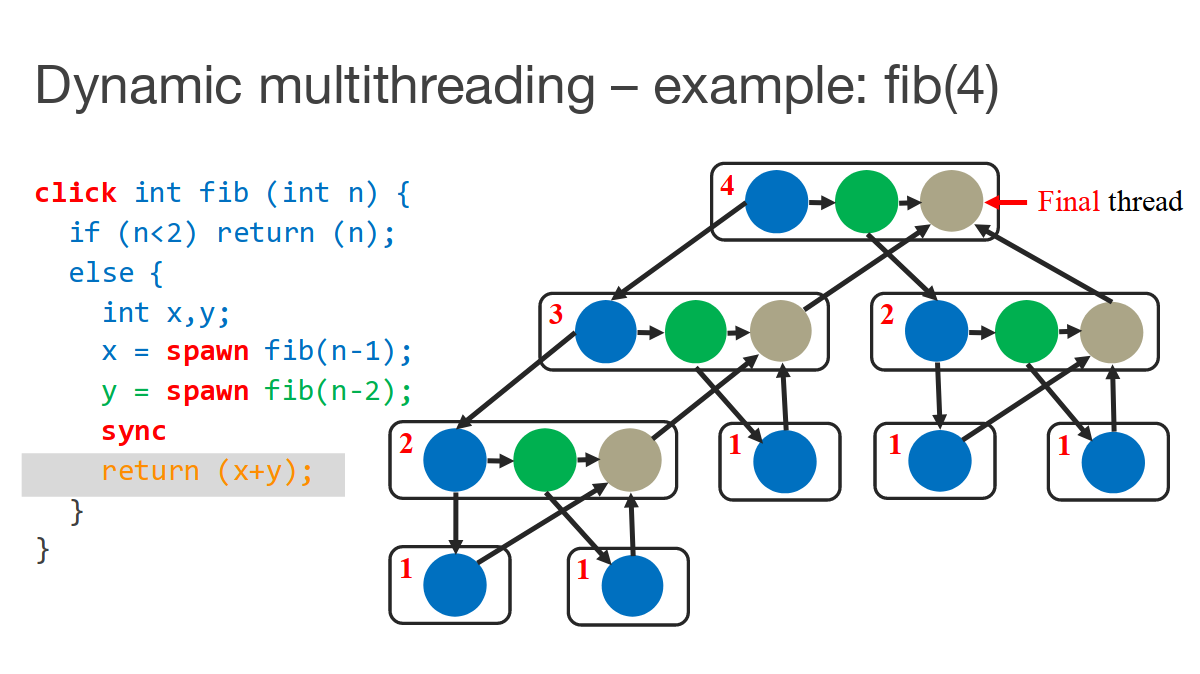
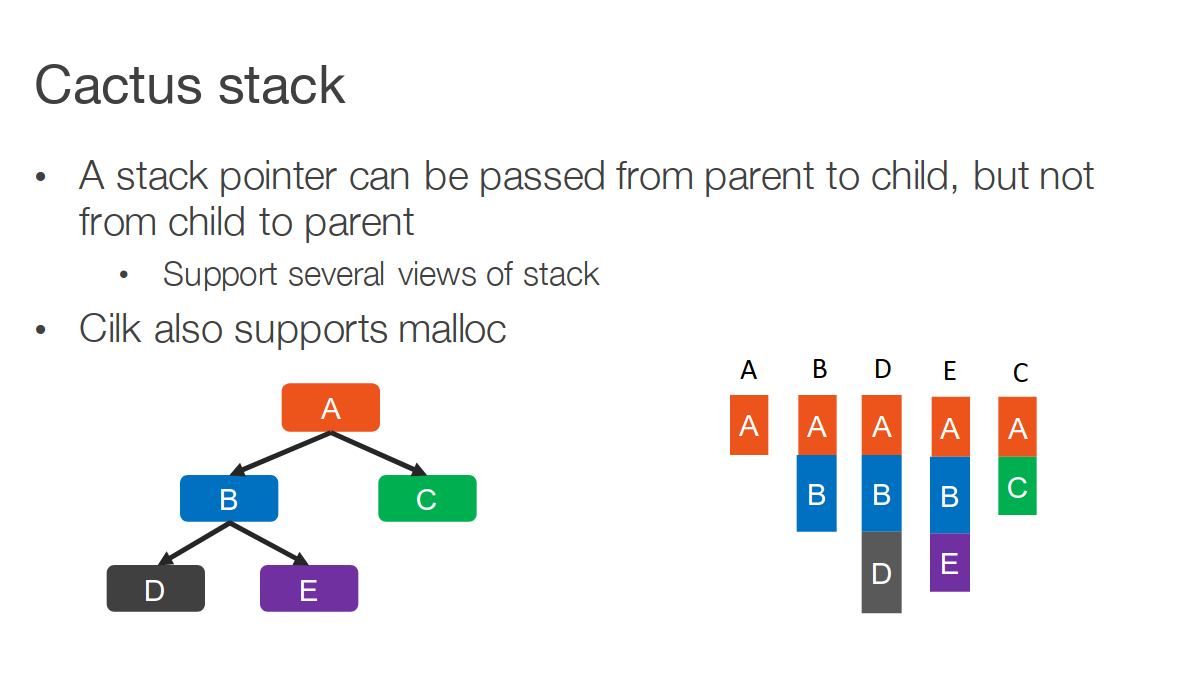
Cactus Stack의 스택포인터가 부모에서 자식으로만 전달된다는 점을 이용한다.
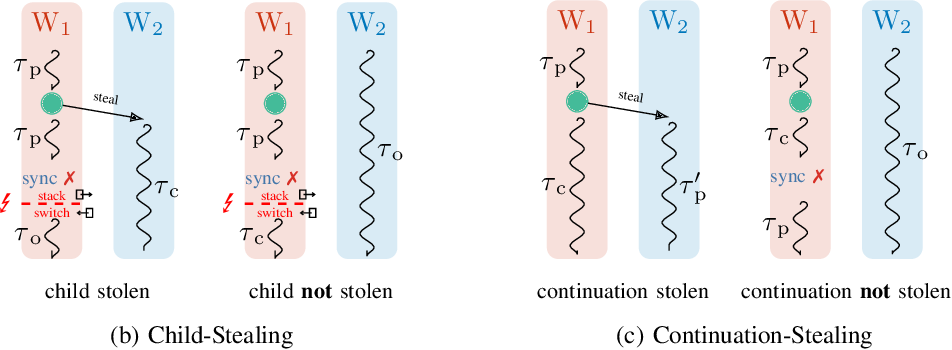
또한 Cilk는 워크스틸링을 지원한다는 점이 특징이라면 특징.
Nowa(소스코드)는 Wait-Free를 달성하기 위해 컨티뉴에션 스틸링(Continuation Stealing)을 사용한다.
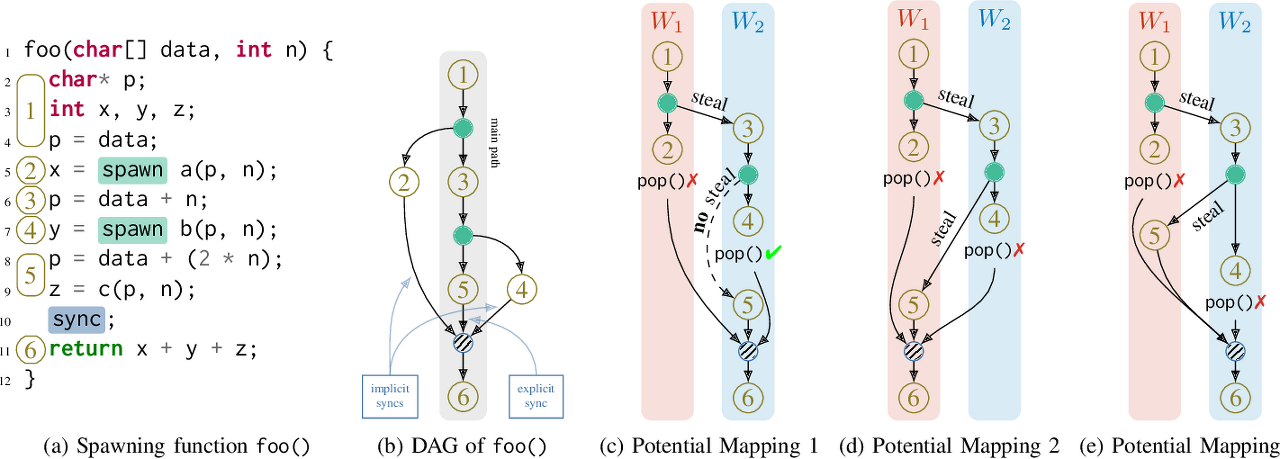
매핑되는 모습을 보면 다음과 같다고 한다.
Emper(소스코드)는 지금까지 나온 방법 대부분이 거의 사용되어 있다.
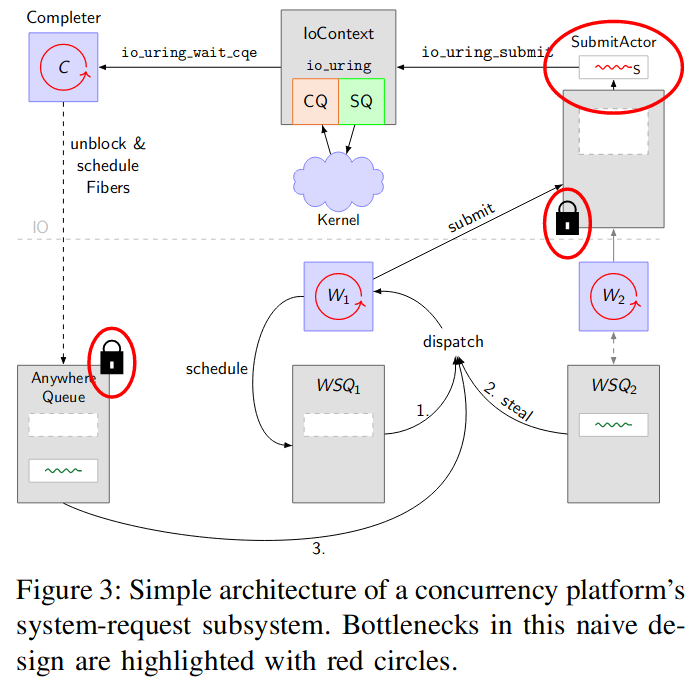
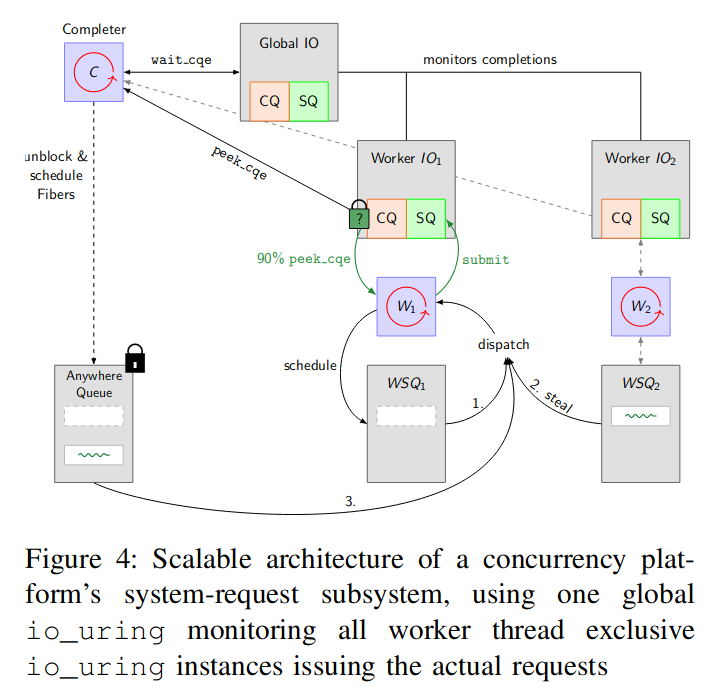
- IO Uring
- 컨티뉴에이션 스틸링
- Local, Global 스케쥴링
- Wait-free Cactus Stack
Rayon은 러스트 언어의 특징을 최대한 활용해 데이터 경합을 제거한다.
- How Rust makes Rayon's data parallelism magical
- Rayon: data parallelism in Rust
- Parallel stream processing with Rayon
람다 아키텍처
조금 더 넓은 범위, 아키텍처 레벨에서 병렬에 특화된 구조도 존재한다.
람다(Lambda) 아키텍처
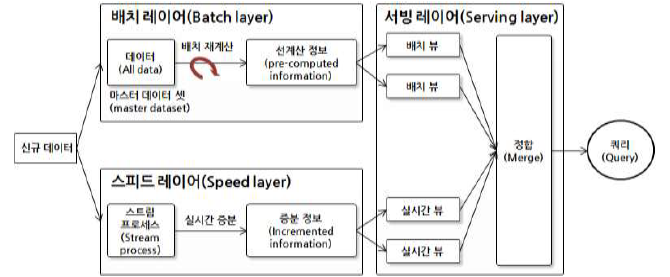
- 배치 레이어: 변하지 않는, 실시간 작업이 불필요한 데이터를 미리 작업해 저장
- 스피드 레이어: 실시간 조회 및 정보를 계산한다
- 서빙 레이어: 배치와 스피드 레이어의 정보를 조합한다.
카파(Kappa) 아키텍처는 보다 단순하게 스피드 레이어를 통과해 배치 계층에 저장되는 형태다.

제트브레인의 Big Data World, Part 4: Architecture나 마이크로소프트의 빅 데이터 아키텍처에 잘 설명되어있다.
13. GPU
파이프라인과 쉐이더
- A trip through the Graphics Pipeline 2011: Index
- Graphics Pipeline Performance
- Balancing the Graphics Pipeline for Optimal Performance
데이터 처리의 또 다른 핫한 분야는 GPU일 것이다.
일반적인 그래픽 파이프라인은 다음과 같다.

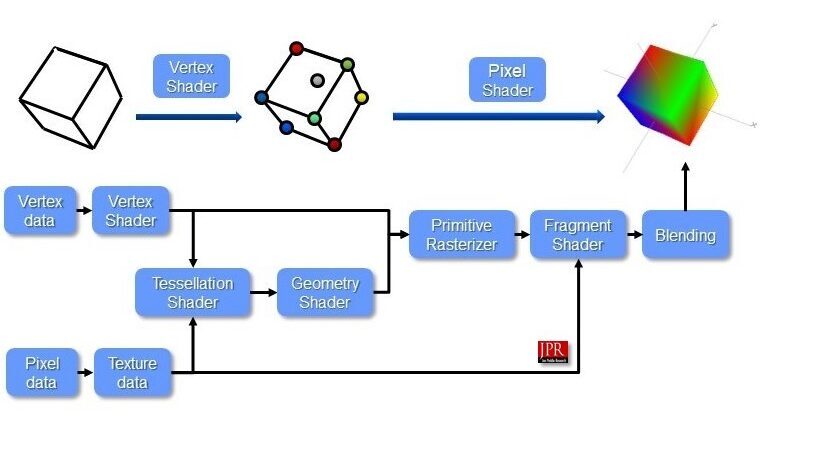
Mesh Shaders Release the Intrinsic Power of a GPU
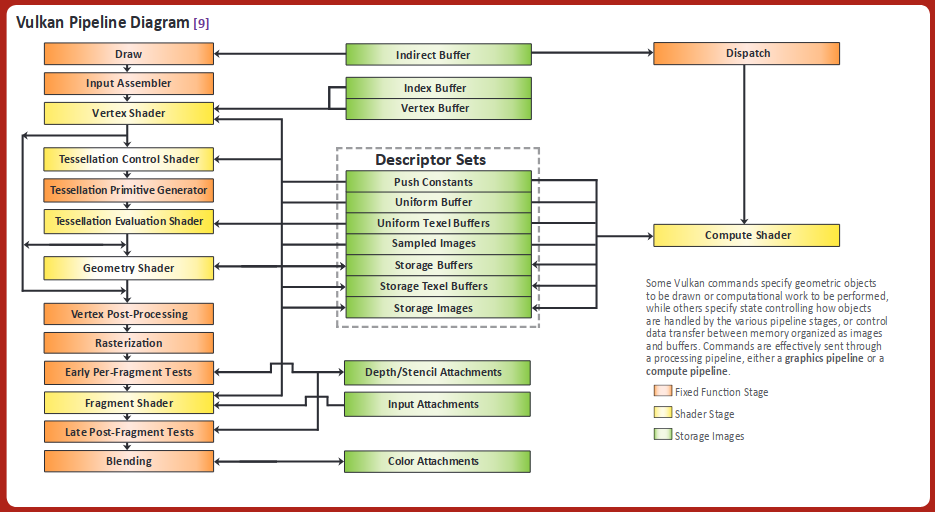
Vulkan 튜토리얼, OpenGL 위키나 Direct3D(11, 12) 문서에 보다 자세히 나와있다.
- 입력 어셈블러(Input Assembler): 인덱스 버퍼를 통해 중복되는 꼭지점(Vertex)를 제거
- 꼭지점 쉐이더(Vertex Shader): 모든 정점(Vertex)에 대해 실행되며, 변환(Transformation)이나 모핑(Morphing) 같은 작업을 한다
- 테셀레이션(Tessellation): 특정 규칙에 따라 표면 세부 정보(subdivide geometry)를 그려 메시 품질을 높힘
- 기하 도형 쉐이더(Geometry Shader): 모든 프리미티브(삼각형, 선, 점)에서 실행되며, 이를 버리거나 더 많은 프리미티브를 출력할 수 있음.
- 래스터화(Rasterization): 프리미티브의 벡터 정보를 래스터 이미지(픽셀)로 만듦
조각(Fragment)으로 구성되고 화면 밖 조각들은 모두 버려지며, 꼭지점 쉐이더가 출력한 속성들은 보간됨
다른 조각의 뒤(z-index, depth)에 있는 조각들 또한 버려질 수 있음 - 프레그먼트 쉐이더(Fragment Shader): 살아남은 모든 조각들에 대해 호출되며, 기록될 프레임 버퍼와 색상 및 깊이 값을 결정함
텍스쳐(Texture) 좌표나 조명의 법선(normals for lighting)등도 포함될 수 있음 - 컬러 블렌딩(Color Blending): 프레임 버퍼의 동일한 픽셀에 매핑되는 다른 조각을 혼합함
투명도에 따라 덮어쓰거나 추가, 혼합될 수 있음 - 프레임 버퍼(Frame Buffer): 다음 화면에 그려질 정보를 담는 메모리로 출력의 목적지
입력 어셈블러/레스터화/컬러 블랜딩은 작업방식이 정해져 있으나 쉐이더를 활용할 수 있는 Vertex, Tessellation, Geometry, Fragment 단계는 코드를 GPU에 업로드해 프로그래머가 원하는 작업 방식을 정의할 수 있다.
위와 같이 쉐이더는 각 단계에서 존재하는 모든 대상에서 돌아가므로, 분기예측에 실패하면 손해라는 이야기를 한번쯤 들어봤을 것이다.
최근 자주 이야기가 나오는 컴퓨트 쉐이더는 그래픽 파이프라인에서 벗어나 GPGPU로 활용할 수 있게 만들어준다.
Nvidia의 Mesh 쉐이더가 활용 예. [AMD는 프리미티브 쉐이더[소개, 분석]를 밀었는데 최근 소식이 없다].

OpenGL 4.6 API Reference Guide
모바일 GPU의 경우 타일 기반의 렌더링을 가지고 있기도 하다. [GPU architecture types explained, Performance Tuning for Tile-Based Architectures, A look at the PowerVR graphics architecture: Tile-based rendering, PowerVR Series 5 SGX Architecture Guide for Developers]
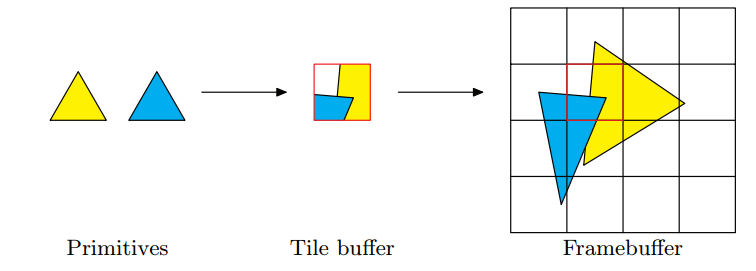

타일 렌더링, 지연 렌더링 타일 기반 지연 렌더링(TBDR, Tile-Based Deffered Rendering)은 바로 그려주는 즉시모드 렌더링(IMR, Immediate-Mode Rendering)과 달리 타일로 만들어 저장/로드한다. (2 path)

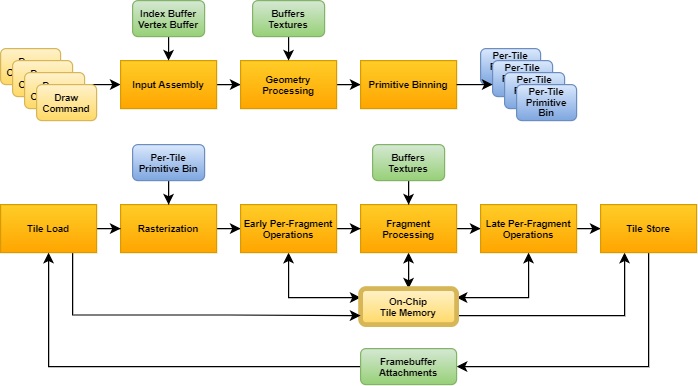
IMR vs TBDR 장점
- 중복되는 타일은 건너 뛸 수 있음
- 프레임 전체를 다루는 IMR에 비해 대역폭을 적게 소모(4K 모니터를 쓴다고 생각해보자)
- 타일의 크기가 적으므로 제약되는 SRAM만으로도 복잡한 렌더링을 수행할 수 있음
- 지연 렌더링을 사용할 경우, 뒤에 있는 물체는 그리지 않음
단점
- 지연 렌더링에서 Geometry와 Fragement 사이에서 타일을 저장하기 위해 DRAM을 접근하여 캐시에서 손해
위와같이 여러 장점을 가지고 있기에 최신 PC GPU들도 타일기반 렌더링을 도입하고 있다. (지연 렌더링은 아님)
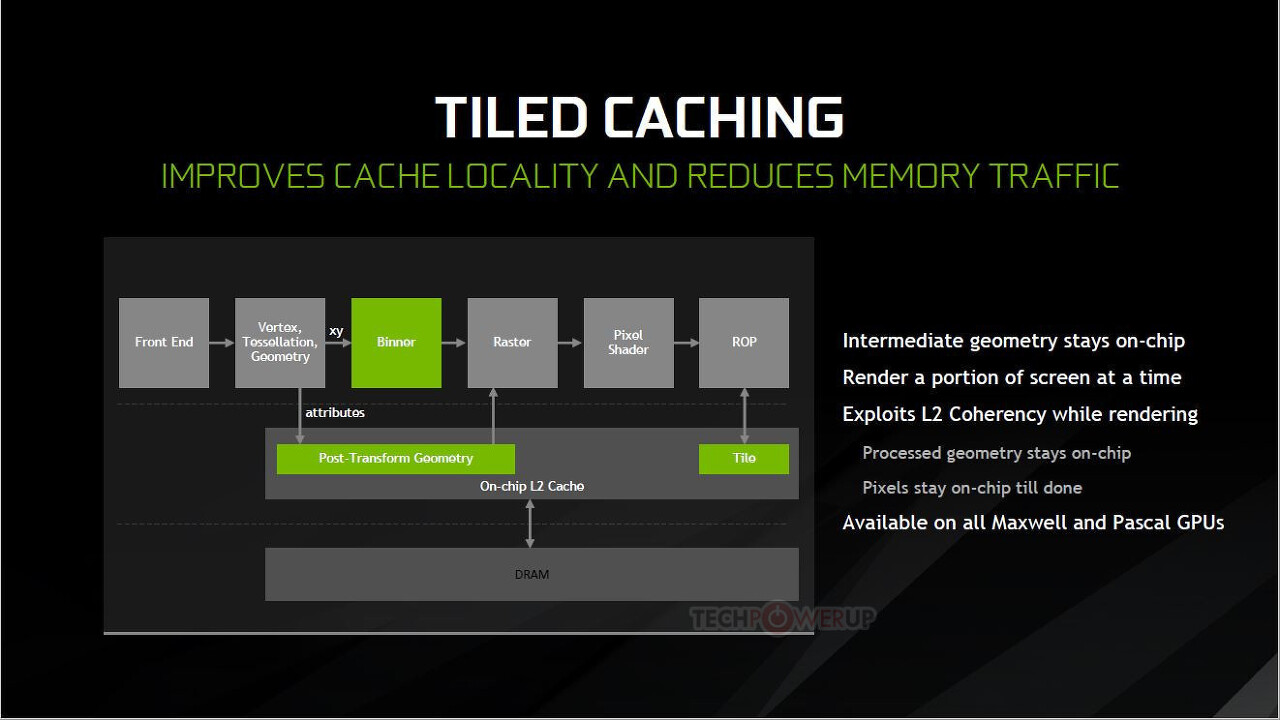
Ndivia의 방식 이러한 흐름속에 최근에는 타일링과 컴퓨트 쉐이더를 활용해 벡터 그래픽까지 GPU에서 실행하려는 프로젝트들도 생기고 있다.
컴퓨트 쉐이더에 관심이 있을 경우 SIMT(Single Instruction MultiThread)에 대해서도 알아보기 바란다.
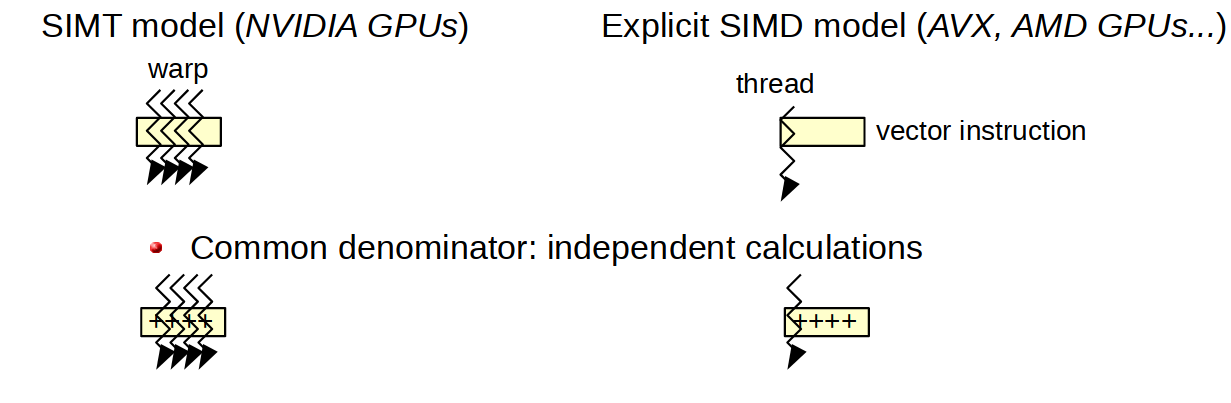
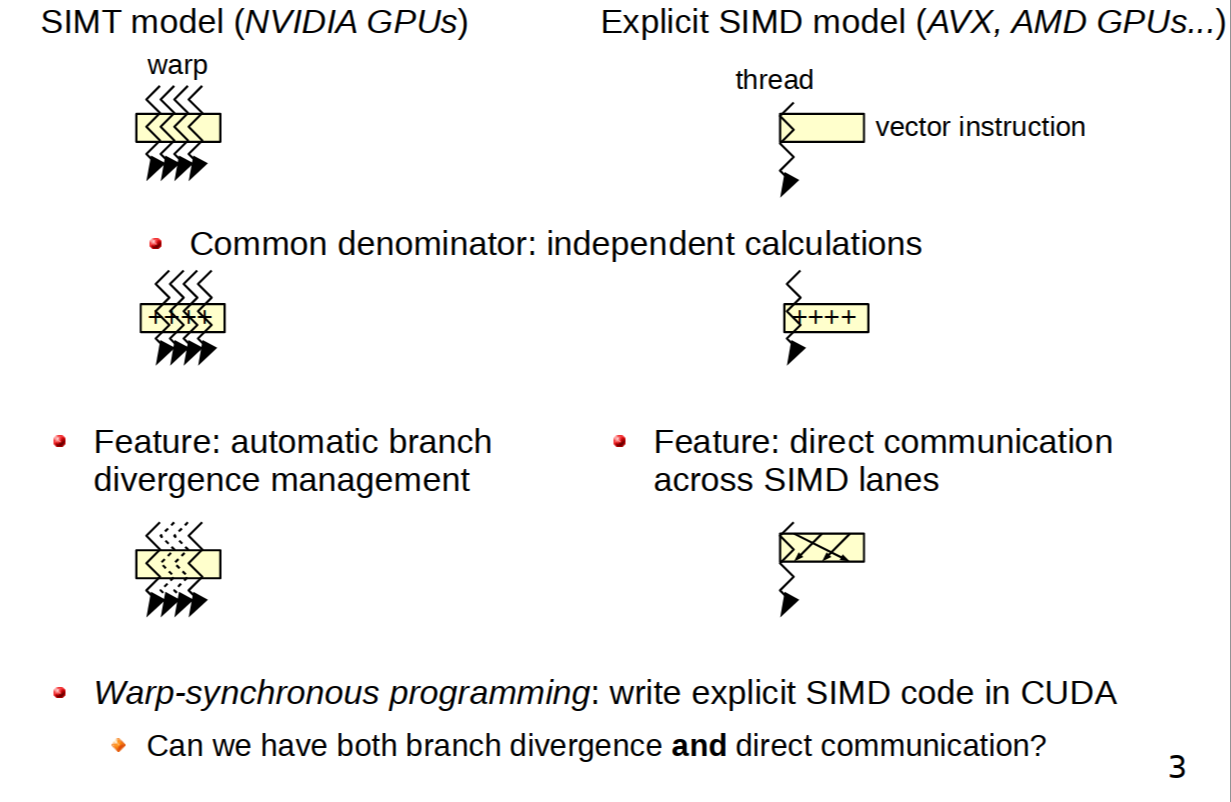
Warp-synchronous programming with Cooperative Groups
벡터 데이터에 동일한 작업을 병렬로 실행하는 SIMD와 달리 여러 스레드가 임의 데이터에 공통적인 명령을 실행하므로 분기명령등에서 차이가 있다.
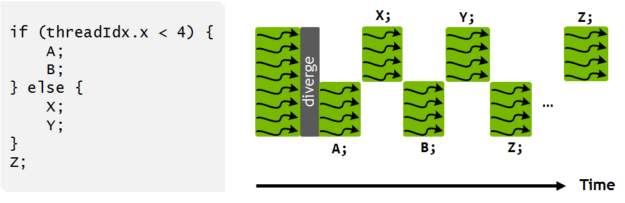
Using CUDA Warp-Level Primitives
모니터
LCD 모니터를 사용한다면 다음과 같이 보여진다.
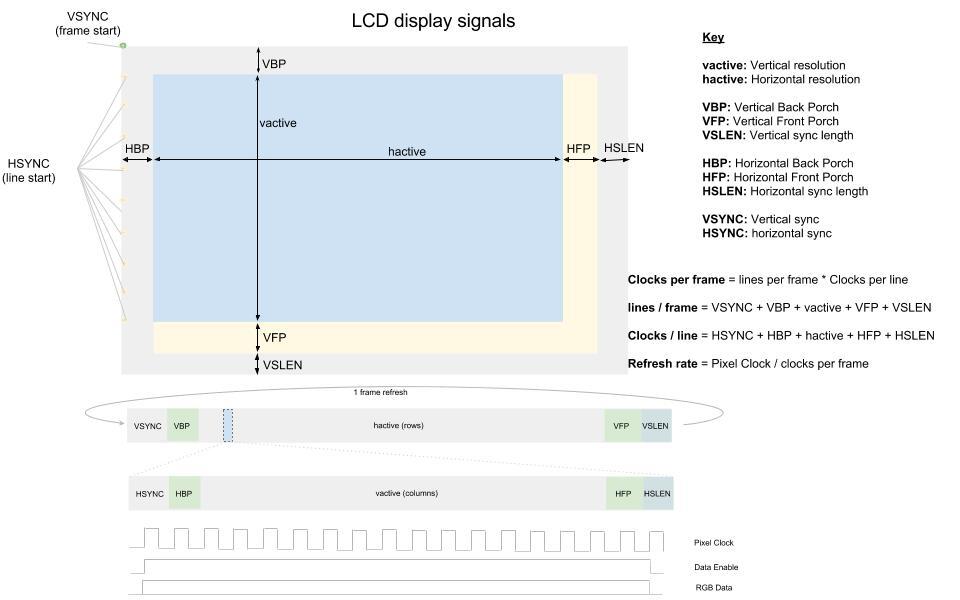
- 수직동기화(V-Sync): 프레임 시작
- 수평동기화(H-Sync): 라인 시작
수직 동기화에 의해 프레임이 시작되 위에서 아래쪽으로 출력되며, 이는 전자빔을 이동하며 쏘는 CRT 모니터의 호환성을 위한 것이다.

CRT 모니터의 표현방식 보통의 모니터는 초당 60프레임을 표시할 수 있다. (60Hz)
16.66ms당 1장씩 보여주어야 한다는 뜻.

60Hz 모니터 여기서 조심해야할 점은 모니터 주사율(Display refresh rate)과 GPU의 프레임 레이트(Frame rate)를 구분하자는 것이다.
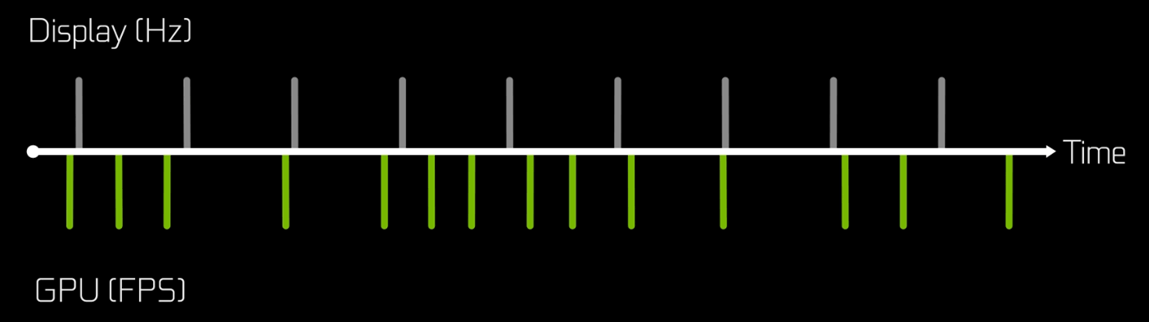
Nvidia: High frame rates could lead to significantly better K/D ratios in competitive titles
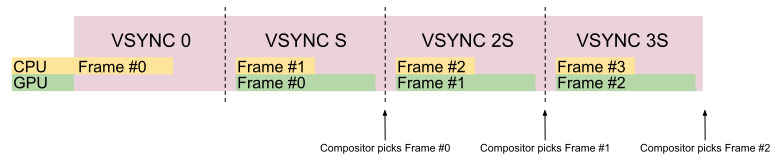
버퍼링
- Multiple buffering
- Platform Integration Aspects: Framebuffer Concepts
- Triple Buffering
- Swapchains and frame pacing
GPU가 프레임버퍼를 갱신하면, (최신 그래픽 시스템에서는 프레임버퍼가 비디오 메모리에 존재)
디스플레이 컨트롤러가 프레임 버퍼를 읽어 디스플레이에 출력한다.
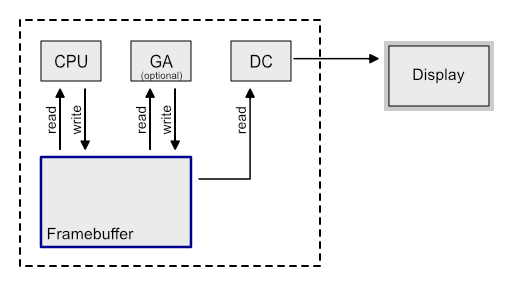
싱글 버퍼 그러나 문제가 있다.
프레임 버퍼에 쓰는 속도가 읽는 속도보다 느리기 때문에 깜박임(Flickering)이나 티어링(Tearing) 발생하는 것.
보통 60FPS를 달성해야 깜박임이 없다고들 설명한다.
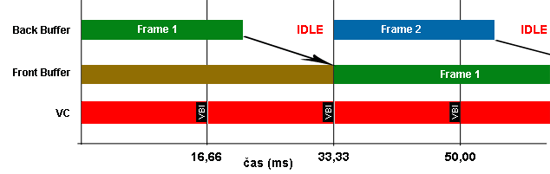
이를 해결하기 위해 더블 버퍼링이 탄생했다.
버퍼를 하나를 추가해 미리 정보를 써놓고 복사를 하거나 교환(Swap)을 하자는 말이다.
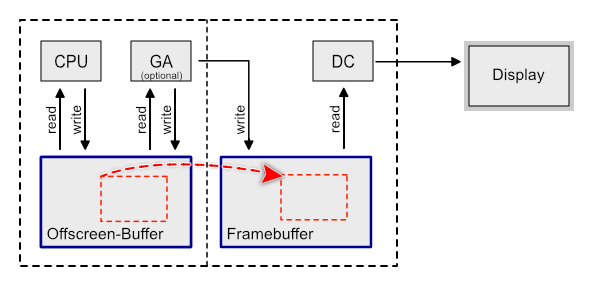

복사 vs 교환 - 복사: 변경된 부분만을 업데이트하는 방식
여전히 쓰기가 읽기보다 느리므로 변경이 많은 경우 적합하지 않다 - 교환: 프론트와 백버퍼를 완전히 바꾸는 방식
기본적으로 소모하는 리소스가 많으므로 변경이 적은 경우 불리
맞바꾸는 작업을 플리핑(Flipping), 변경가능한 버퍼 컬렉션을 스왑체인(Swap Chain)이라고 부른다.
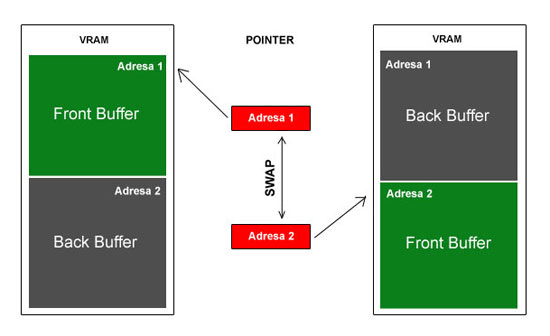
플리핑(Flipping) 플립하는 방식을 보통 더블 버퍼링이라 표현하며, 역시 만능은 아니다.
Frontbuffer에서 데이터를 출력하는 동안 Backbuffer의 내용으로 바뀐다면?

중간에 출력되면? 찢어지는 현상(Tearing)이 일어나게 된다.

티어링 이를 해결하는 간단한 방법은 수직동기화(v-sync)와 타이밍을 맞추는 것이다.
모니터가 갱신되는 타이밍에 맞추기 때문에 추가적인 오버헤드와 레이턴시가 존재한다.
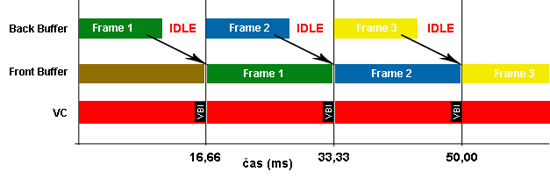
성능 충분, 성능 부족 - 성능 충분: 모니터 주사율보다 빠르게 그릴 수 있어야 하지만 기다려야 하므로 레이턴시가 발생하며, 성능을 활용할 수 없음
- 성능 부족: 동기화 타이밍이 지나버리면 다음 동기화 타이밍까지 지연이 생김 (화면끊김, Stuttering)
위와 같은 문제로 수직동기화를 끄면 대기시간이 줄어들지만, 다시 찢어지는 현상을 감안해야 한다.
때문에 나온 해결책은 트리플 버퍼링이며 크게 두가지 방식이 존재한다.
직렬화 vs 병렬화 - 직렬화: 백버퍼를 미리 그려놨다면 세번째 버퍼까지 준비해두었다가 수직동기화 타이밍에 맞춰 업데이트
- 병렬화:
백버퍼1를 미리 그려놓으면 프론트버퍼와 교체하는 동시에 다음 프레임을 백버퍼2에 그림
백버퍼2에 미리 그려놓으면 프론트버퍼와 교체하는 동시에 다음 프레임을 백버퍼1에 그림
직렬화 방식은 수직동기화를 이용해 교체하기 때문에 성능이 좋은 GPU일 경우 GPU의 성능을 최대한 이용하지 못하고 지연이 생긴다.
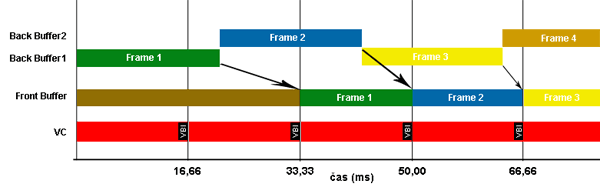
직렬화 - 지연문제 반대로 병렬화 방식은 GPU의 성능을 최대한 이용해 준비되면 바로바로 교체하는 방식이기 때문에 지연은 적지만 전력소모 문제가 있을 수 있으며 발열에 의해 오히려 성능제한이 생길 수도 있다.
역시 보통 트리플 버퍼라고 하면, 후자인 병렬화 방식을 지칭한다.

정리 버전 수직동기화
방금 전에는 버퍼의 관점으로 살펴보았다면, 이번에는 수직동기화의 관점으로 살펴보자.
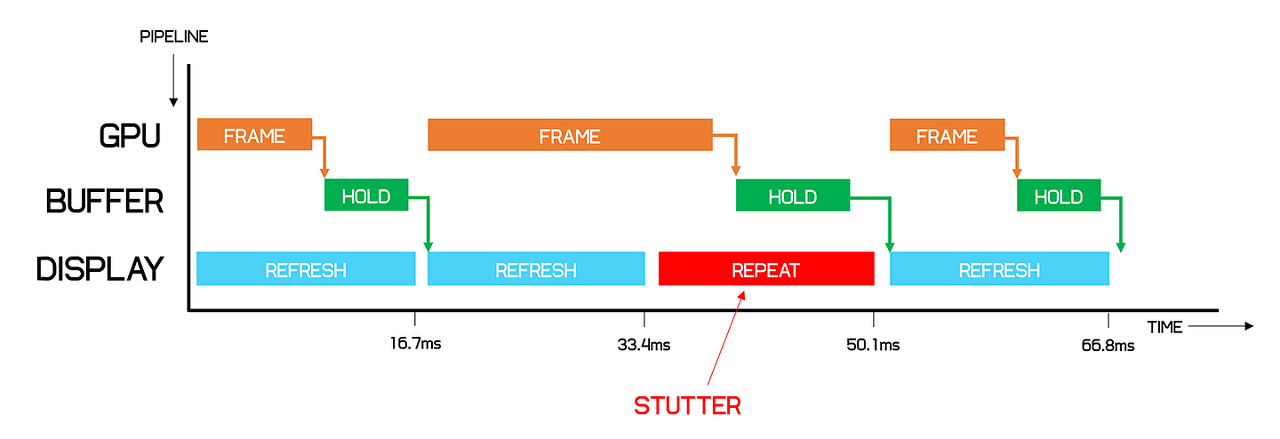
- 성능 충분: 모니터 주사율보다 빠르게 그리면 티어링 문제가 생기기에 문제가 없으며, 전력과 발열문제가 있음
지연시간동안 계산하지 않으면 다음 프레임을 그릴시간 부족해질 수도 있음 - 성능 부족: 동기화 타이밍이 지나버리면 다음 동기화 타이밍까지 지연이 생김
모니터보다 프레임이 잘 나온다면 수직동기화에 맞추는 것도 나쁘지 않다.
그러나 프레임이 안나오는 상황이라면 다음 동기화 타이밍에 맞추기보다 즉시 교체를 해 지연을 줄일 수 있다.
Nvidia의 적응형 수직동기화(Adaptive V-Sync)/AMD의 동적 수직 컨트롤(Dynamic V-sync Control)라 불리는 기술로 일정 이상의 프레임일때만 수직동기화를 사용한다.

V-Sync를 통한 프레임 제한 프레임이 안나오는 상황에서 개선했으니, 프레임이 잘 나오는 상황에서 문제를 보다 명확하게 정의하고 개선법을 확인해보자.
첫번째는 앞서 idle시간 동안 계산을 못해 다음에 계산이 많이 필요하면 프레임을 만들때 문제가 생길 수 있다는 점.
두번째는 입력 지연이다.
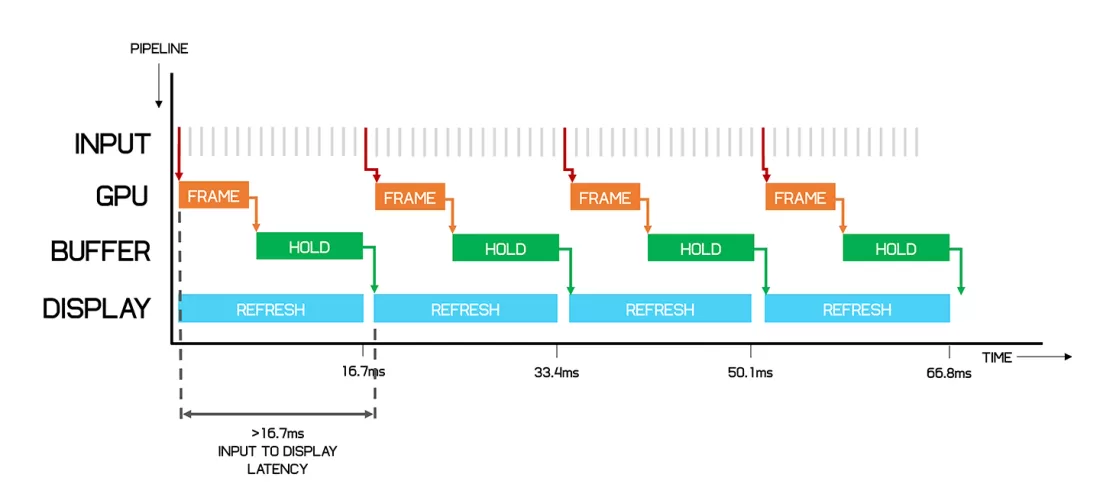
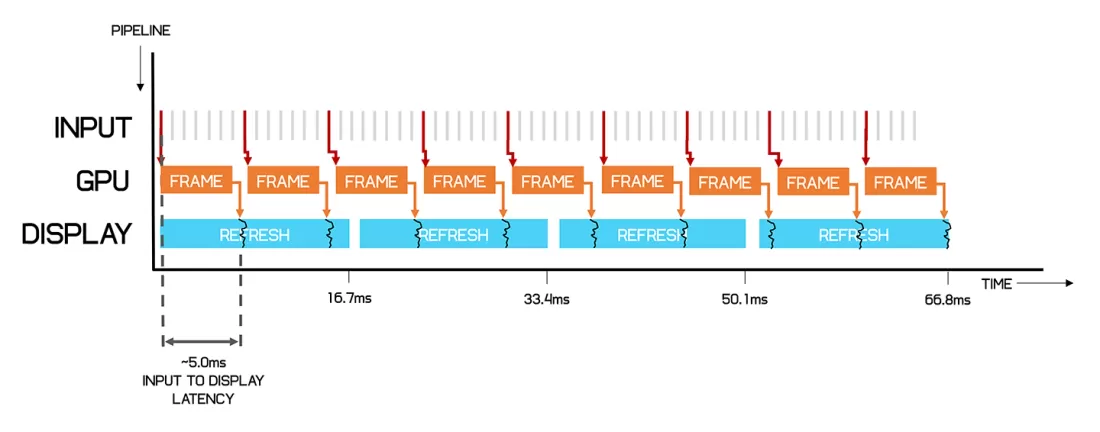
V-Sync 입력지연 vs 티어링 Nvidia의 Fast Sync/AMD의 향상된 동기화(Enhanced Sync)는 V-Sync를 사용할때 삼중버퍼링을 이용해 미리 다음 프레임을 만들어 계산이 많이 필요한 상황에서도 프레임을 유지하게 만들어주며 입력을 반영한 프레임을 미리 준비해 지연을 줄여준다.
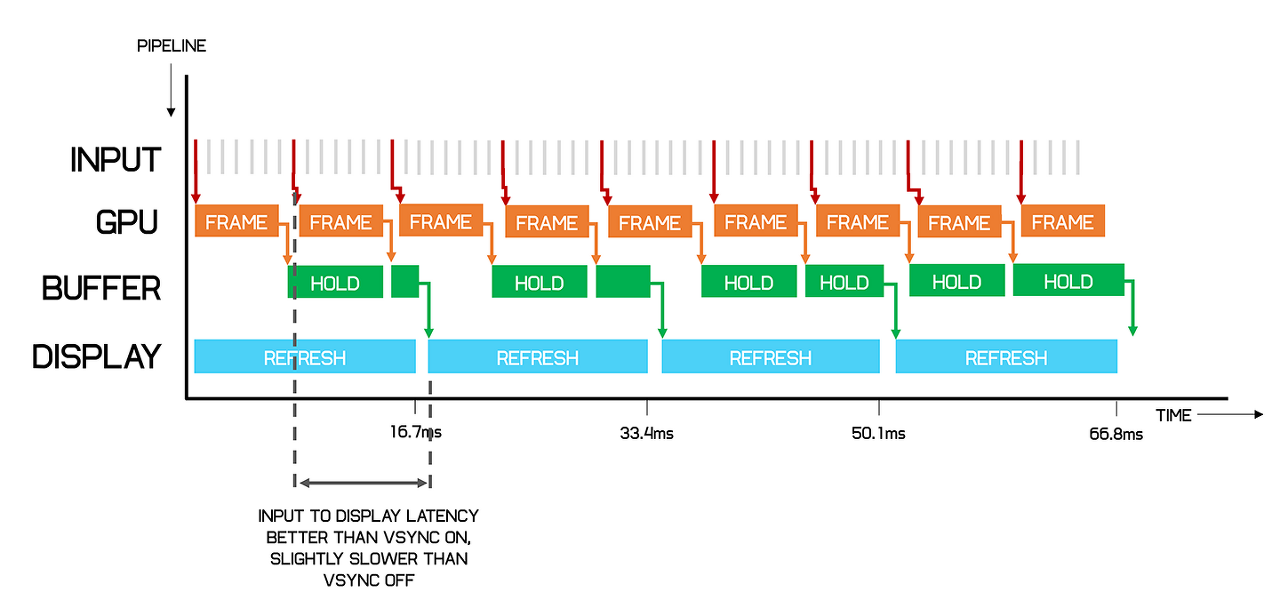

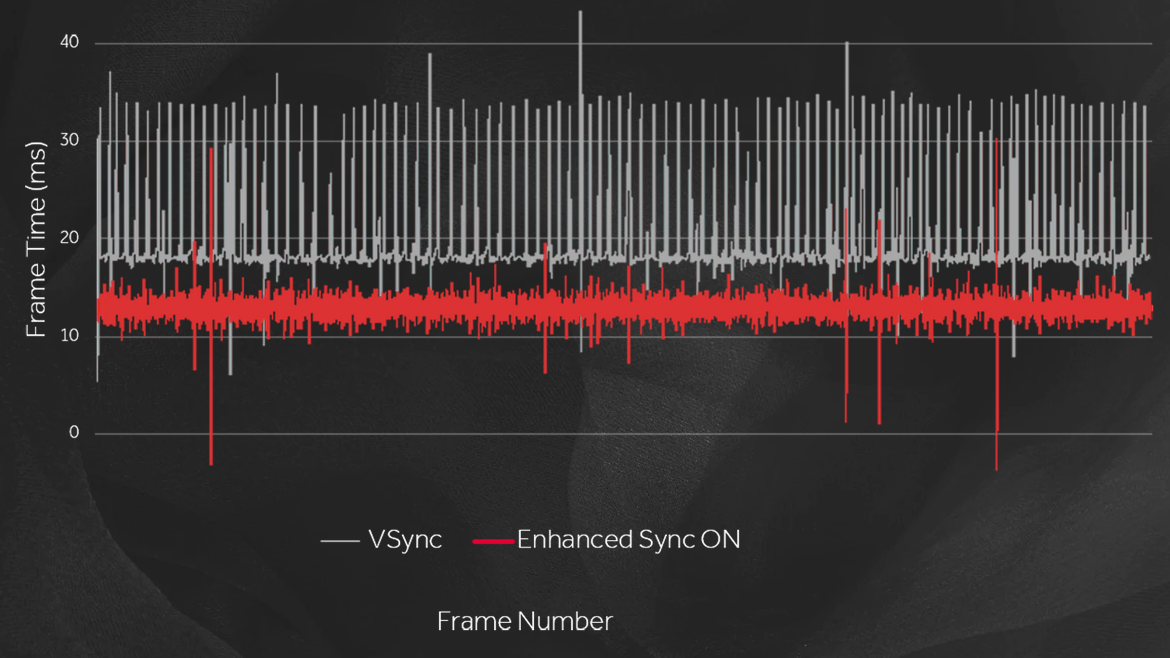
향상된 지연시간 그런데!! 여기서 의문, 디스플레이의 주사율(V-Sync 타이밍)를 변경해릴수는 없을까?
Nvidia의 G-Sync/AMD의 Free Sync는 가변 주사율를 지원하게 만들어 지연 문제 해결에 도움을 준다. (때문에 지원하는 모니터를 가림)
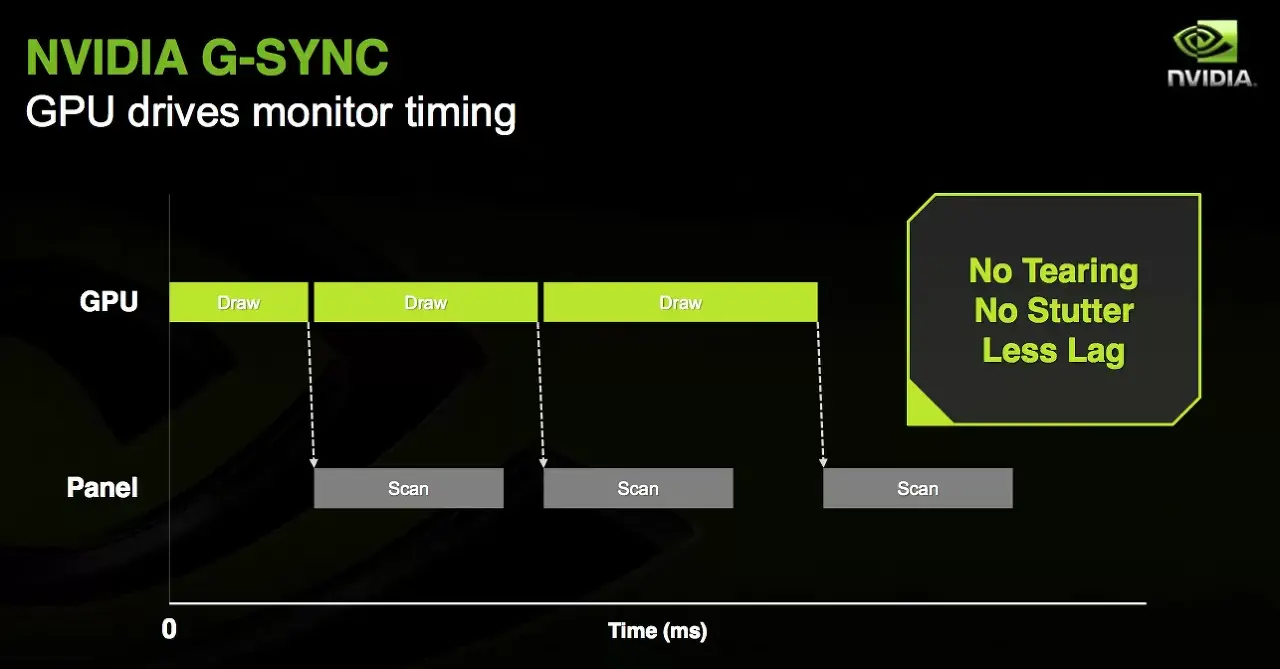
가변 주사율 가변 주사율이 있다지만 주사율의 상하한 폭은 여전히 존재한다. (예: 60~120Hz)
만약 24FPS가 지속적으로 나오고 있다고 가정할 때 60Hz가 최저 주사율인 모니터인 경우는 2장, 3장이 반복적으로 표시되며(2:3 pull-down), 끊기거나 부자연스러워 보인다(Judder).
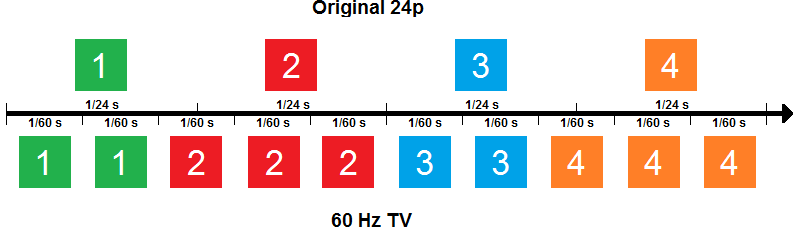
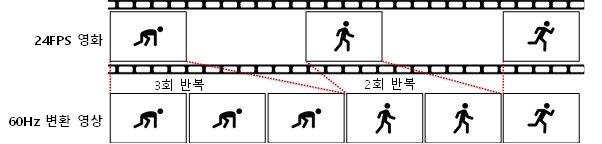
Our TV Motion Tests, 가상현실을 위한 디스플레이 구동 기술
'끊김'이 발생하면 실제로는 제 시간에 맞추어 렌더링이 되고 있음에도 보는 사람 입장에서는 성능에 문제가 있다 느낄 수 밖에 없다.
그래서 나온방식이 LFC(Low Framerate Compensation).
정수배(예: $24 \times 3 = 72$, $24 \times 5 = 120$)로 표현해주면 끊기지 않는 듯 한 움직임으로 느끼게 된다.
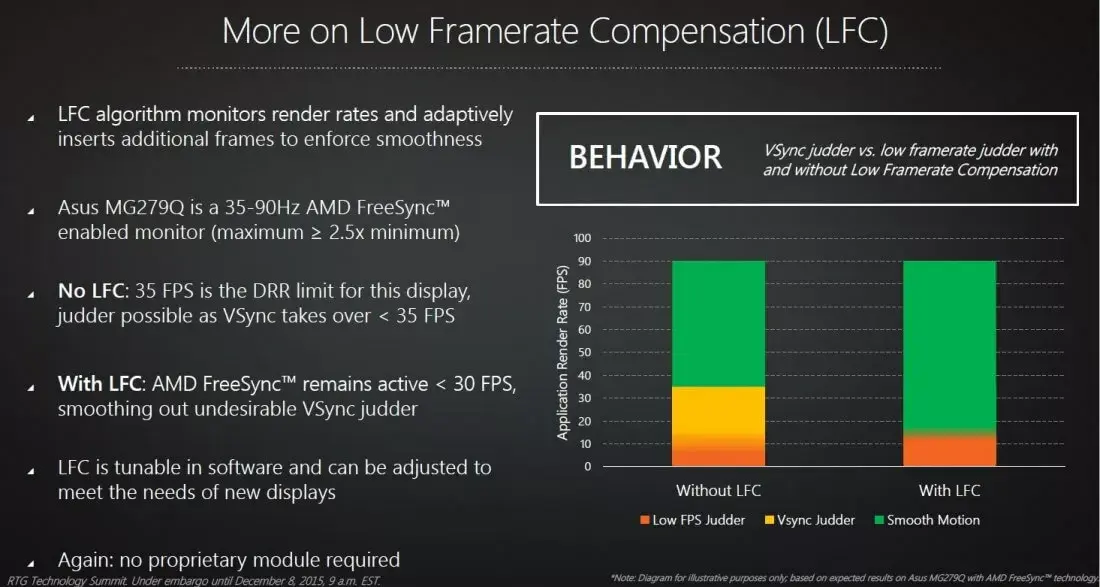
잠시 정리를 해보자.
- FPS >= 최대 주사율: V-sync + 트리플 버퍼링
- 최대주사율 > FPS >= 최소 주사율: 가변 주사율
- 최소 주사율 > FPS: 정수배 가변 주사율
정도가 되겠다.
참고로 보통 게이밍 모니터는 48~144Hz의 가변 주사율를 가진다.
프레임 페이싱과 빔 레이싱
- What is frame pacing, and why it matters in games? Detailed explanation for everyone
- Add Beam Racing/Scanline Sync to RetroArch (aka Lagless VSYNC)
한발자국만 더 가보자.
하드웨어가 아닌 소프트웨어 중점을 둔 방식으로 말이다.
프레임 레이트가 왔다갔다하면 문제가 없을까?
게이밍 모니터처럼 하드웨어 솔루션이 없는 사람이라면 지연과 끊김문제까지 겹쳐서 큰일이 아닐 수가 없다.
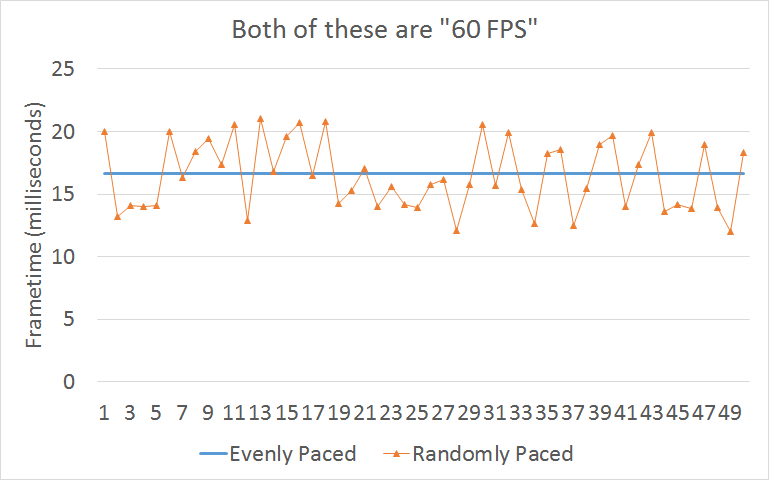
균일 vs 랜덤 프레임 페이싱(Frame pacing) 관련 라이브러리는 로직을 디스플레이와 맞추어준다.
가변 주사율(Free Sync, G-Sync)와 달리 소프트웨어적으로 처리보자는 뜻이다.
안드로이드의 Swappy(프레임 페이싱, Frame Pacing Library)가 좋은 예이니 살펴보자.
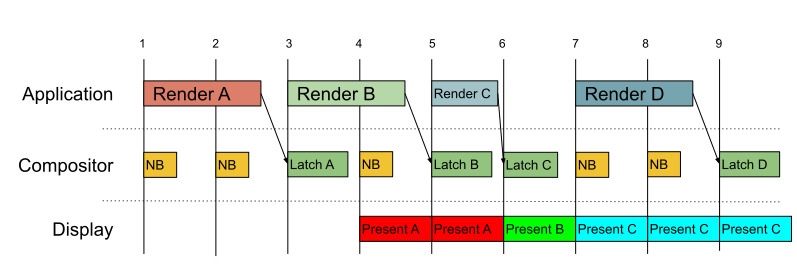

- 짧은 프레임(성능 충분): 프레임을 빠르게 보여주는 대신 버퍼링해 정시에 보여줌

- 긴 프레임(성능 부족): 다음 프레임이 늦음을 감지하고, 대기하여 일관적이게 만들어줌
CPU와 GPU의 워크로드 타이밍도 정하는 기능을 파이프라인이라는 이름으로 제공해주기도 한다.

파이프라인 vs 비 파이프라인 - 파이프라인: V-Sync 타이밍을 기준으로 CPU와 GPU 워크로드를 분리
- 비 파이프라인: 모든 워크로드가 단일 스왑 간격을 가짐 (지연시간이 더 낮음)
또한 안드로이드의 Swappy는 스왑 간격을 자동적으로 선택(예: 30Hz/60Hz), 자동 파이프라이닝 선택, 가변 주파수 지원등 여러 기능을 제공해준다.
유니티도 비슷한 고민을 가지고 접근한적 있으니 확인해보기 바란다. (Fixing Time.deltaTime in Unity 2020.2 for smoother gameplay: What did it take?)
AMD의 경우 멀티 GPU일 경우 번갈아 프레임을 생성해 일관된 프레임을 얻기도 했다.

AMD Doubles Down On mGPU Frame Pacing
반대로 엔디비아는 일관된 프레임 자체보다는 지연 문제에 커다란 관심을 가지고 있으며,[How To Reduce Lag - A Guide To Better System Latency]
Understanding and Measuring PC Latency
비파이프라인 방식에 중점을 둔 Reflex라는 SDK를 제공해주고 있다. [Introducing NVIDIA Reflex: Optimize and Measure Latency in Competitive Games]

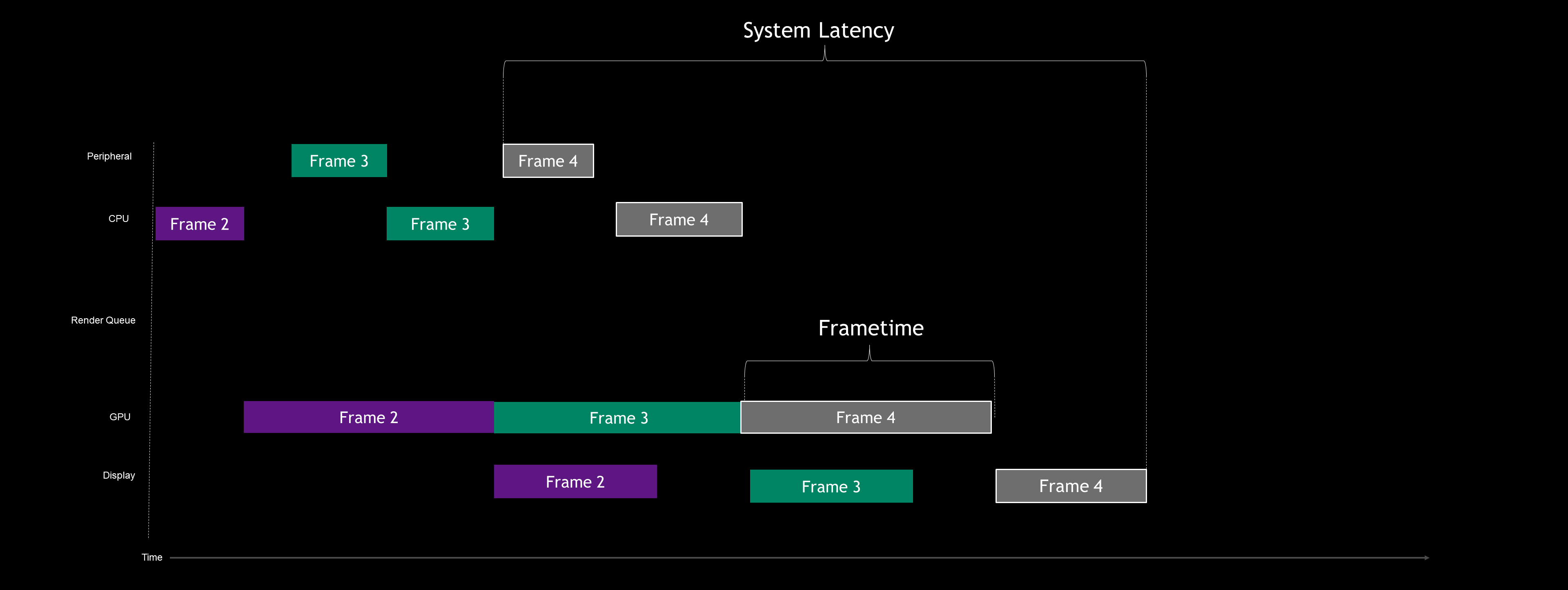
적용 전 / 후 마치 CPU 중심 파이프라인과 비슷하게 만들어졌다고 한다.
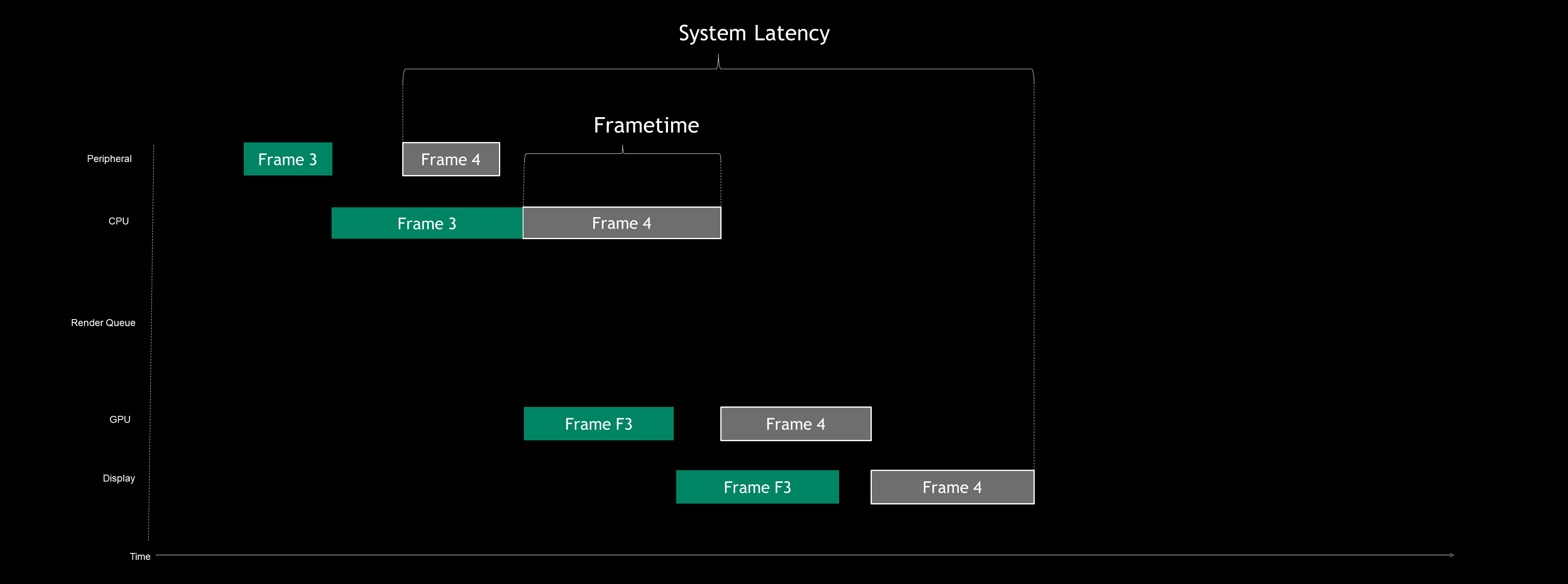
마지막으로 수직동기화 없이도 레이턴시를 줄이고 티어링까지 없는 방법이 존재한다!!(심지어 프레임버퍼도 없어도 됨) [Blur Busters Lagless VSYNC ON Algorithm For Emulators: True Beam Racing, Reducing latency in mobile VR by using single buffered strip rendering, 옛날 게임의 최적화 기법]

beam racing - 한 화면을 한번에 업데이트 하는 대신 실시간으로 렌더링
- 처음으로 다시 올라가는 타이밍이 곧 수직동기화 타이밍이나 다름 없으므로 v-sync를 사용하지 않아도 됨
- 동기적이므로 티어링 현상이 일어나지 않음
단점은 구현이 상당히 까다로우며 짧은 시간안에 작업을 완료해야 한다.
예륻 들어 OpenGL의 렌더링은 비동기적으로 실행되므로 GPU와 동기화 타이밍 맞추기가 어렵다.
또한 수직동기화가 없기 때문에 매번 가로 프레임이 렌더링 되면 업데이트해 병렬화된 삼중버퍼링처럼 상당한 자원이 소모될 수 있다.
옛날 게임기들은 요구 그래픽이 낮았기에 적시에 처리가 가능했으며, 프레임버퍼도 존재하지 않던 시대에 고육지책으로 만든 트릭이다.
실시간 렌더링의 어려움을 개선하려면 구역을 나누어 처리 해버릴 수 있다.

Beam chasing strip rendering 스캔라인 구역별로 나누어지기 때문에 타일 렌더링과 결합하여 병렬적으로 만들 수 있을 것으로 보인다. [Bitmap Data, Efficient GPU Path Rendering Using Scanline Rasterization]
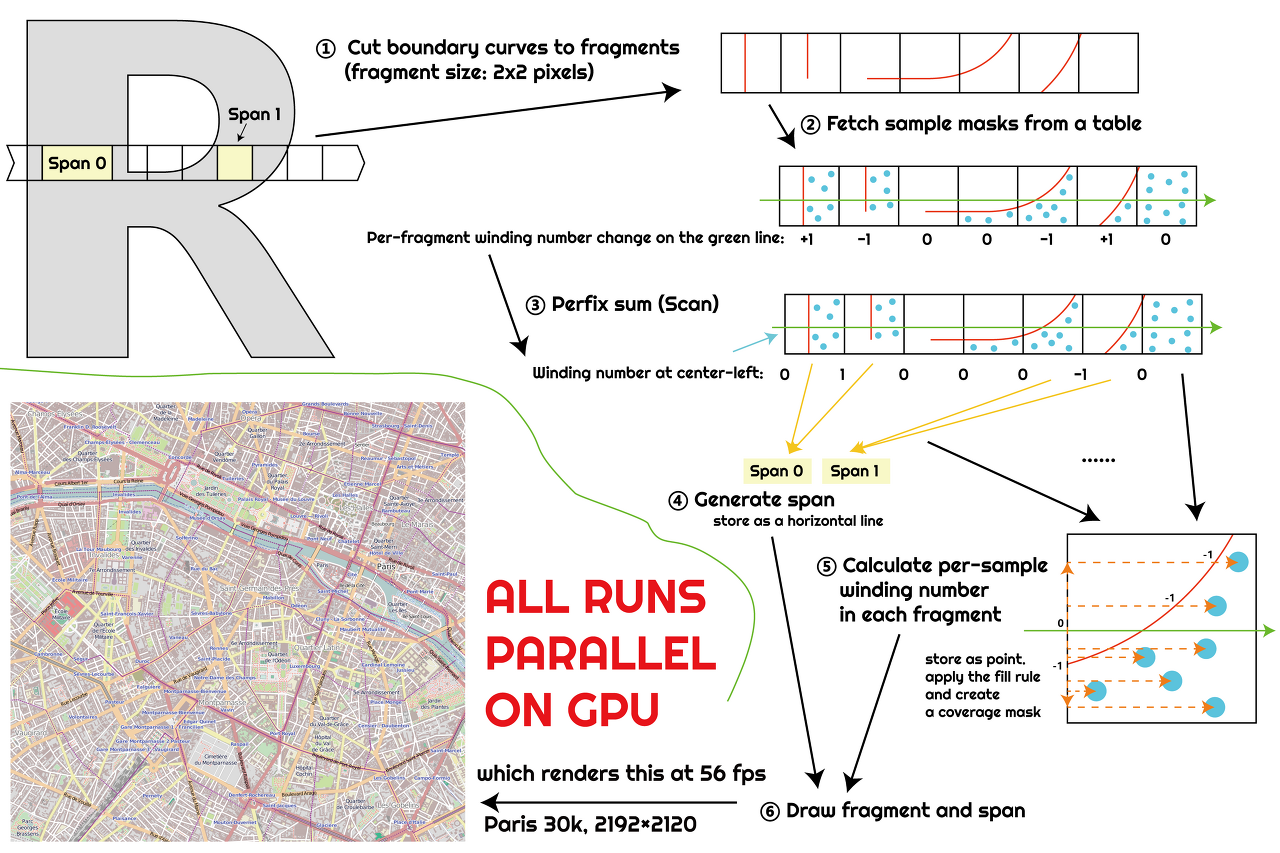
단, 각 스트립 간 지터(jitter)가 문제가 있으므로 현대적인 방식으로 사용하려면 프레임 페이싱등을 이용해 보완해야 할 듯하다.
그럼에도 불구하고 스캔라인 스트립 아이디어는 소프트웨어만으로 수직동기화와 티어링 문제 해결 가능성을 열어주기 때문에 여전히 매력적인 아이디어다.
스트립 단위로 렌더링을 하게 되면 절전 모드시에는 인터레이스도 활용이 가능할 것이다.

1080i vs 1080p? 인터레이스드와 프로그레시브 방식이란?
+.
바로 전 글의 링크에도 나왔지만 게임보이에서 하드웨어 제약과 단일 스캔라인의 문제로 2개의 스캔라인을 사용한 경우도... [GameBoy emulation in Javascript: GPU Timings, Crab, Nitty Gritty Gameboy Cycle Timing]

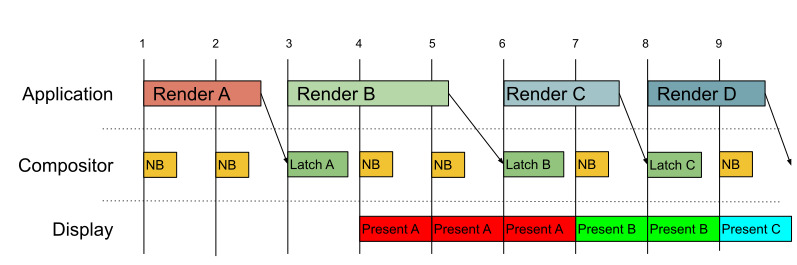
컴포지터
컴포지터란 대체 무엇을 하는 물건일까?
웹에서 transform, opacity와 같은 CSS 속성들은 컴포지터 레이어에서 실행되므로 하드웨어 가속이 된다정도 들어봤을 것이다.
컴포지팅(compositing, 합성)은 개별 소스의 시각적 요소를 단일 이미지로 결합하는 프로세스다.
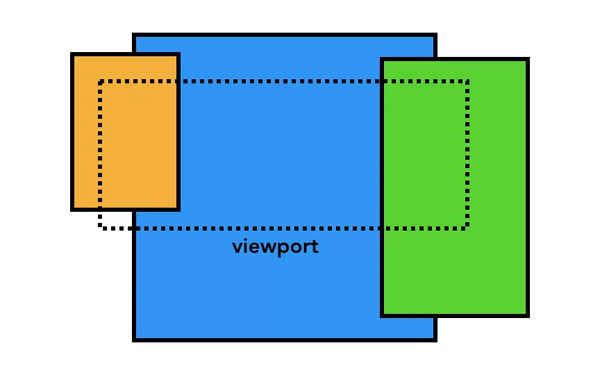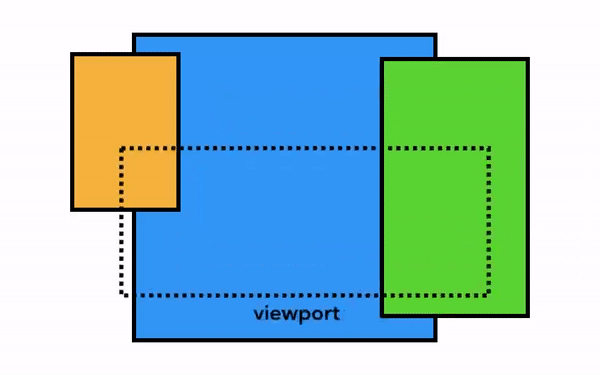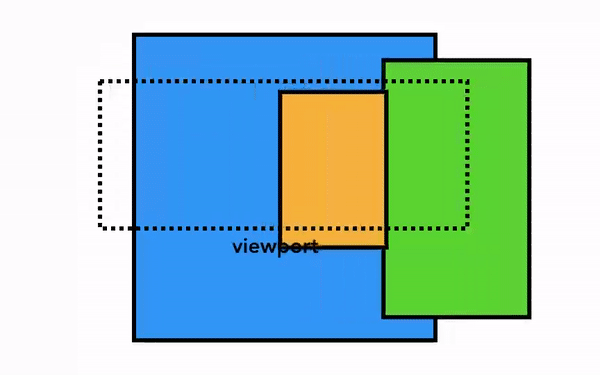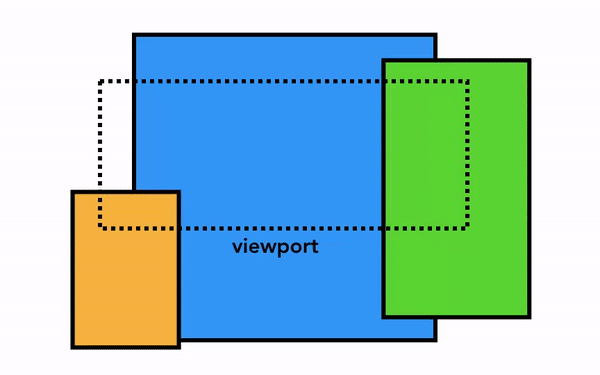
최신 브라우저의 내부 살펴보기 3 - 렌더러 프로세스의 내부 동작
그래픽 기준, 컴포지터는 개별의 레이어를 하나의 레이어로 만들어 보여준다.
그럼 어떠한 기능을 제공할 수 있는가? 윈도우 매니저에 좋은 예시들이 나와있다. [Compositors in Linux]

- 투명도/블러
- 블랜딩
- 확대/축소
- 회전/복제
- 전환 애니메이션
위에서 놓친 유용한 활용 예는 스크롤 기능이 있다.
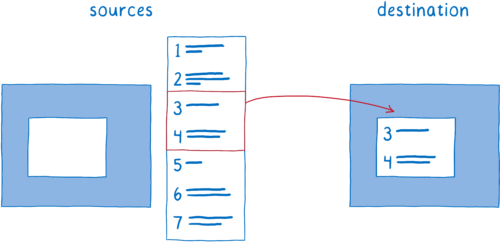
스크롤 물론 컴포지터의 여러 한계 또한 존재한다.
- 지연을 추가
- 레이어가 많아질 때 GPU 대역폭과 메모리 비용
- 텍스트처럼 컴포지터로 다룰 수 없는 요소들
컴포지터로 중간 작업이 늘었기 때문에 회피(바이패스)하는 경우도 생긴다.
대표적인게 비디오 처리이며, KDE에는 윈도우 합성이 의미 없는 전체화면에서 끄는 확장도 있다. [GPU-Based Content Protection with D3D11 Video, What does keying mean ?, Autocomposer]

비디오 처리 아예 GPU를 벗어나 디스플레이 컨트롤러 레벨에서 합성을 할 수도 있다. [Multiplane Overlay (MPO), 안드로이드, Wayland, 윈도우]
옛날 게임기들이 하드웨어 스프라이트(Hardware sprite)를 가졌둣, 하드웨어 오버레이를 사용해 바이패스 함으로서 CPU와 GPU의 자원을 아끼고 각 프레임버퍼는 독립적인 타이밍을 가질 수 있다.
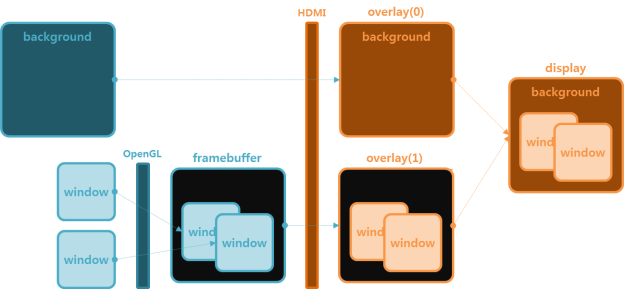
하드웨어 오버레이 디스플레이 컨트롤러에서 컴포지팅을 수행한다니 뭔가 어색한가?
게이밍 모니터에서 조준점 기능을 오버레이로 제공하는걸 본적이 있다면 이상하지 않다.
보통 모니터들도 마우스 커서를 하드웨어 오버레이를 이용해 사용하고 있을 것이다.
하드웨어 오버레이는 2~4개정도로 제약되고 쉐이더가 없기에 변환등을 사용할 수 없는 제약이 존재한다.
안드로이드는 상태 표시줄, 시스템 표시줄, 앱, 배경화면으로 나누어 하드웨어 오버레이를 사용하고,
윈도우의 경우 프로그램에서 자동적으로 하드웨어 오버레이를 사용하기 위해 휴리스틱을 사용하기도 한다. [For best performance, use DXGI flip model, DXGI DirectFlip]
그래픽 API / 라이브러리
다양한 그래픽 API와 라이브러리가 혼재하며 많은 사람들이 헷갈려한다.
먼저 API.


- 고수준: GPU 구조와 독립적이며, 아래의 Vulkan등과 비교할 때 비교적 고수준이다.
예: OpenGL(임베디드 장치를 위한 OpenGL ES), DirectX11 - 저수준: GPU에 명시적 제어를 할 수 있다.
예: Vulkan, DirectX12, Metal
저수준 제어는 만들기가 어려운대신 잘 만든다면, CPU 사용을 줄이고, 명시적 제어로 인해 일관적인 프레임과 확장성을 유지할 수 있다.
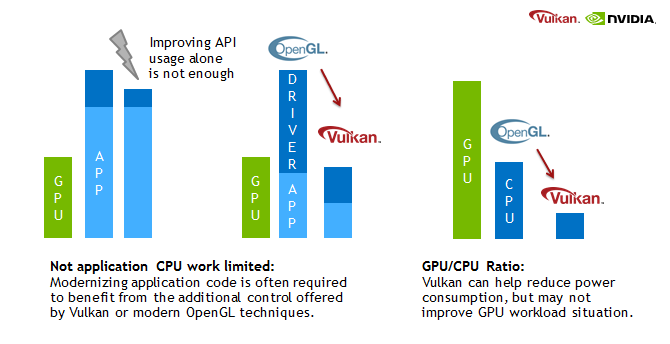
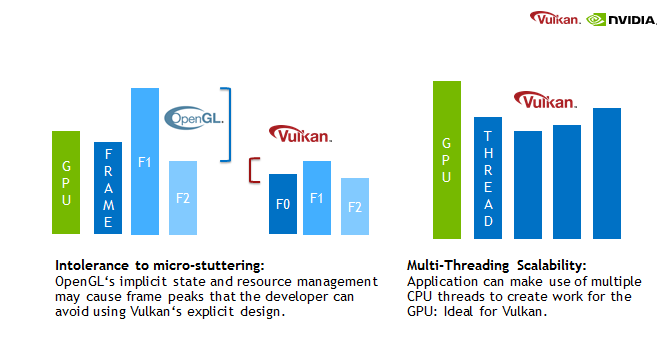
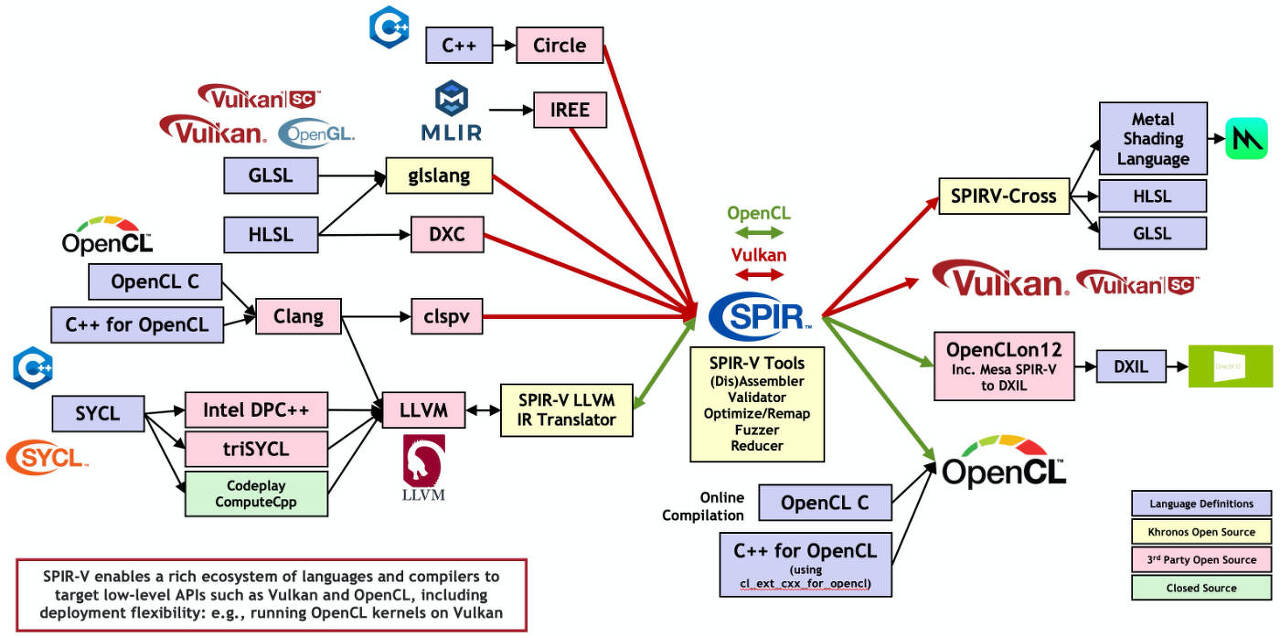
쉐이더 언어에서도 변화가 커서 사람이 읽을 수 있었던 GLSL(OpenGL Shading Language) / HLSL(High-Level Shader Language) 대신 바이트코드인 SPIR-V(Standard Portable Intermediate Representation)가 쓰인다.
플랫폼에 따라 지원하는 그래픽 API가 다양하다는 것을 알 수 있다.
그래서 ANGLE(OpenGL ES 기준)이나 WGPU(Web GPU 기준)와 같은 프로젝트가 만들어졌다. [Point of WebGPU on native]

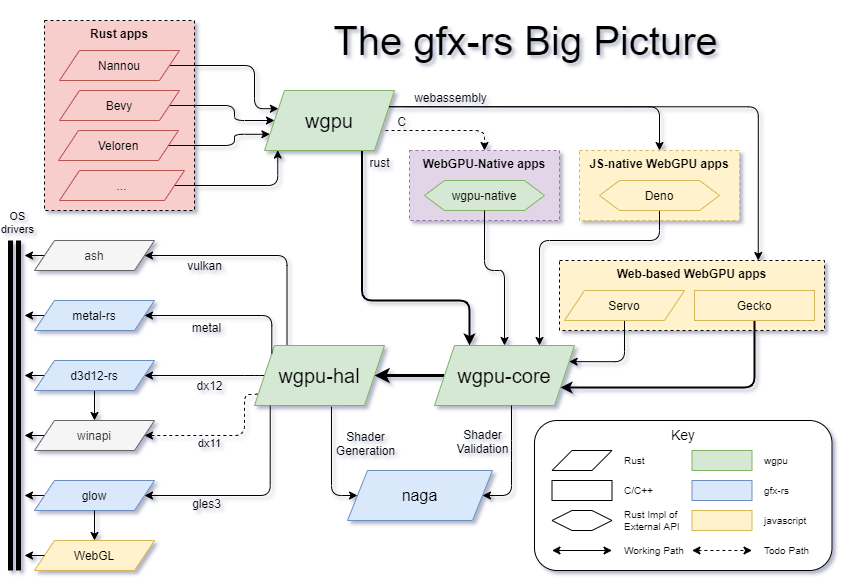
ANGLE: Running OpenGL ES 2.0 Graphics Code on Windows
윈도우 시스템에서도 API가 있다.
대표적인게 EGL(Wayland), GLX(X-Window), WGL(윈도우)이 있으며, 리눅스에서는 DAMBUF를 통한 제로카피, 부분적 손상지원, 적은 버그등 때문에 GLX에서 EGL로 넘어오는 추세라고 한다. [Switching the Linux graphics stack from GLX to EGL, Adventures in graphics APIs, GTK 4.4]
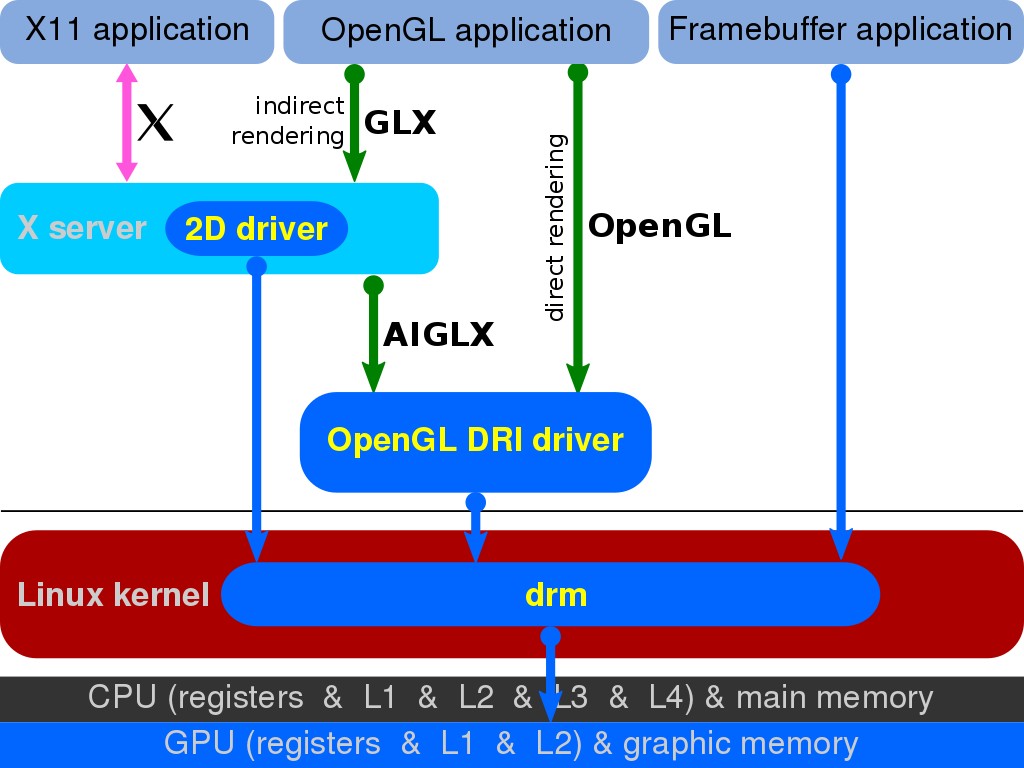
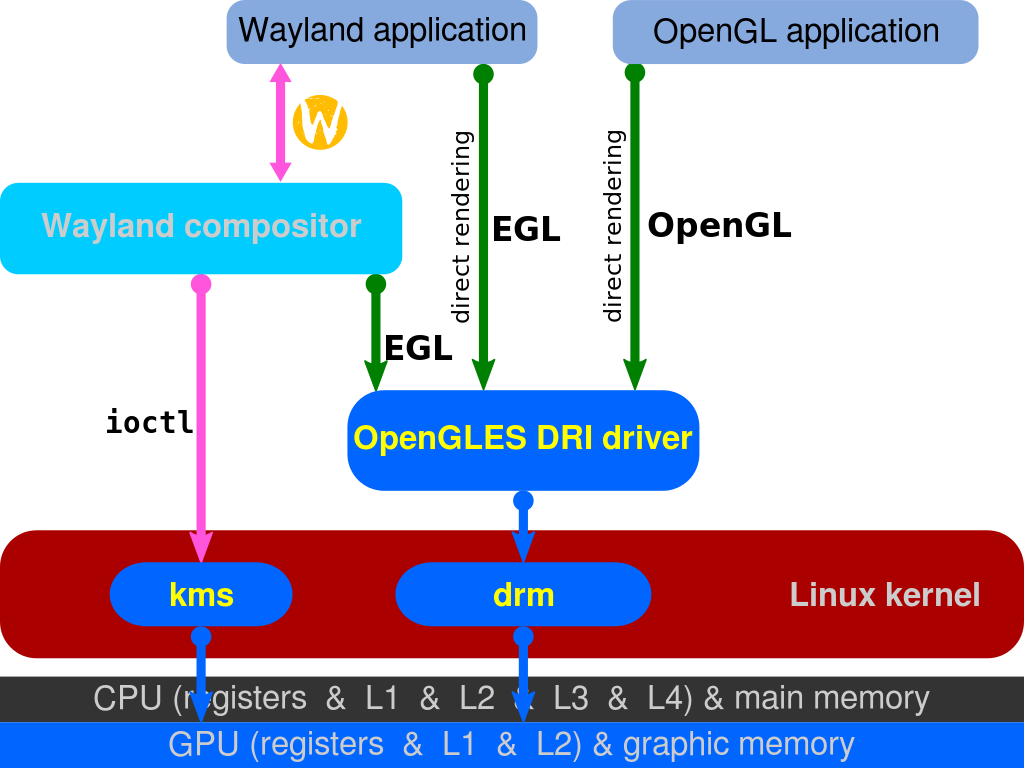
GLX와 EGL 그래픽 라이브러리인 Cairo나 Skia는 위와 같은 그래픽 API나 CPU를 사용해 다양한 기능을 제공하는 라이브러리다. (CPU 기반 로우레벨 라이브러리는 Pixman이 유명)
안티얼라이싱에 대해서도 다룰려 했는데, 위키에 이미 보기좋게 정리가 되어있는 듯 하다.
14. 기타 칩
개요
- A tradeoff between microcontroller, DSP, FPGA and ASIC technologies
- DSP FPGA CPU GPU
- Compare Benefits of CPUs, GPUs, and FPGAs for Different oneAPI Compute Workloads
GPU를 다룬김에 다른 co-processor들도 간략히 다루어보기로 했다.
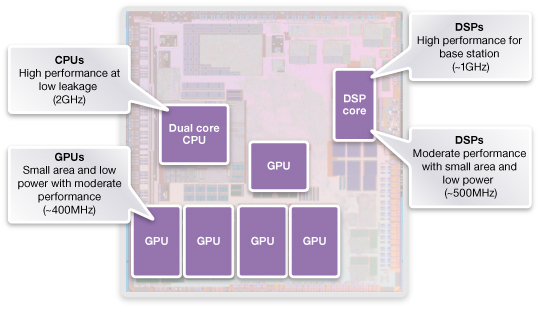
간단한 비교 애플 M1칩을 필두로 점점 중요해지고 있는 추세다.
대상은 DSP, FPGA, ASIC의 일종인 TPU.
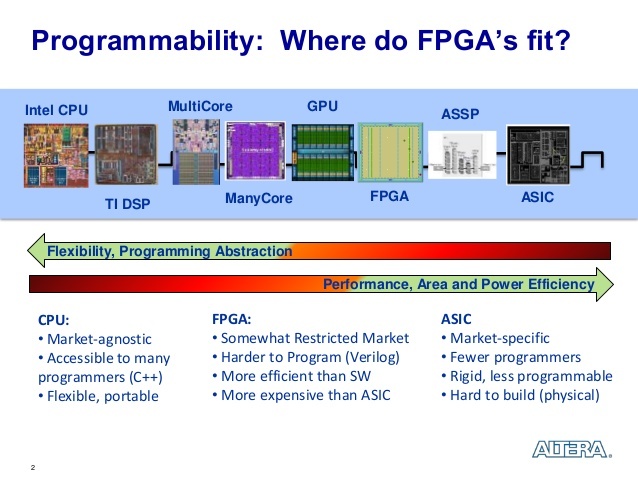
한눈에 보기 본격적으로 들어가기 전에 CPU와 GPU의 구조를 비교해보자.

CPU vs GPU CPU
- 직렬 프로그램(순차코드)에 명령 수준 병렬처리(파이프라인과 슈퍼 스칼라)
- 병렬의 경우 SIMD를 사용
- 정확한 분기예측
- 많은 명령어 (CISC의 경우)
- 오프로드할 필요가 없어 낮은 대기시간
GPU
- 백터 데이터와 처리량에 최적화
- DRAM 대역폭이 높음
- 계산에 중점을 두어 캐시와 제어 요소가 적음
- 개별 스레드의 대기시간과 성능에 중점두지 않음
DSP
- What’s So Special about the Digital Signal Processor?
- What is Digital Signal Processor : Working & Its Applications
DSP(Digital Signal Processor)는 기본적인 신호처리 알고리즘을 내장하고 있다.
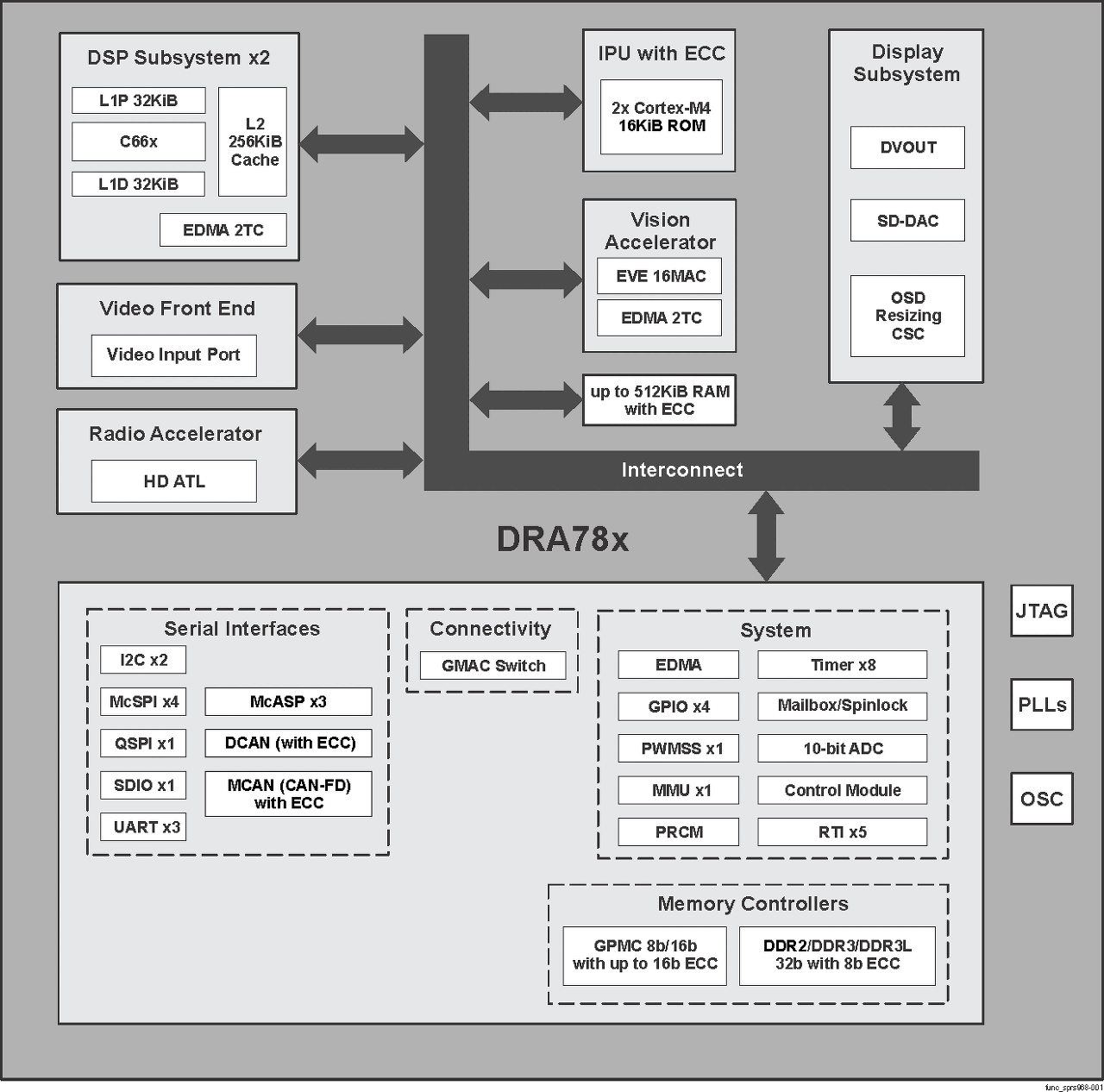
TI의 DRA78x Infotainment Applications Processor (Rev. H), 다양한 기능을 내장함
주목할 점이라면 VLIW 명령어셋을 사용하는 경우가 많다.
따라서 한 클럭당 많은 일을 할 수 있는 편이다. (저지연, 전력)
퀄컴에 따르면 RISC에서 29개의 명령어로 이루어진 고속 푸리에 변환 작업을 1클럭만으로 실행시키는 경우도 있다.

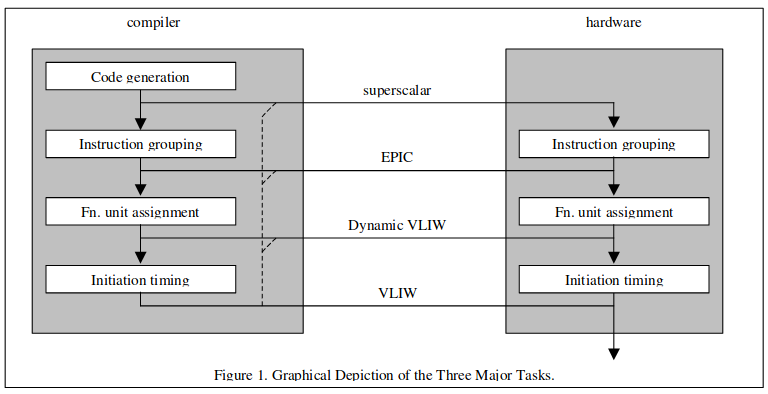
낮은 클럭에서도 높은 성능을 보여줌 말이 나온겸 VLIW에 대해서도 알아보자. [Very-Long Instruction Word (VLIW) Computer Architecture, Advanced Out-of-Order Superscalars and IntroducBon to VLIW]
종속성이 없는 명령어 여러개를 한번에 처리(Execute)하는 명령어 처리기법이다.

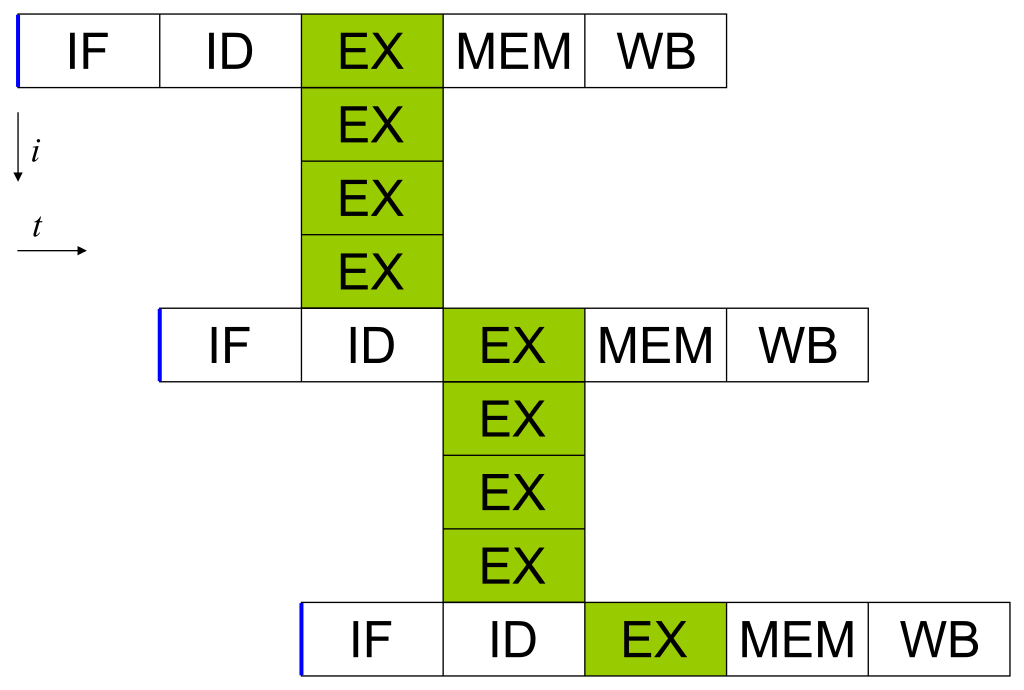
VLIW architecture, VLIW Pipeline
- 장점: 병렬처리가 가능하고, CPU에서 스케쥴링(슈퍼스칼라와 비순차적 실행)이 없어 회로가 간단해짐
- 단점: 의존성이 강한 연속적인 명령어(병렬불가)는 비효율적, 컴파일러의 제작 난이도가 높음, 분기예측과 캐시미스에 취약함
한마디로 말해서 CPU에서 하던 스케쥴링 작업을 컴파일 타임에 해버리고 하드웨어에서는 그냥 실행만 하는 구조로 효율적 클럭사용, 작은 유닛 크기를 얻겠다는 전략인데..
컴파일 타임에서 메모리 접근을 결정적으로 만들기가 상당히 어렵다.
그러나 DSP의 경우 데이터 처리자체가 스트리밍에 가깝기에 캐시미스가 중요하지 않고 신호처리는 병렬처리를 요구하므로 VLIW와 잘 맞아떨어졌다.
또한 캐시관련 특수성 때문에 폰노이만이 아닌, 하버드 아키텍처를 사용하는 여러모로 특이한 케이스다.
VLIW 설명겸 인텔과 HP가 심취했다 타격받았던 불운의 설계, EPIC도 알아보자. [EPIC Architecture (Explicitly Parallel Instruction Computing), The IA-64 architecture and Itanium processors Explicitly Parallel Instruction Computing, Historical background for EPIC instruction set architectures, IA-64, Understanding EPIC Architectures and Implementations, IA-64 Architecture Overview]
대체 무엇이 매력적이었던걸까?
간단히 말하면 슈퍼스칼라와 비순차적 실행을 VLIW에 접목해 보다 효율적이고 범용적으로 만들었다.
우선 놀고있는 CPU를 컴파일러단에서 병렬적으로 만들어 최대한 일하게 만들기 위한게 목적.
지금은 비슷한 목적으로 하이퍼 스레드가 사용되나 설계의 관점으로만 보면 컴파일러만로 장기적인 성능개선이 가능한 EPIC이 좋아보이기는 한다.
컴파일러를 활용 먼저 전반적인 명령어 구조는 VLIW와 비슷하다.
그러나 전부 다 컴파일러가 감당해야 해서 비결정적 메모리 접근등의 문제를 해결하기 어려웠던 VLIW와 달리 작업그룹 종속성에 대한 표현을 위주로 하도록 만들어져 슈퍼스칼라와 가까워진 방향으로 설계되었다.
Dynamic VLIW는 트랜스메타의 크루소 방식으로 알려져 있다.


명령어와 작업그룹 종속성 병렬을 활용하므로, 분기를 줄일 수 있었다.


분기를 효과적으로 줄임 제어와 데이터에 대한 투기적 실행은 메모리 베리어 문제를 개선해 비순차적인 실행이 가능하도록 만들었다.
이로 인해 메모리 접속 지연, 캐싱, 스케쥴링의 유연성등에 도움을 주었다.




제어와 데이터 ALAT(Advancded Load Address Table)이 특이한데, 다음과 같이 이루어진다.


- 로드한 메모리(ld.a)의 레지스터(r1)를 엔트리에 추가
- 추가를 시도시 충돌이 나면 엔트리에서 제거
- 추후 체크(chk.a)할 때 엔트리에 존재하면 성공, 없으면 실패를 의미하므로 분기함
RRB(Register Rotation Base)는 루프 언롤링 대신 하위집합에 대한 엑세스 이름을 바꾸어 준다.
GR(General Register), FP(Floating Point Resisters)가 대표적인 예였다.
예를 들어 RRB의 값이 10일때, GR[35] 참조는 GR[45]의 값을 사용한다.


파이프라이닝 이렇게 이론적인 아키텍처 설명만 들어보면 혹할만도 하다싶다. ㅋㅋㅋ
이와 반대로 하드웨어 레벨 JIT을 최대한 활용해버리는 방식이 블로그에서 몇번 언급했었던 The Reduceon이라는 함수형 아키텍쳐다. [Reduceron, an efficient processor for functional programs, The Reduceron: Widening the von Neumann Bottleneck for Graph Reduction Using an FPGA]
91.5MHz FPGA에서 2.8GHz Pentium급 성능을 냈다나.
이쪽에 관심이 많다면 HVM이라는 함수형 런타임도 살펴보라.
FPGA
- Understanding an FPGA Architecture
- FPGA Architecture Basics
- The Ultimate Guide to FPGA Architecture
- A Scientist’s Guide to FPGAs
FPGA는 프로그래밍 가능한 반도체다.
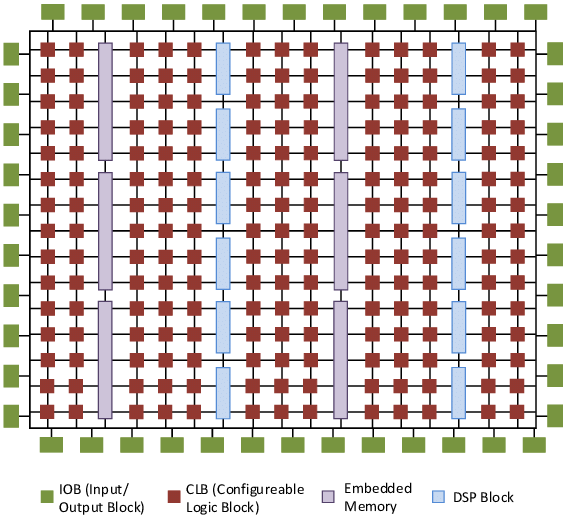

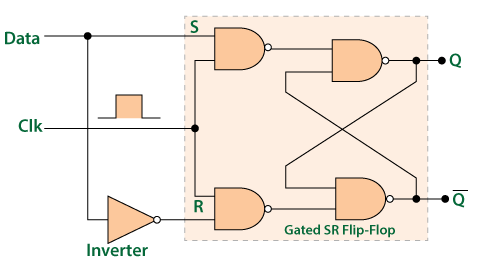
자일링스와 알테라 FPGA 아키텍처 FPGA는 Switch의 연결에 따라 라우팅되며, 핵심인 CLB를 자세히 들여다보면 LUT(Lookup Table), 플립플롭(Flip Floop), 멀티플렉서(Multiplexer)로 이루어졌다. [Performance Analysis of Nanoelectromechanical Relay-Based Field-Programmable Gate Arrays]

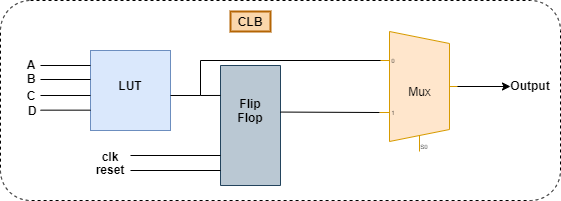
스위치와 CLB 구조 - LUT: 논리기능
- Flip Floop: 순차논리
- Mux: 조합논리와 순차논리 중 데이터 출력을 선택
멀티플렉서는 알다시피 선택하는 회로다.
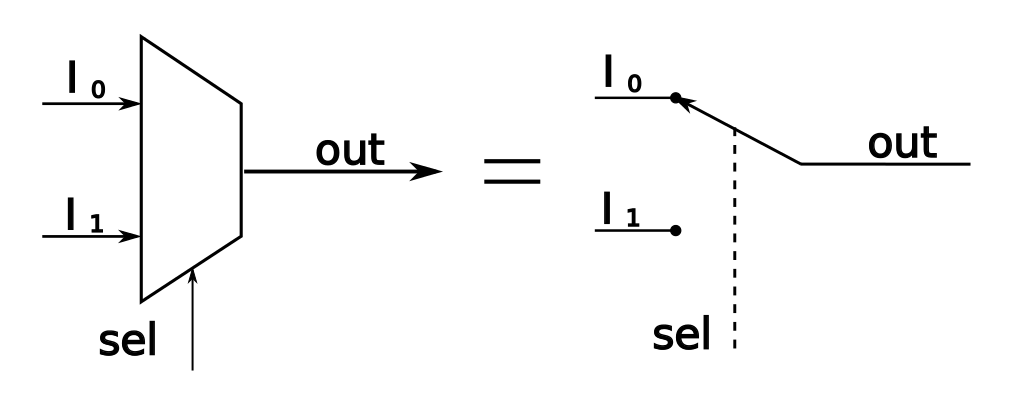
멀티플렉서 LUT는 멀티플렉서와 S램을 사용해 논리 연산을 구현한다.
예를 들어 3비트 LUT는 8비트 SRAM과 트리형태의 7개 멀티플렉서로 구성되어 3비트에서 가능한 모든 논리연산을 수행할 수 있다.



LUT 구조와 동작 플립플롭으로는 D플립플롭을 사용하며, 회로와 진리표는 다음과 같다. [D Flip Flop]
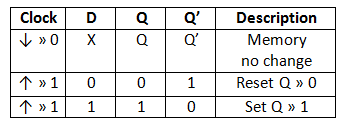
다음 활성 클럭마다 값이 바뀜 최신 FPGA는 연산속도를 올리고 라우팅을 줄이기 위해 6입력 LUT와 산술 연산을 위한 Carry chain를 CLB에 통합하고, 곱셈 계산을 위한 DSP등을 사용해 LUT를 보완하고 있다.
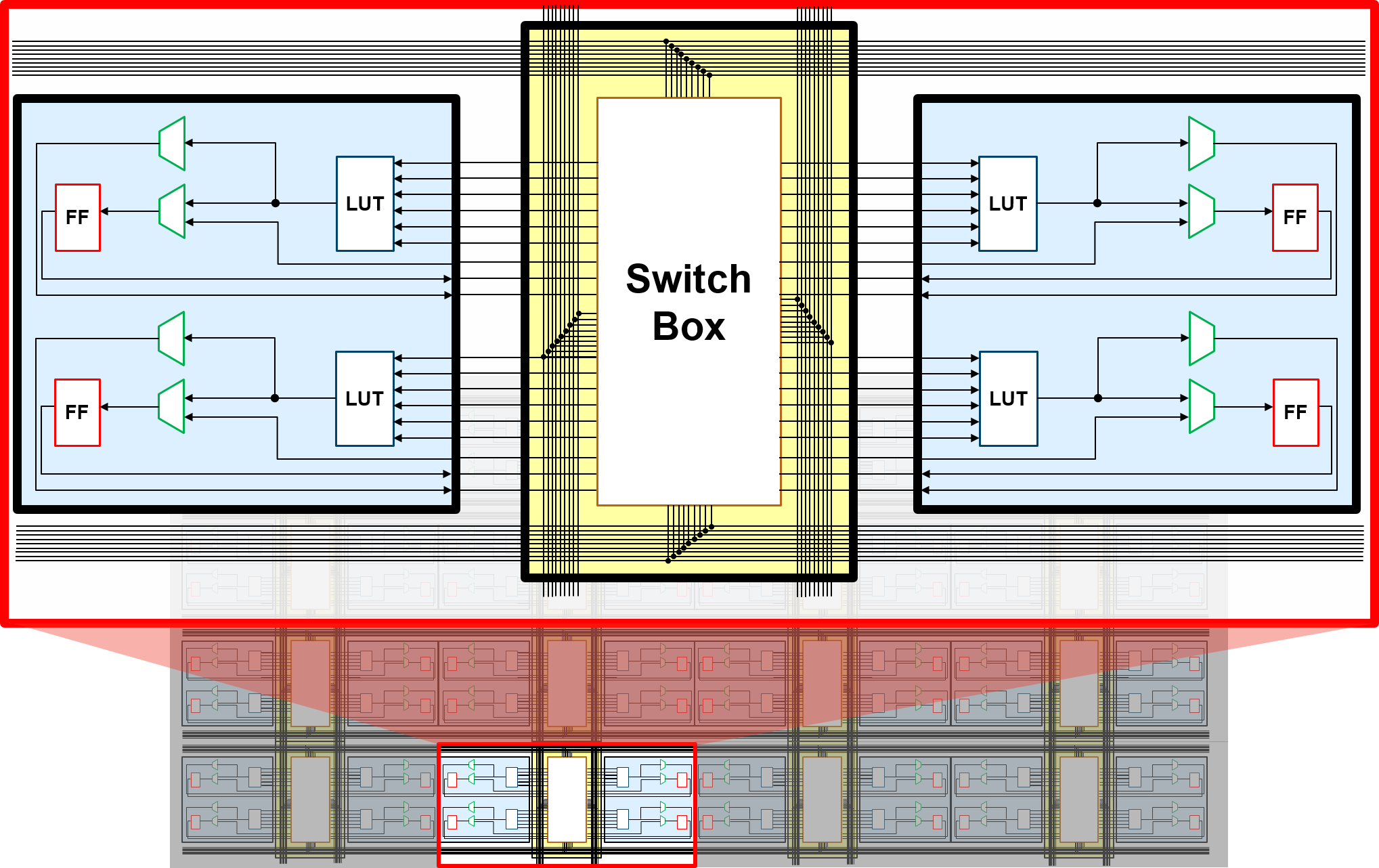

CLB와 6입력 LUT 어째서 설정이 가능한지와 작동방식은 대략적으로 이해했을것이다.
그럼 계산방식을 비교해 보자.
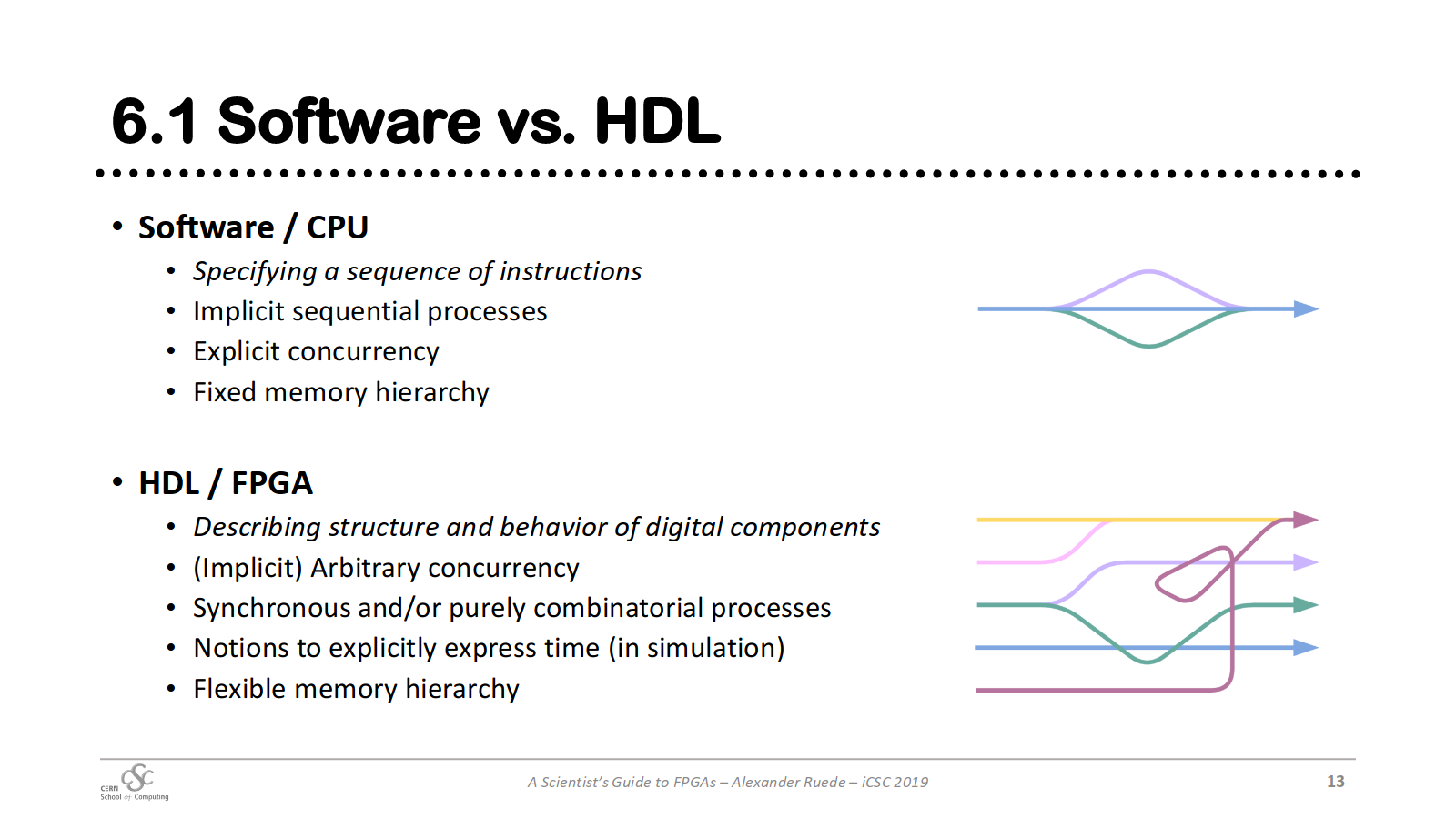
- 동기적이고 조합을 이용함
- 임의적 동시성
- 명시적으로 시간을 표현
- 메모리 계층이 유연
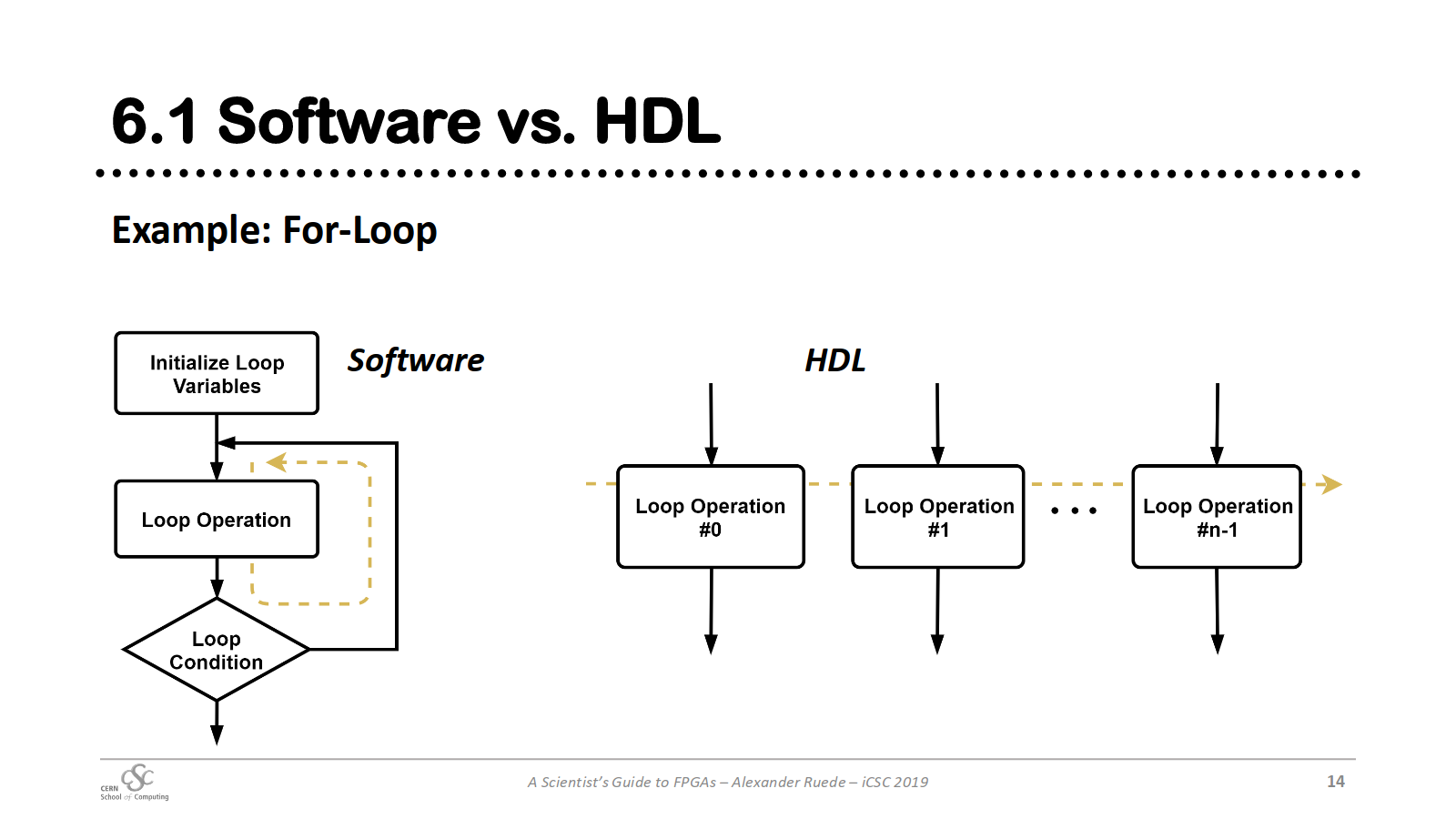
작업 파이프라인으로 보면 다음과 같다.
각 작업이 연결되어 매 클럭마다 실행된다.

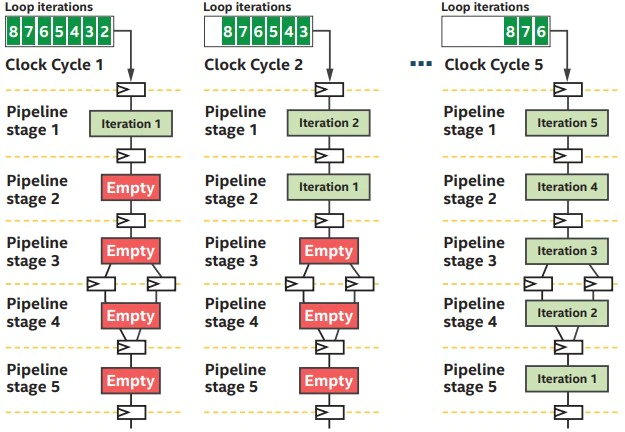
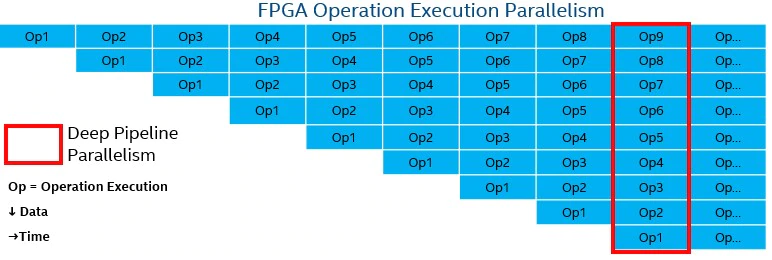
FPGA 파이프라인 소프트웨어로 하드웨어를 설정해 작업 파이프라인이 일치하기 때문에 성능과 전성비 모두 좋다.
그러나 가격이 비싸고, 무엇보다 회로 설계 난이도가 매우 높다는 트레이드 오프가 있다.
TPU
- What makes TPUs fine-tuned for deep learning?
- An in-depth look at Google’s first Tensor Processing Unit (TPU)
- Cloud TPU - System Architecture
- Evolution of TPUs and GPUs in Deep Learning Applications
TPU(Tensor Processing Unit)는 대표적인 ASIC(주문형 반도체, Application-Specific Integrated Circuit)의 예이다.
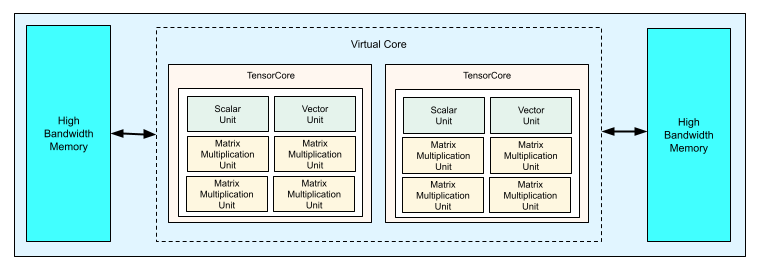
TPU v4 아키텍처 대체 어떠한 이유로 TPU를 만들었는가에 대해 알아보자.
다음은 신경망의 작동방식이다. (GIF 크기가 크므로 새탭에서 열어 확인해보세요)
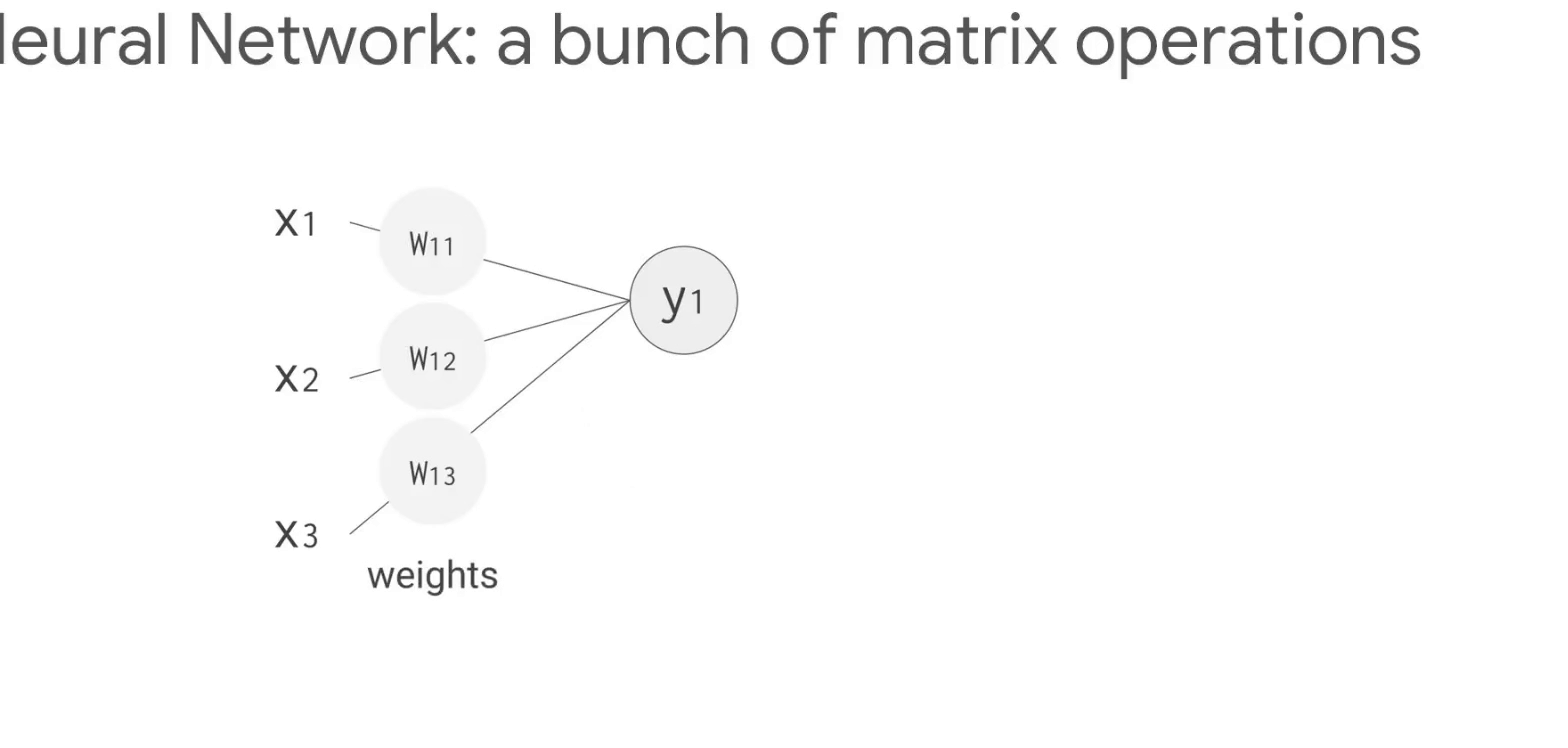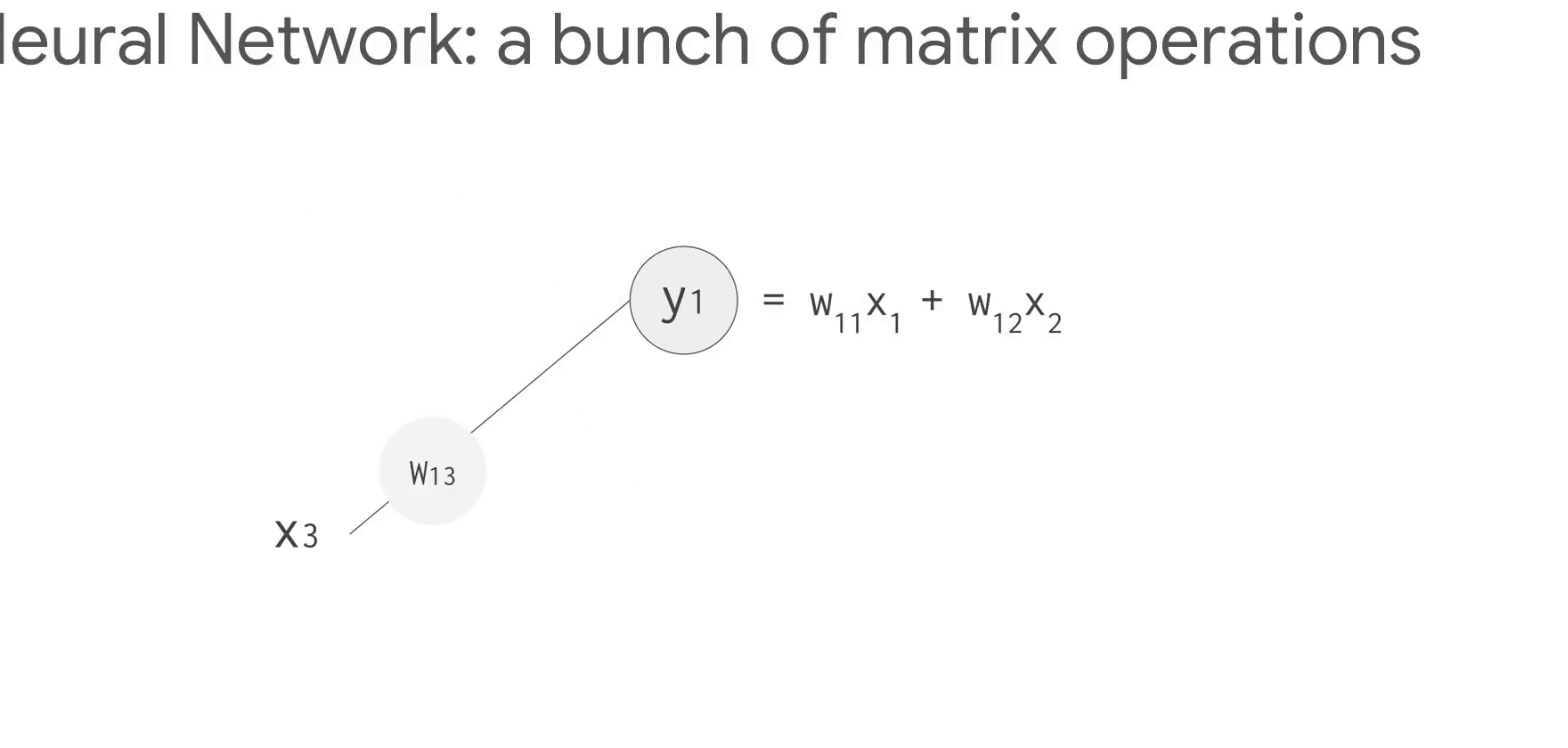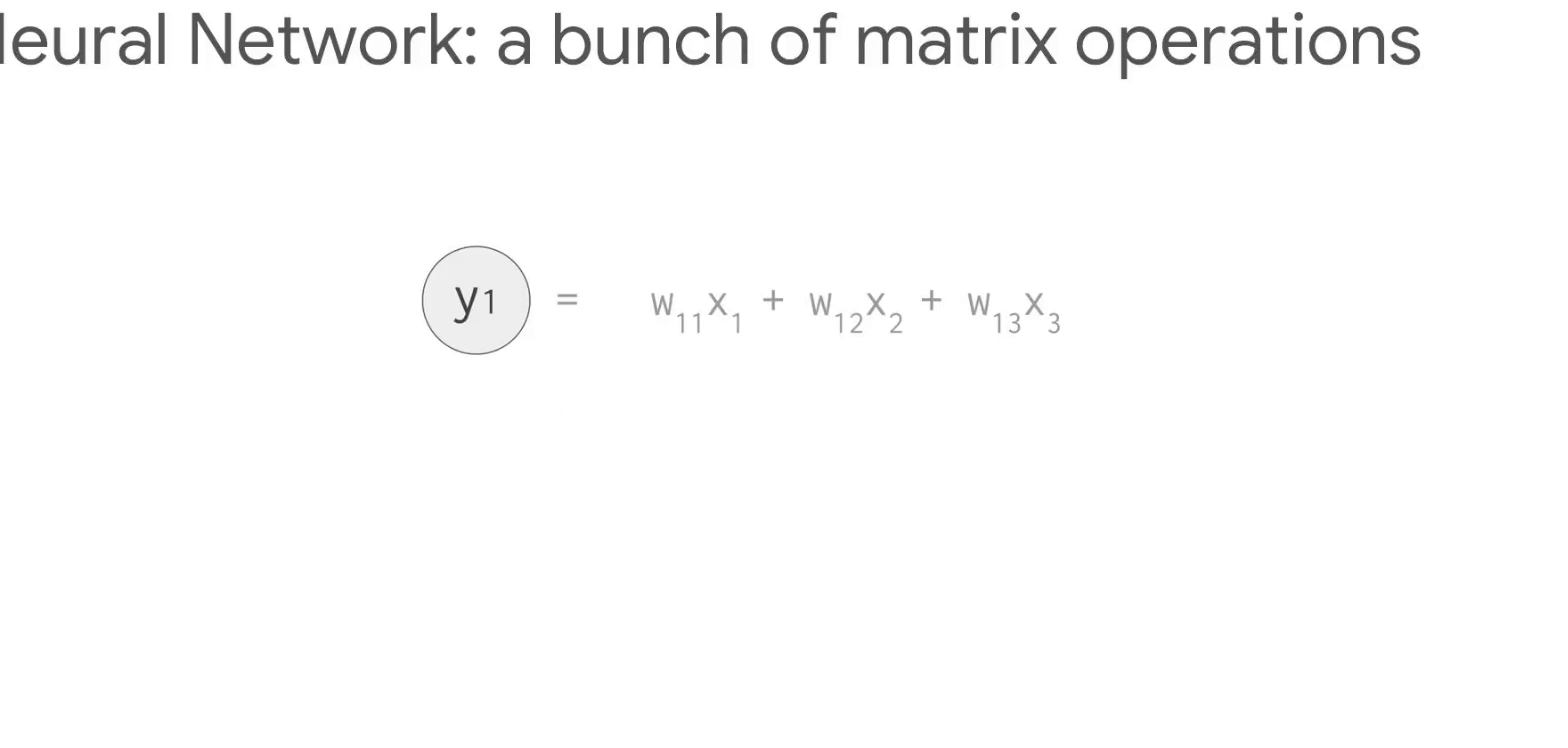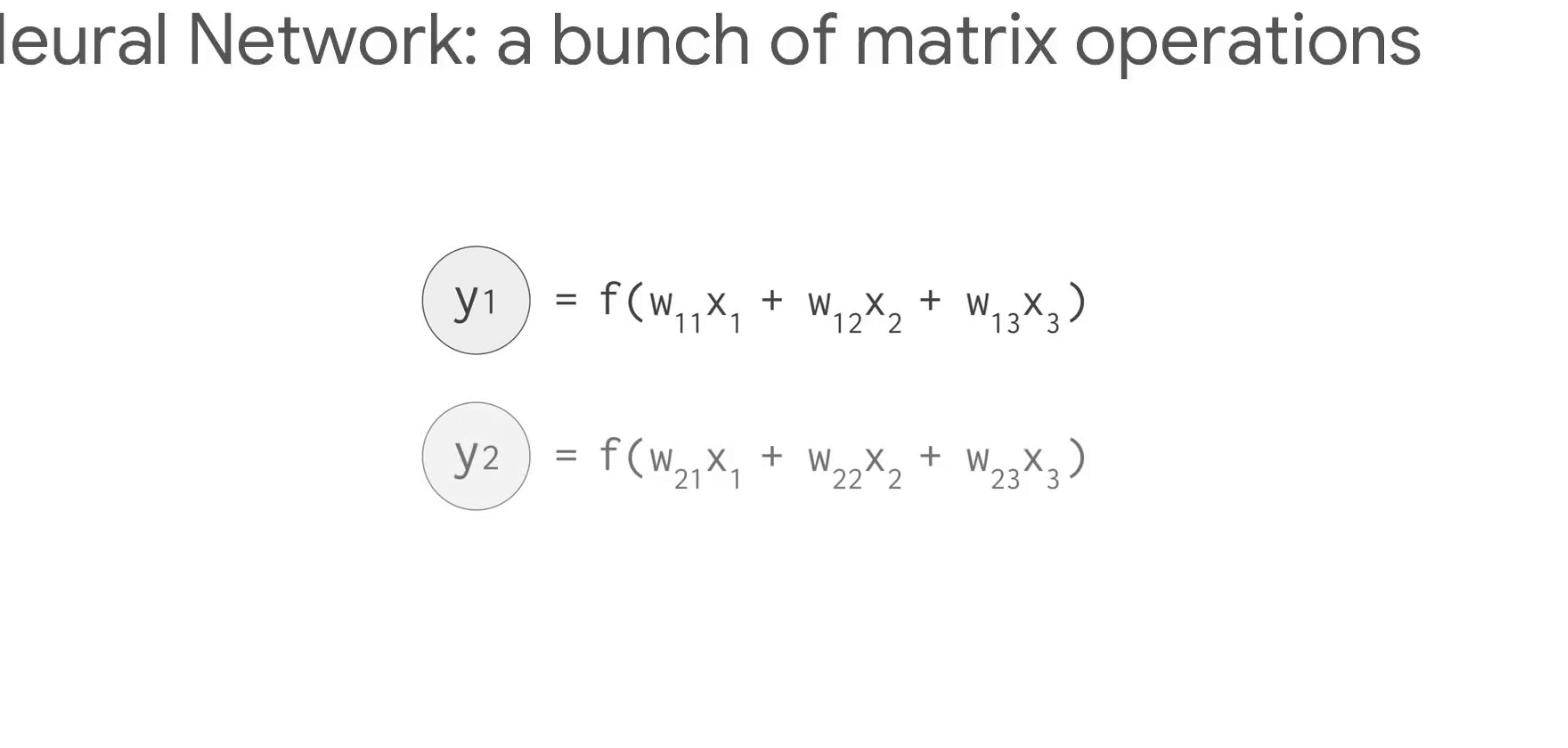
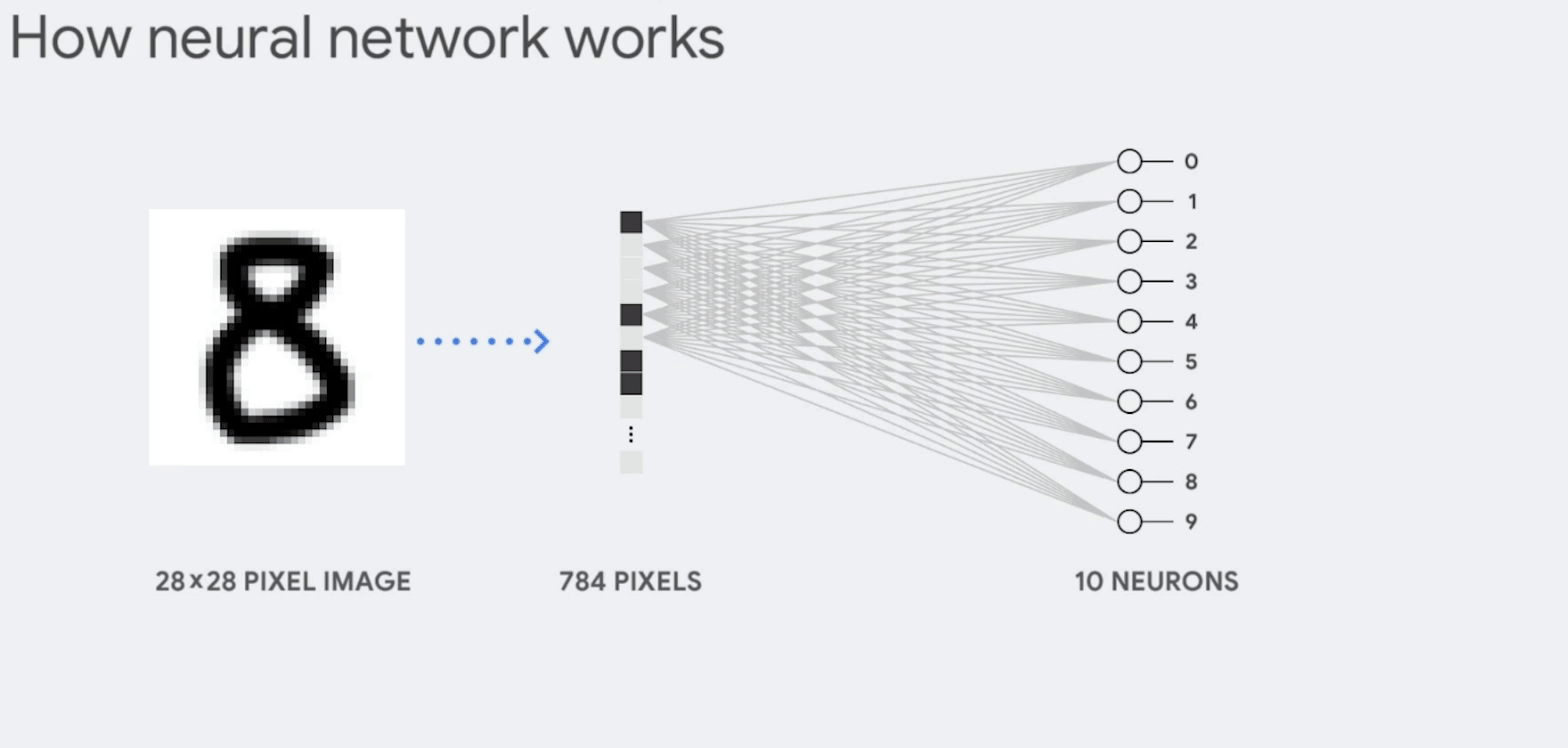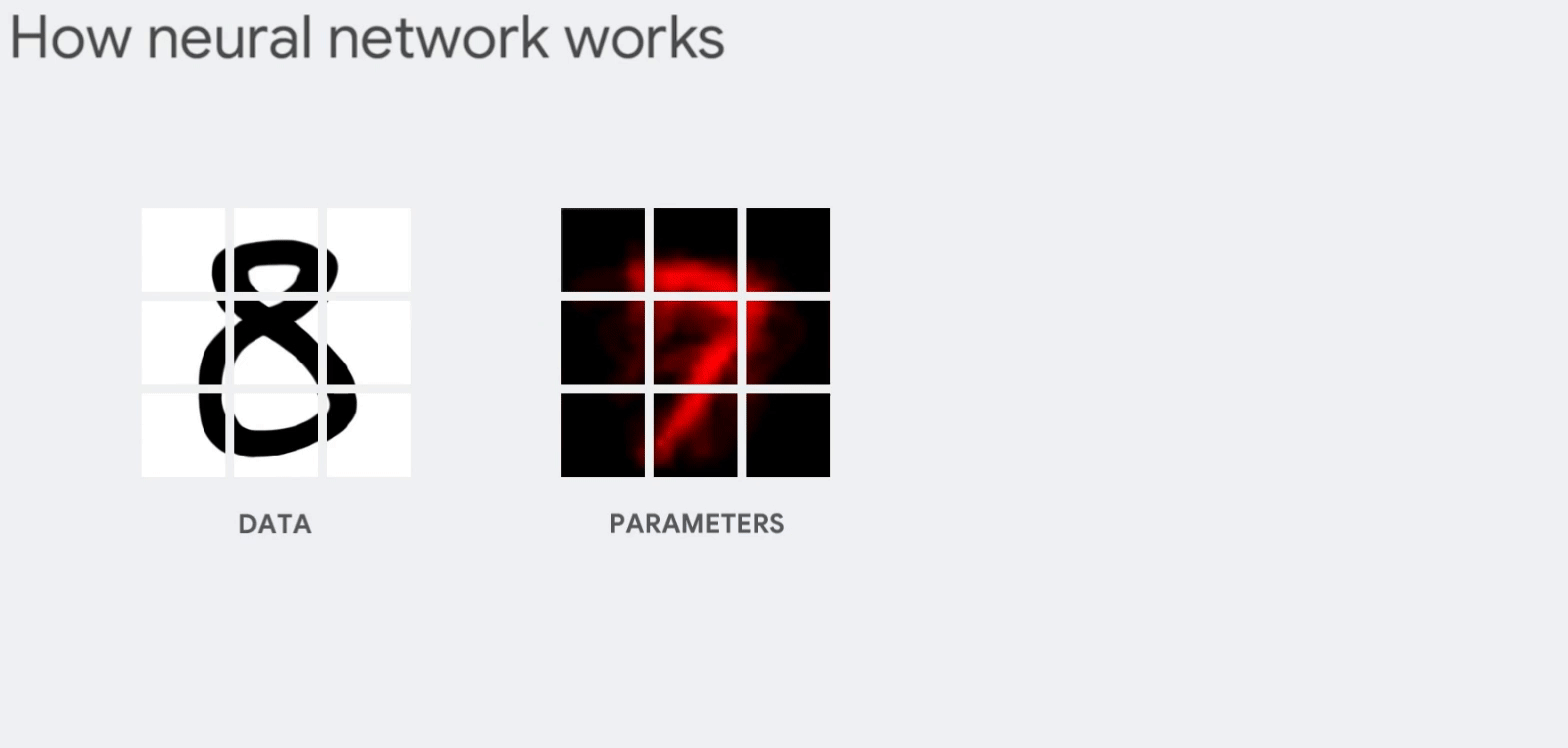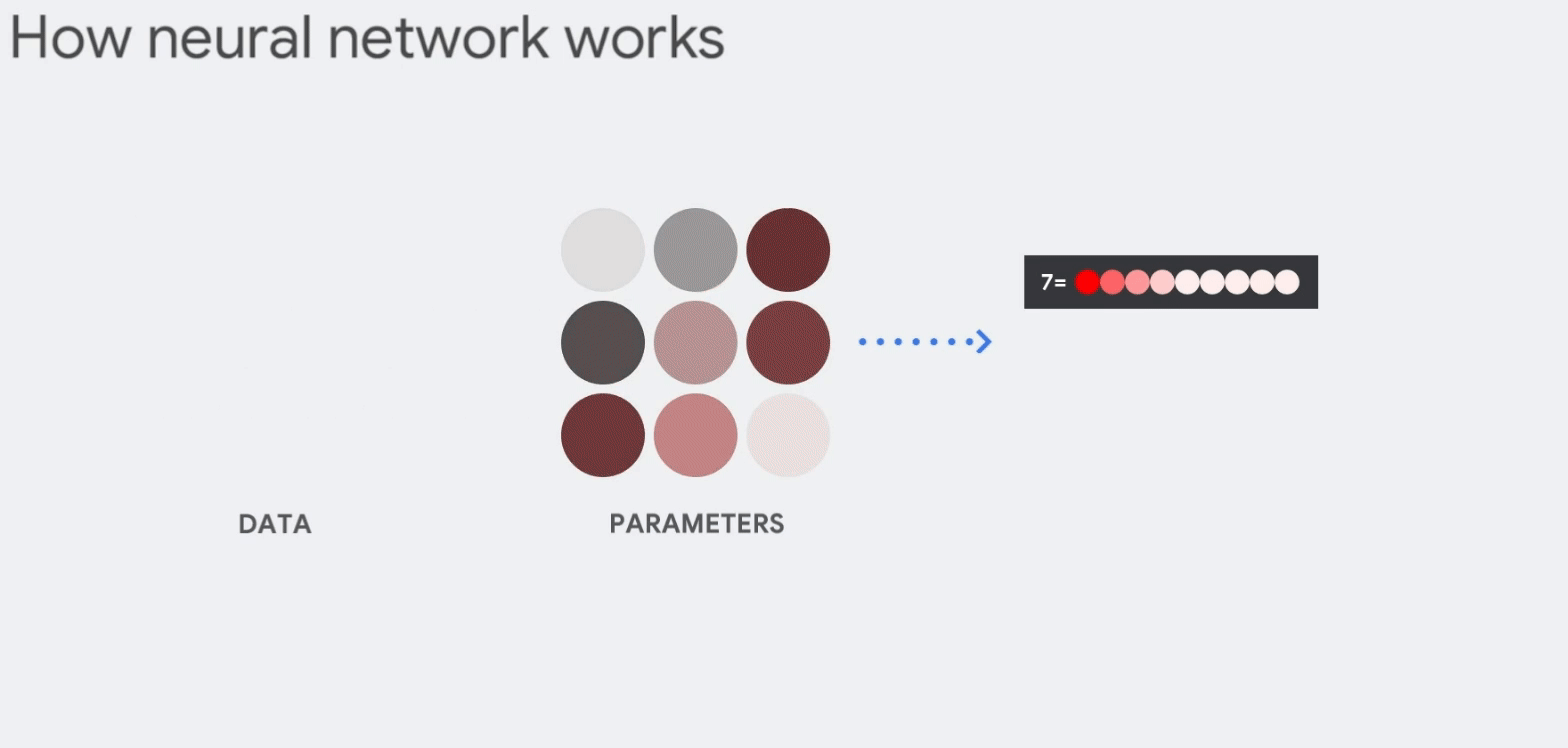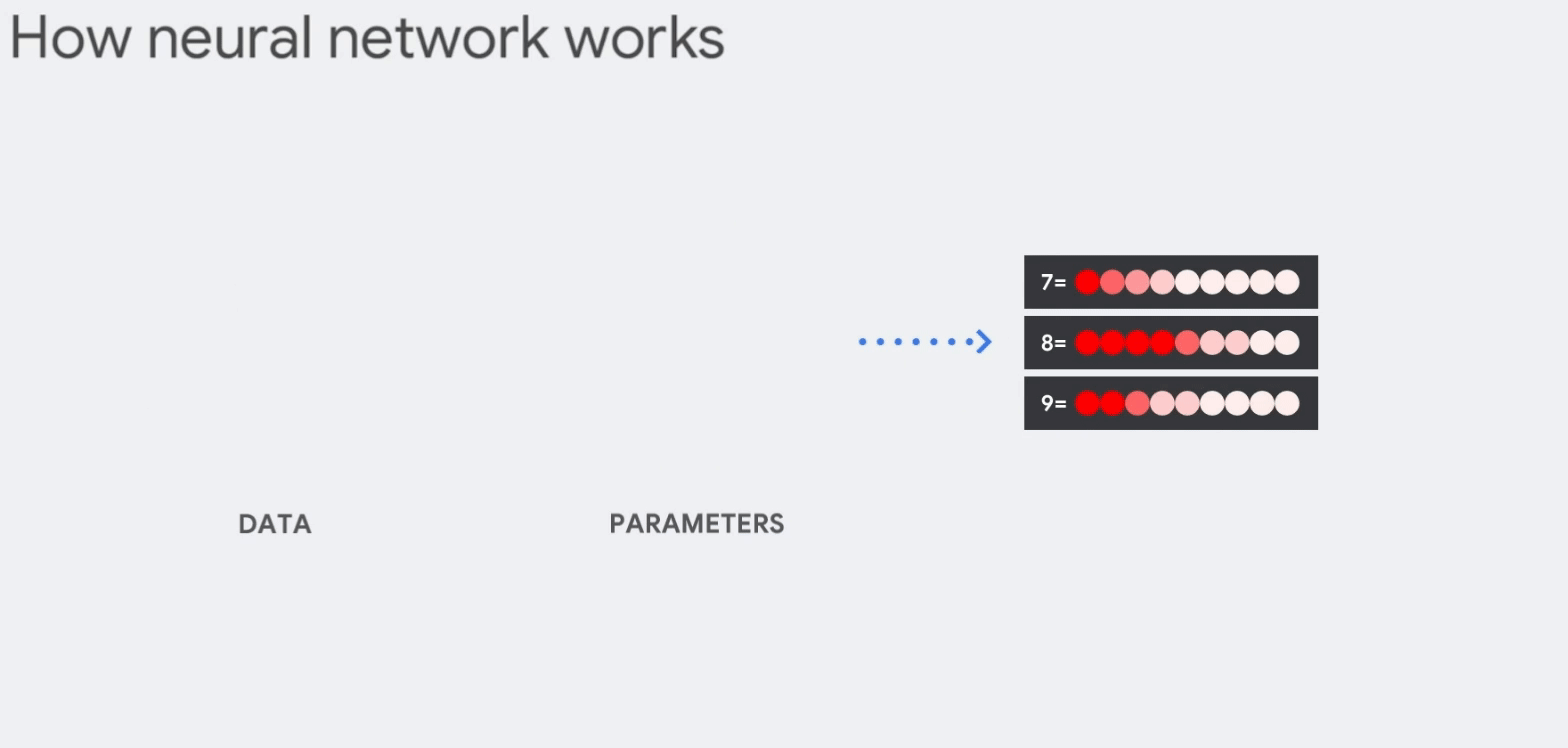
- 784개(28x28)의 벡터로 변환 [입력데이터]
- 숫자 "8"을 인식하는 뉴런은 입력값 매개변수 값(가중치, 빨간선)을 곱함
(매개변수는 이미지와 "8" 모양의 유사성을 알려주는 특징을 데이터에서 추출하는 필터 역할) - 곱한 값은 신호강도를 뜻하며, 모두 더하여 가장 높은 결과가 정답일 가능성이 높음
따라서 많은 행렬의 곱셈과 덧셈이 발생한다.
계산을 어떻게 처리하는가 보자.
TPU의 MXU(Matrix Multiplication Unit)이 바로 곱셈과 가산기의 배열인데, 128x128 곱셉/가산기다.


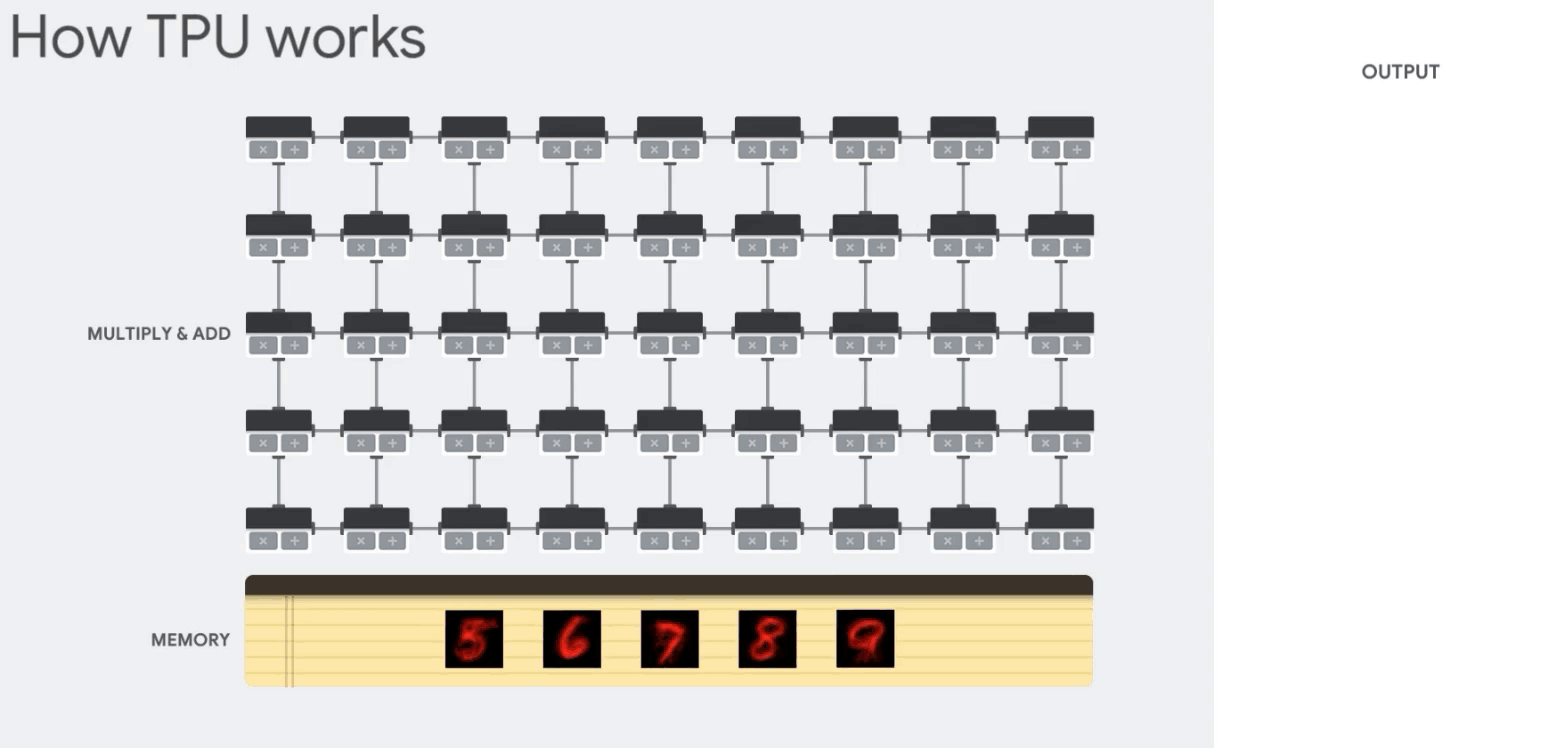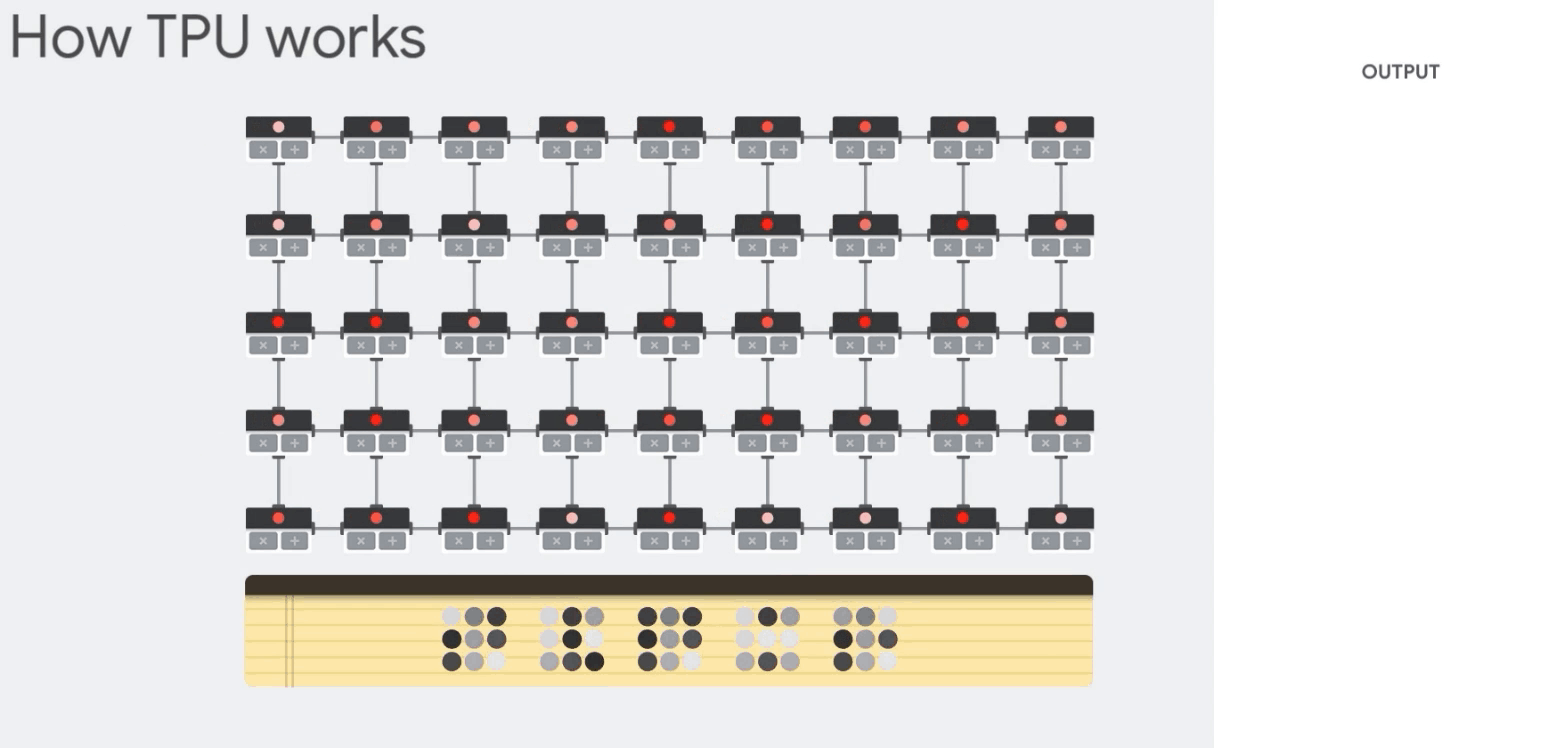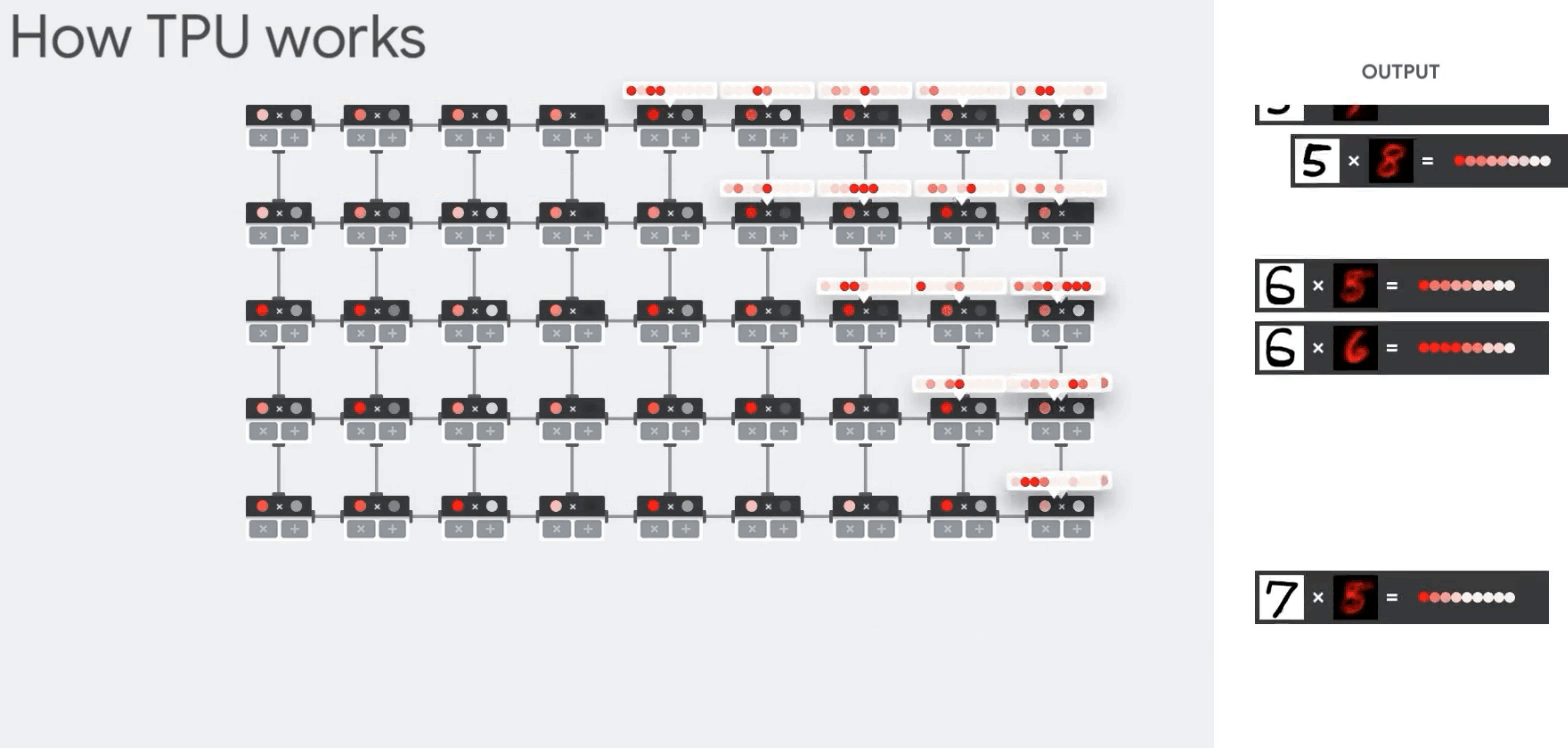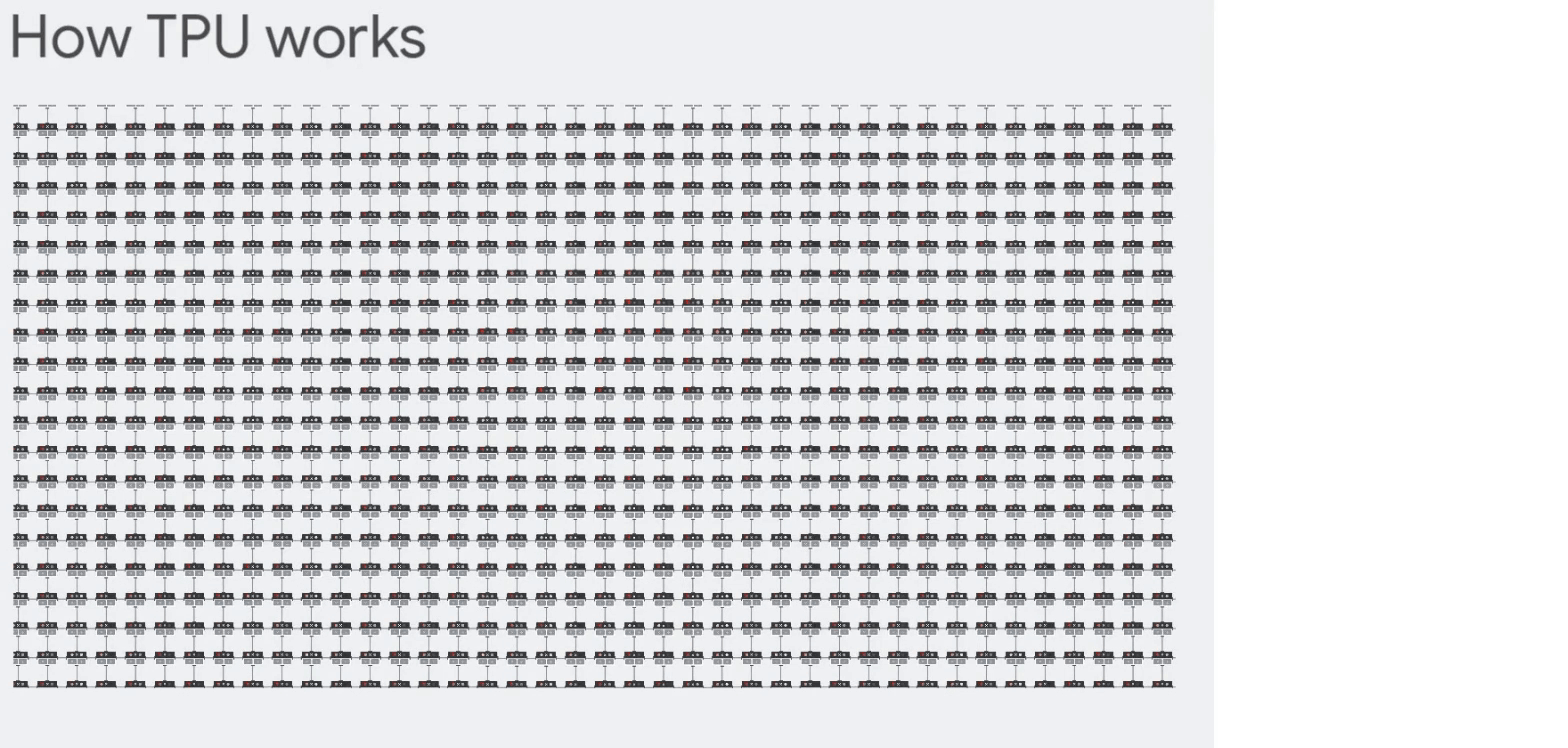
CPU, GPU, TPU - CPU: 순서대로 처리하며, 계산결과는 매번 내부 메모리(레지스터, 캐시)에 저장
- GPU: 대규모로 병렬연산을 수행함, 그러나 역시 중간 계산 결과를 읽고 저장하기 위해 내부 메모리에 접근해야함
- TPU: 모든 계산 단계를 알고 있으므로, 수천개의 곱셈/가산기를 배치하고 서로 직접 연결해 Systolic Array구조를 만들어 중간단계에는 메모리에 접근할 필요가 없음
아키텍쳐상 두개의 장점이 있다는 것을 알 수 있다.
SIMD나 GPU의 벡터처리에서 확장해 행렬단위를 단일 클럭에서 처리할 수 있으며, Systolic Array 구조로 중간에 메모리에 접근하지 않는 다는 것.
계산 단위 

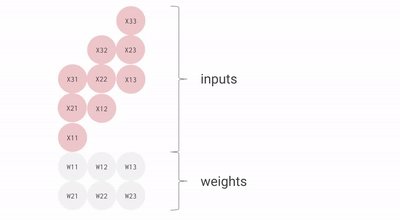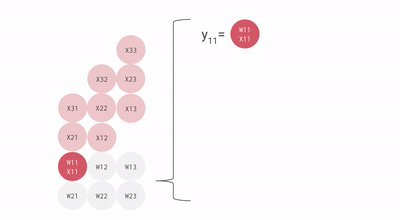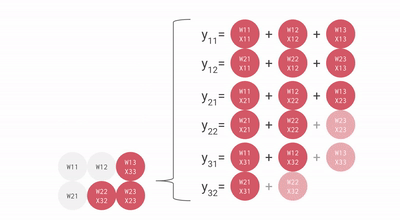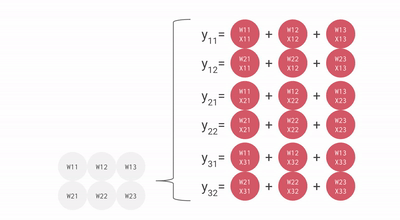
계산 과정 TPU는 커다란 부동소수점 연산(99번째 백분위수), 캐시, 분기예측, 비순차적 실행, 멀티프로세싱, 투기적 프리페칭, 주소병합, 멀티스레딩과 컨텍스트 전환등 범용 연산이 전혀 필요없는 결정론적 설계로 유닛을 효율적으로 쓸 수 있었다.
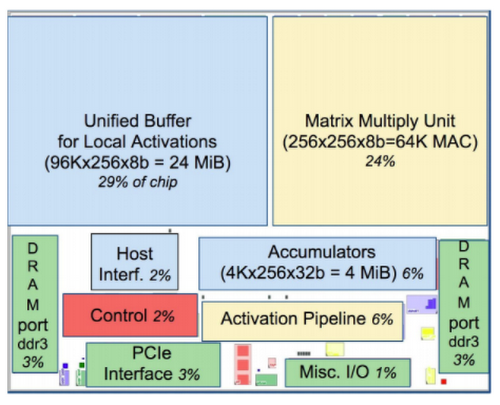
TPU v1 - 2%에 불과한 컨트롤 유닛 최근에는 TelaMalloc이라고 할당을 효율적으로 하는 방식도 나와 할당을 효율적으로 해준다. [구글, 기계 학습 가속 위한 메모리 할당 기법 개발...최대 2배 속도 향상]
텔라말록 이 뿐만이 아니다.
모든 곱셈은 bfloat16을 사용하고, 덧셈은 Float32를 사용한다. [BFloat16: The secret to high performance on Cloud TPUs]

bfloat16 - 16bit이므로 32bit에 비해 적은 메모리를 사용하고 칩 크기도 줄일 수 있음
- 신경망은 지수부(Exponent)가 가수부(Mantissa)보다 중요하므로 비율을 조정
- 조정한 지수부의 크기는 Float32와 같으므로 Float32로의 변환이 쉬움
비슷하게 부동소수점을 계산에 적합하게 만들자는 시도로 Posits가 있다. [Posits, AI의 수학을 향상시키는 새로운 종류의 숫자]
이러한 효율적 설계로 전성비가 매우 좋다.
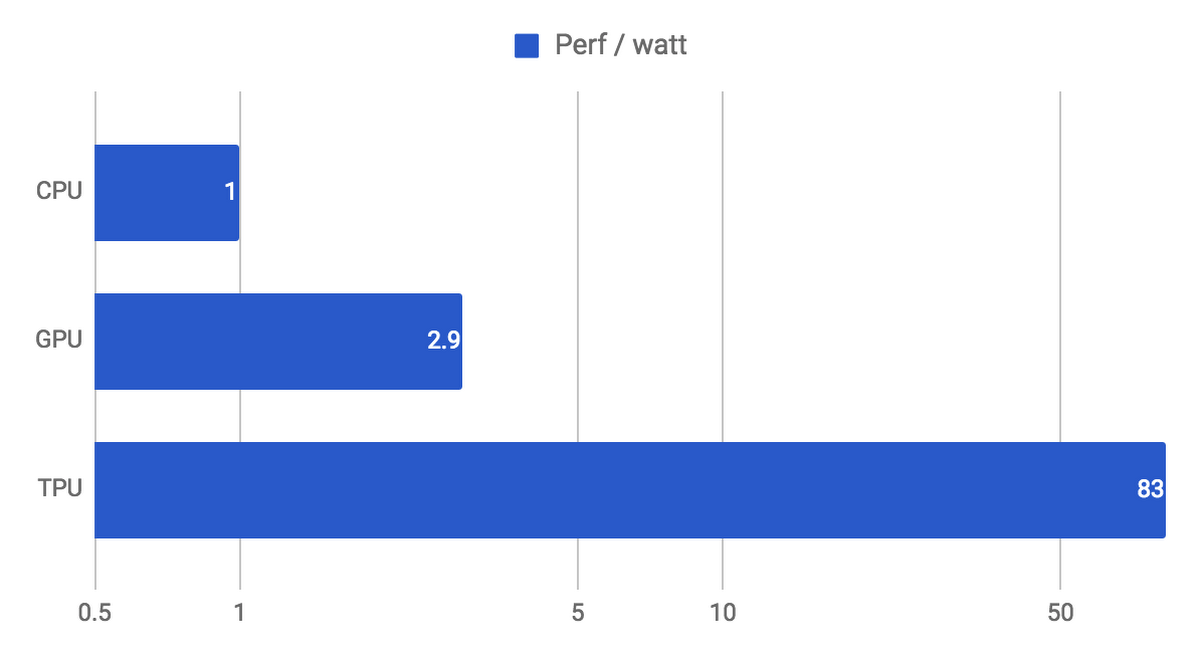
CPU보다 83배, GPU보다 29배 마지막으로 TPU는 클러스터링인 TPU Pods을 구성해 부하를 분산할 수 있다.
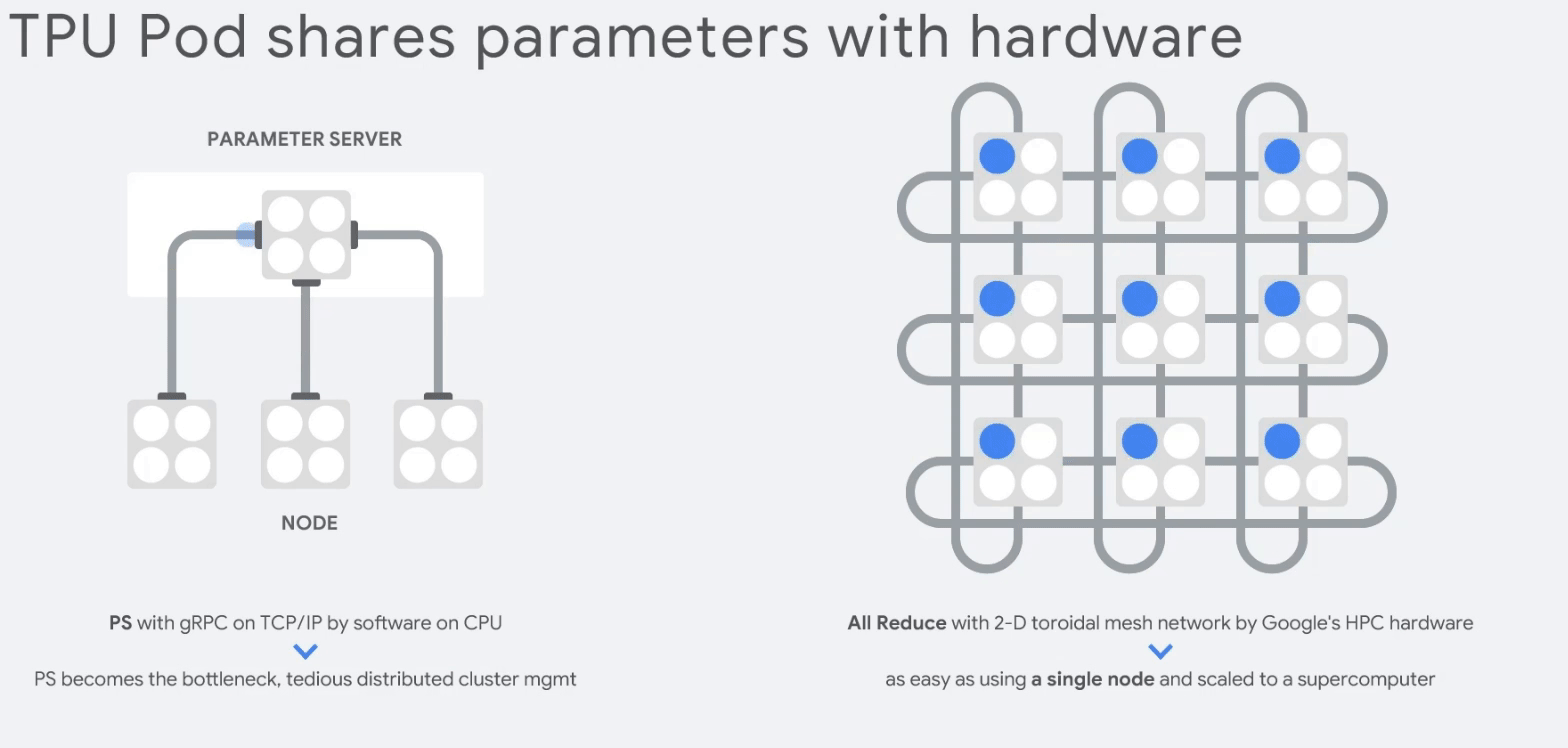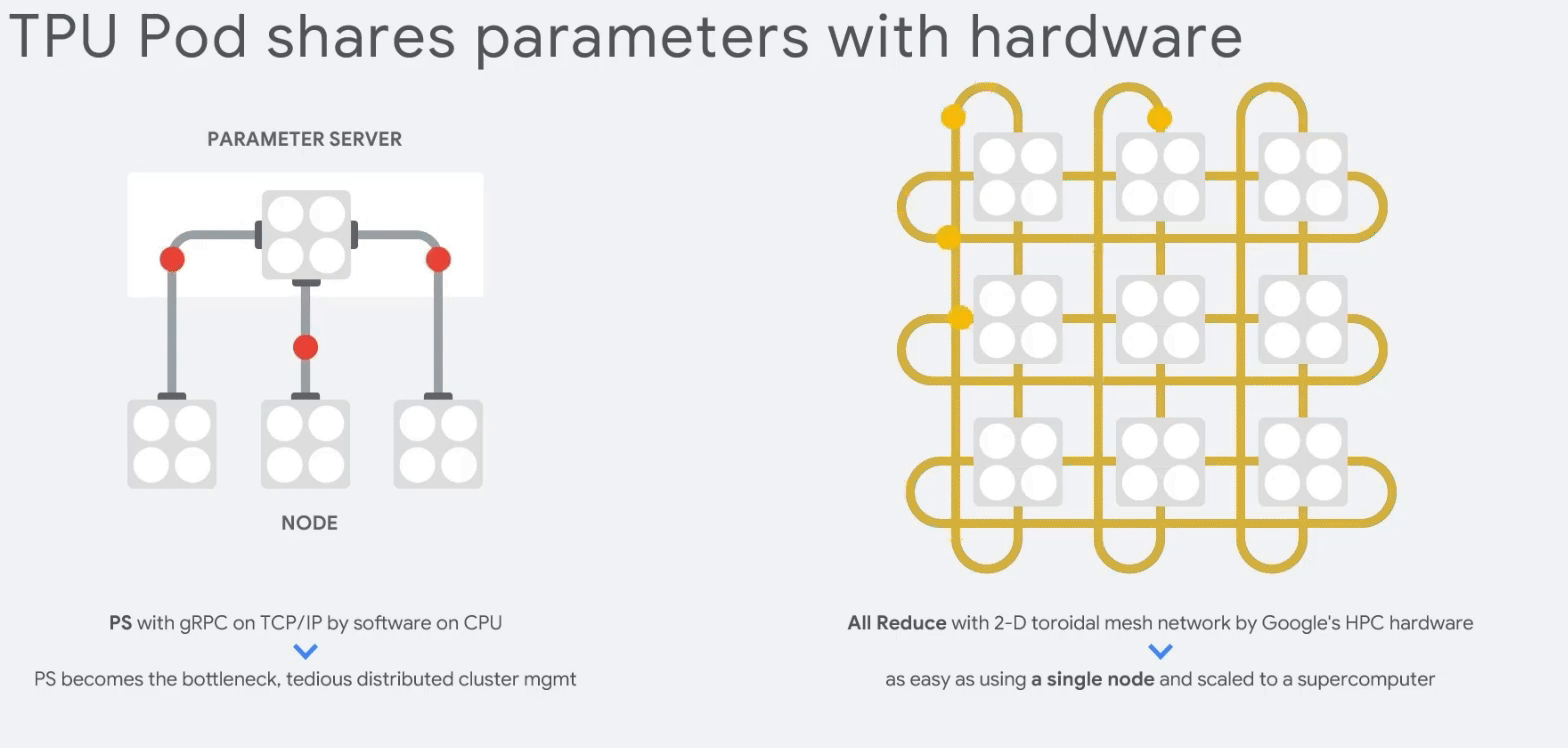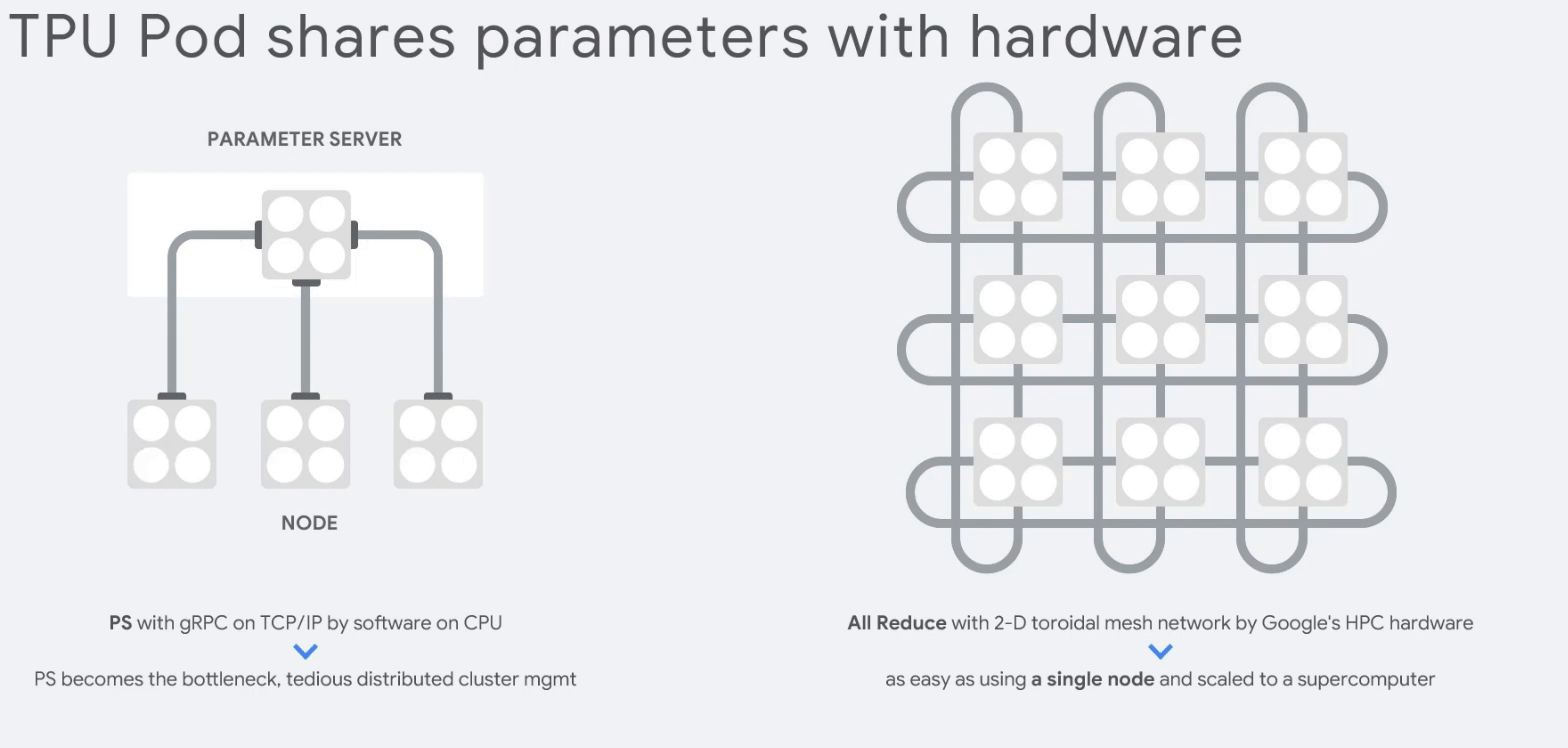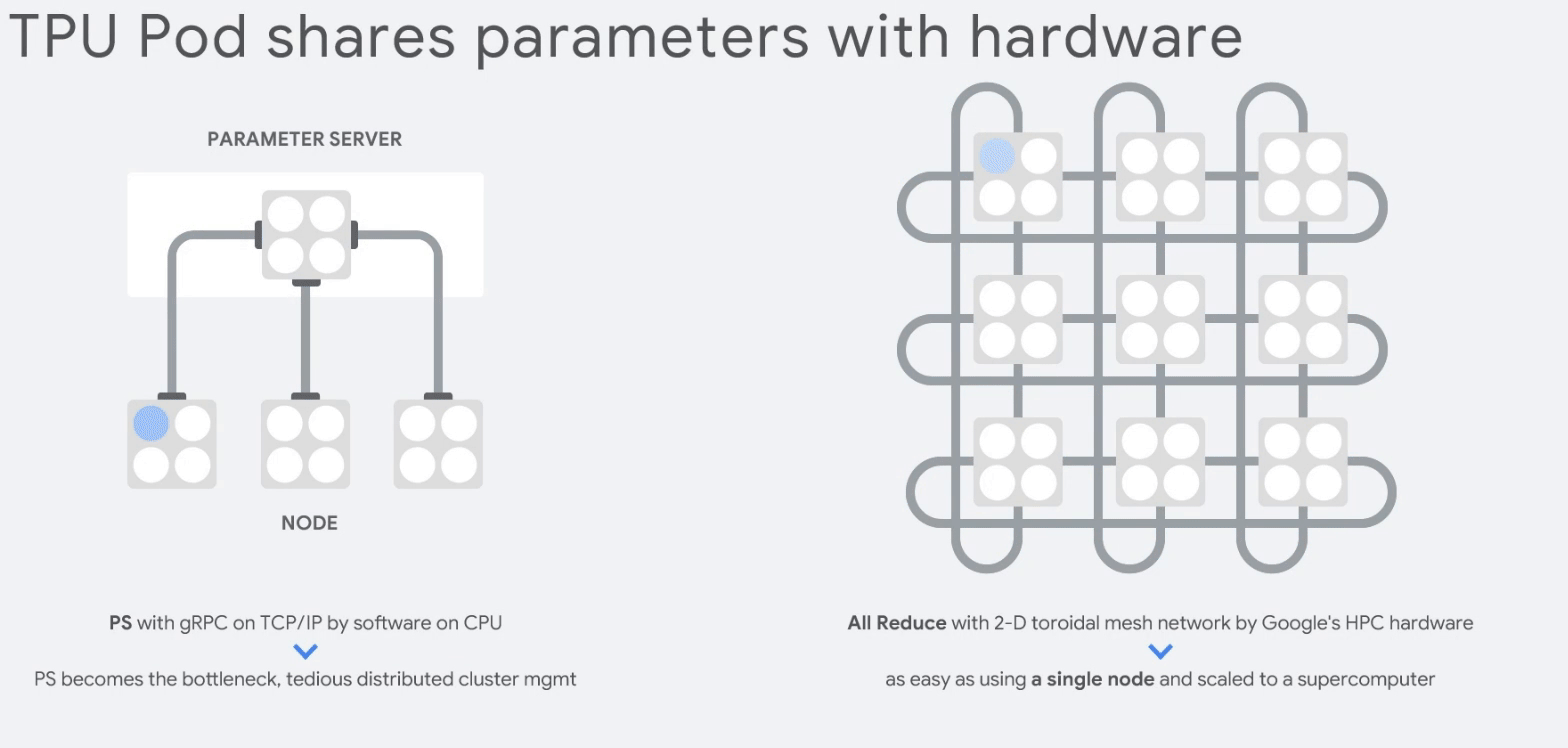
TPU Pod 15. 참고
첫 목표와 달리 본의 아니게 아래로 올수록 길어져버린 것 같다..ㅋㅋ
그래도 재미는 있었으니 됐지..
전반적으로 참고한 글 목록입니다.
- Overview of Modern Concurrency and Parallelism Concepts
- How to use Multithreading and Multiprocessing — A Beginner’s guide to parallel and concurrent programming
- Concepts: Concurrency
- Concurrency, multi-threading and parallel programming concepts
- Boost application performance using asynchronous I/O
- Preemptive Vs Non Preemptive and Multitasking vs Multithreading
- Cooperative vs. Preemptive: a quest to maximize concurrency power
- CPU Cores vs. Logical Processors & Threads
- Coroutine, Thread 와의 차이와 그 특징
- Multi-Threaded Programming Terminology - 2020
- Introduction to Parallel Computing Tutorial
댓글